


 雷达卡
雷达卡



数据库索引的深度解析与优化实践
引言:索引在数据库性能中的关键作用
作为提升数据检索效率的核心机制,数据库索引本质上是一种将无序数据组织为可快速访问路径的底层结构。它类似于书籍的目录系统,能够避免对全表进行线性扫描,从而大幅缩短查询响应时间。
在处理海量数据时,未建立索引的查询往往需要执行全表扫描,其性能损耗可能高达百倍以上。而合理设计的索引则能将原本耗时数秒的操作压缩至毫秒级别。行业统计表明,在各类数据库性能问题中,约有60%可通过优化索引策略有效解决,其成本效益远优于硬件扩容等手段。
索引通过构建高效的数据映射关系,使查询复杂度从O(n)降低至O(log n),尤其是在百万级数据量下,B-Tree类索引展现出显著优势,成为支撑高并发应用的关键技术基础。
本文将围绕索引的实现原理、主要类型(如B-Tree、Hash、GiST等)、设计准则及实际调优方法展开系统阐述,帮助构建完整的理论与工程实践体系,为数据库性能优化提供科学指导。
B+树索引的工作机制详解
B+树是当前主流数据库广泛采用的索引结构,其核心优势在于稳定的I/O开销和高效的查询性能。该结构的特点是仅在叶子节点存储完整数据记录,并通过有序链表连接所有叶子节点;内部节点则只保存用于导航的索引键值,不包含实际数据。
查询过程从根节点开始,逐层比对关键字并定位子节点,最终抵达目标所在的叶子节点。这一路径遵循二分查找逻辑,确保每次查询所需的磁盘I/O次数等于树的高度,通常仅需3到4次即可完成,具有极高的稳定性。
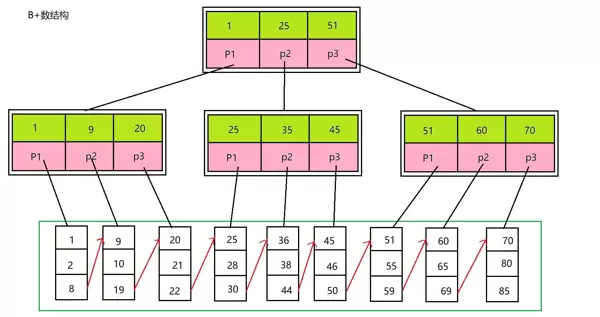
在插入操作中,当某个节点的关键字数量超出预设上限时,会触发分裂机制以维持树的平衡。具体而言,原节点按中间位置拆分为两个新节点,中间键值上升至父节点,同时保证左右子节点的容量均衡。此过程可能引发父节点的连锁分裂,极端情况下甚至导致根节点分裂并增加树高。但无论何种情况,B+树始终确保所有叶子节点处于同一层级,从而保障查询效率的一致性。
核心结论:B+树凭借其严格的平衡性和节点间的有序性,不仅实现了O(log n)的稳定查询时间复杂度,还天然支持范围扫描与排序操作,这两大特性使其成为数据库中最为核心的索引实现方式。
哈希索引的原理及其局限性分析
哈希索引基于哈希表结构实现,其查找流程如下:首先计算查询键的哈希值,确定对应的桶位置;若发生冲突,则依据特定策略进行处理。常见的冲突解决方法包括链地址法和开放定址法——前者使用链表存储同桶元素,虽占用较多内存但查询性能稳定;后者通过探测序列寻找空闲槽位,空间利用率更高,但易产生数据聚集现象。
然而,由于哈希函数本身的离散特性,哈希索引存在明显短板:无法支持范围查询或排序操作,仅适用于精确匹配场景。例如,执行“WHERE id = 100”这类等值条件可以高效命中索引,但“WHERE id BETWEEN 100 AND 200”则完全失效。
| 特性 | B+树索引 | 哈希索引 |
|---|---|---|
| 范围查询 | 支持,依赖有序叶子节点 | 不支持,仅限精确匹配 |
| 查找效率 | O(log n) | 理想O(1),冲突时退化 |
| 内存占用 | 较低(结构紧凑) | 较高(需预留冲突空间) |
