


 雷达卡
雷达卡



考察方向
在软件工程的案例分析题中,需求分析属于高频考点(☆☆☆☆),尤其侧重于结构化与面向对象两种方法体系的应用。其中,结构化需求分析以数据流图(DFD)为核心工具,而面向对象需求分析则主要使用UML建模语言进行表达。
案例通常结合具体业务场景,要求考生理解并分析系统功能,进而绘制或补充相应的模型图表,重点考查对系统边界、数据流动、处理逻辑及数据存储的理解能力。
需求分析 —— 结构化需求分析(SA)
1. 结构化需求分析概念
结构化需求分析是软件工程中经典的分析方法之一,与面向对象需求分析并列为两大主流方法论体系。其核心目标是通过建立系统化的模型,准确描述和定义用户对软件系统的功能性需求。
2. 结构化需求分析内容
1)功能模型
功能模型用于刻画系统的功能组成及其数据处理流程,主要采用数据流图(DFD)作为建模工具。该模型从数据流向和加工过程的角度出发,清晰展示数据如何被输入、变换并输出为有用信息。
- 典型元素:包括外部实体、加工、数据流、数据存储等。
- 关键作用:直观呈现系统内部各模块之间的交互关系以及数据的流转路径。
2)数据模型
数据模型关注系统中数据的组织结构,常使用实体联系图(ER图)进行建模。它由三部分构成:实体(E)、属性和联系(R)。
- 应用场景:多用于数据库设计阶段,帮助明确表结构及关联关系。
- 考试说明:在需求分析阶段仅作简要介绍,不深入细节。
3)行为模型
行为模型用于描述系统状态的动态变化过程,反映系统对外部事件的响应机制。
- 建模工具:常用状态转换图(STD)表示。
- 核心要素:包含初态、终态、事件触发条件及对应的行为动作。
- 实际案例:如酒店预订系统中房间的状态变迁:空闲 → 预定 → 入住,均由特定事件驱动。
- 建模价值:有助于理清复杂业务流程中的状态转移规则。
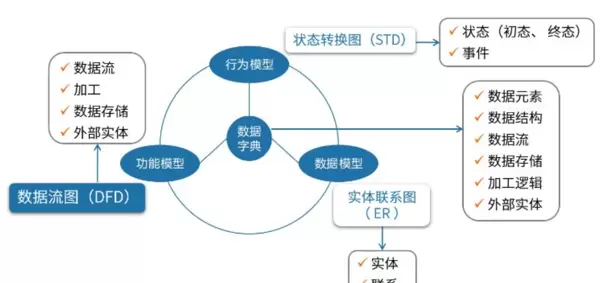
4)数据字典
数据字典是对系统中所有数据元素的详细定义文档,起到统一语义的作用。
- 定义内容:说明每个数据项的名称、类型、长度、取值范围、组成结构等。
- 核心作用:解释数据流图中各组件的具体含义,例如“用户信息”可能包含姓名、电话、地址等字段。
- 服务范围:同时支撑功能模型、数据模型和行为模型,是整个分析过程的基础参考。
- 类比理解:类似于传统字典对词语的释义,提供标准化的数据描述。
5)数据流图基本概念
数据流图(DFD)是结构化分析的核心图形工具,用于描绘系统内数据的流动与处理过程。
- 典型流程示例:培训部(外部实体)→ “安排课程”(加工)→ “课程”(数据存储),完整展示数据从输入到存储的过程。
- 关键区分:外部实体不属于系统本身(如学员使用系统但非组成部分),而数据存储属于系统内部资源。