| 有序性 | 支持(可通过中序遍历获取顺序) | 不支持(哈希值无序分布) |
聚簇索引与非聚簇索引的本质区别
两者最根本的区别体现在数据的物理存储方式以及访问路径的长短上。
InnoDB引擎使用的聚簇索引将主键索引与数据行统一存放在同一棵B+树中,叶子节点直接包含完整的数据记录。因此,通过主键查询可以直接获取数据,无需额外IO操作。
相比之下,MyISAM所采用的非聚簇索引在叶子节点中仅保存指向数据行的指针,查询时必须先读取索引,再根据指针定位磁盘位置读取真实数据,形成“回表”过程,带来额外开销。
这种结构差异决定了各自的适用场景:聚簇索引在频繁执行范围查询或大量读取操作的业务中表现更佳,因其减少了IO次数;而非聚簇索引由于索引与数据分离,在高频更新环境中能降低索引结构调整的成本,更适合写密集型应用。
此外,主键的选择直接影响聚簇索引的性能表现。使用自增主键可使新记录连续追加至B+树末尾,最大限度减少页分裂和空间碎片;而采用UUID等无序主键则会导致频繁的节点分裂和空间浪费,严重影响写入效率。
关键结论:聚簇索引适合读多写少的场景,利用数据与索引的物理聚合减少IO;非聚簇索引更适合写频繁的环境,依靠逻辑分离降低维护代价。
覆盖索引的优化原理与实战应用
在典型的订单查询中,执行语句 SELECT id, status FROM orders WHERE status = 'pending' 时,若仅创建单列索引 idx_status,则数据库仍需通过回表操作获取id字段,造成额外磁盘读取。
解决方案是创建联合索引 (status, id)。由于该索引的叶子节点已包含查询所需的所有字段,数据库可直接从中提取结果,无需访问主表,即实现“覆盖索引”。
通过 EXPLAIN 分析可见:优化前 Extra 字段显示 "Using index condition",表示需回表,平均IO次数约为8次;优化后变为 "Using index",表明命中覆盖索引,IO次数降至1次,整体性能提升接近87.5%。
优化要点:构建联合索引时应遵循“查询条件字段在前,返回字段在后”的原则,确保索引中涵盖全部被查询字段。对于高频执行的SQL语句,应优先评估是否可通过覆盖索引消除回表操作,尤其在高并发环境下,此举可显著减轻数据库的IO压力,提升整体吞吐能力。
在数据量较大的场景下,覆盖索引能够通过避免回表操作,将原本的随机 IO 转化为顺序 IO,从而显著提升查询性能。然而,在实际应用中需权衡索引的维护开销,防止因创建过多冗余的联合索引而增加写入成本。
联合索引设计策略与最左前缀原则
联合索引是基于多个列值组合构建的一种有序数据结构,其查询匹配过程严格遵循最左前缀原则。以 (a, b, c) 的联合索引为例,其匹配逻辑可简化为:从左至右依次比对查询条件,仅当条件满足 a=?、a=? AND b=? 或 a=? AND b=? AND c=? 时才能有效利用索引。若缺失左侧前缀(如仅使用 b=? 或 b=? AND c=?),则会导致索引无法命中。
列的排列顺序直接影响索引效率,核心优化策略是将选择性高的列置于前面。选择性的计算公式为:唯一值数量 / 总行数,取值范围为 (0,1],数值越接近 1 表示该列的区分度越高。例如,在用户表中,性别列的选择性通常较低(约为 0.02),而用户 ID 列则具有极高选择性(接近 0.98),因此应将用户 ID 放在联合索引的前列,以便快速过滤大量无关记录。
设计三原则如下:
- 根据查询频率排序,优先将高频用于过滤的列放在前面;
- 严格遵守最左前缀匹配规则,确保查询能正确命中索引;
- 借助选择性公式量化各列的重要性,科学决策列顺序。
合理的联合索引设计可显著减少回表次数。例如,(订单日期, 用户 ID) 这一组合索引能高效支持“查询 2023 年 10 月某用户的订单”这类场景;而若顺序颠倒为 (用户 ID, 订单日期),索引利用率可能下降超过 60%。
实战案例:索引优化分析
案例一:高并发商品查询系统的索引优化
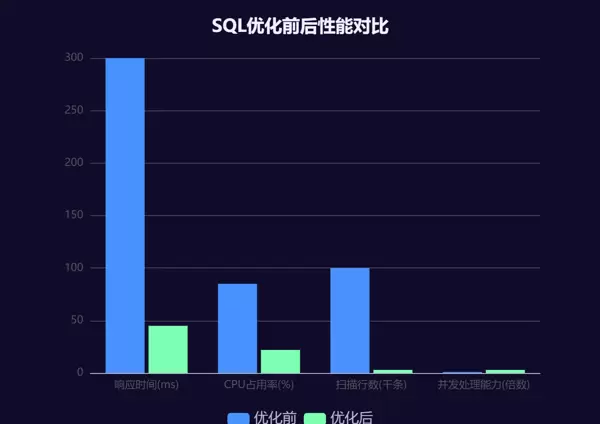
本案例针对一个日均处理千万级查询请求的商品检索系统,需支持按商品分类、价格区间及销量等多维度组合筛选。原始 SQL 查询由于缺乏合理索引设计,在执行计划中频繁出现 Using filesort 操作,导致平均响应时间超过 300ms,数据库 CPU 使用峰值达 85% 以上。
优化方案:建立 (category_id, price, sales) 联合索引。该设计符合最左前缀匹配原则,其中 category_id 实现主分类过滤,price 支持范围查找,sales 可用于排序优化,实现“索引覆盖 + 免排序”的双重优势。
索引创建语句如下:
CREATE INDEX idx_cat_price_sales ON products(category_id, price, sales);
优化后通过 EXPLAIN 分析可见:type 类型提升至 range,Extra 字段中的 Using filesort 消失,扫描行数由原来的 10 万以上降至 3000 以内。性能测试显示,平均响应时间缩短至 45ms,CPU 占用稳定在 22% 左右,系统并发处理能力提升 3 倍以上。
案例二:大数据量用户行为日志表的索引策略
面对日均写入 1000 万条记录的用户行为日志表,主要查询需求为按日期范围检索。未优化前,全表扫描使查询延迟随数据增长线性上升,且全局索引的维护严重拖累写入性能。
解决方案采用按天分区表与局部复合索引相结合的方式:以 log_date 字段进行表分区,使查询自动触发分区裁剪机制;在每个分区内创建 (user_id, event_type) 的局部索引,既保障了用户行为分析的查询效率,又将索引维护开销控制在单个分区内。
示例分区表创建语句:
CREATE TABLE user_behavior_log (
log_id BIGINT,
user_id INT,
event_type VARCHAR(50),
log_date DATE,
event_details JSON
) PARTITION BY RANGE (TO_DAYS(log_date)) (
PARTITION p20250101 VALUES LESS THAN (TO_DAYS('2025-01-02')),
PARTITION p20250102 VALUES LESS THAN (TO_DAYS('2025-01-03')),
...
);
CREATE INDEX idx_user_event ON user_behavior_log (user_id, event_type) LOCAL;执行计划分析表明,优化后查询仅扫描目标分区(如 p20250101),数据扫描量减少 99% 以上;同时写入性能提升约 40%,原因在于单个分区内的索引维护成本远低于全局索引。
关键优化点:分区裁剪依赖于查询条件中明确指定日期(如 WHERE log_date = '2025-01-01');局部索引要求 user_id 必须作为等值查询条件,以确保索引可以被高效扫描。
主流数据库索引实现差异对比
不同数据库在索引机制上存在显著差异。以下从五个核心维度对 MySQL InnoDB 与 PostgreSQL 进行对比:
| 对比维度 | MySQL InnoDB | PostgreSQL |
|---|---|---|
| 聚簇索引支持 | 支持(主键索引即为聚簇索引) | 不支持(采用堆表存储结构) |
| 索引类型 | B+树、哈希等基础索引 | 支持 GiST/GIN 等特殊索引(适用于全文搜索、地理信息等场景) |
| 并发更新性能 | 采用行级锁机制,存在一定锁竞争 | MVCC 实现减少锁竞争(多版本并发控制提升写性能) |
| 函数索引支持 | 需 5.7+ 版本通过虚拟列间接实现 | 原生支持(可直接基于函数表达式创建索引) |
| 索引碎片处理 | 使用 OPTIMIZE TABLE 命令 | 使用 REINDEX 命令(支持并发重建索引) |
关键差异总结:PostgreSQL 在特殊索引类型支持、并发写入性能以及函数索引的原生能力方面表现更优;而 MySQL InnoDB 的聚簇索引设计有助于降低磁盘 I/O。此外,两者在索引碎片管理上的机制不同,需采取相应的维护策略。
企业级索引优化最佳实践总结
核心原则:企业级索引优化必须兼顾查询性能与写入开销,结合数据特征和业务场景制定策略。以下方法均经过真实生产环境验证,可有效提升系统整体效率。
优先在高选择性列上创建索引
操作方法:通过统计字段的唯一值占比(即选择性)来判断是否适合作为索引列。选择性越高,索引过滤效果越好,建议优先为选择性大于 0.1 的列建立索引,避免在低区分度字段(如状态标志、性别等)上盲目建索引。
在数据库优化过程中,合理使用索引是提升查询性能的关键手段。对于选择性超过20%的列,应优先考虑建立索引。选择性的计算方式为:唯一值数量除以总行数。
高选择性的字段具备较强的过滤能力,能够在查询初期快速缩小数据范围,从而显著减少需要扫描的索引条目和数据页,提高检索效率。
例如,在一个电商订单表中,user_id 列的选择性达到35%,为其建立索引后,用户订单查询响应时间由原来的800ms下降至45ms;相比之下,status 列的选择性仅为8%,即使创建索引,性能提升也不足5%,效果不明显。
应避免在更新频率较高的列上创建索引,特别是日均修改次数超过1000次的字段,更不宜作为复合索引中的前置列。
原因在于,每次对数据行进行插入、更新或删除操作时,数据库都需要同步维护对应的索引结构(如B+树),导致额外的写入开销,即“写放大”现象,增加磁盘IO压力。
实际案例显示,某金融交易系统曾为 balance 字段(日均更新约10万次)建立了索引,移除该索引后,系统的写入吞吐量提升了42%,同时磁盘IO使用率下降了35%,整体性能得到明显改善。
设计复合索引时,需遵循“最左前缀匹配”原则,将具有最强过滤能力的列置于索引的左侧,而用于范围查询的列则应放在右侧,以最大化索引利用率。
以用户行为记录表为例,采用 (user_id, action_time) 的复合索引顺序,相比 (action_time, user_id),查询效率提升了3倍。这是因为 user_id 具有较高选择性,可先将数据集缩减90%以上,再在此基础上执行时间范围扫描,大大降低了后续操作的成本。
CREATE TABLE user_behavior_log (
log_id BIGINT,
user_id INT,
event_type VARCHAR(50),
log_date DATE,
event_details JSON
) PARTITION BY RANGE (TO_DAYS(log_date)) (
PARTITION p20250101 VALUES LESS THAN (TO_DAYS('2025-01-02')),
PARTITION p20250102 VALUES LESS THAN (TO_DAYS('2025-01-03')),
...
);
CREATE INDEX idx_user_event ON user_behavior_log (user_id, event_type) LOCAL;随着数据的持续增删改,索引页可能出现物理存储上的碎片化,影响读取效率。当检测到索引碎片率超过30%时,应及时进行整理。
推荐在业务低峰时段执行索引重建(REBUILD INDEX,建议使用Online模式)或重组(REORGANIZE INDEX),以恢复索引的物理连续性。
某政务信息系统在对高碎片化的索引执行重建操作后,平均查询响应时间缩短了28%,索引扫描涉及的数据页数量减少了40%,验证了定期维护的有效性。
[此处为图片4]需要注意的是,索引并非越多越好。生产环境中,建议单个数据表的索引数量控制在5到8个之间。可通过执行计划(EXPLAIN)定期分析各索引的实际使用情况,并清理过去30天内无访问记录的冗余索引,避免资源浪费和维护成本上升。

 京公网安备 11010802022788号
京公网安备 11010802022788号







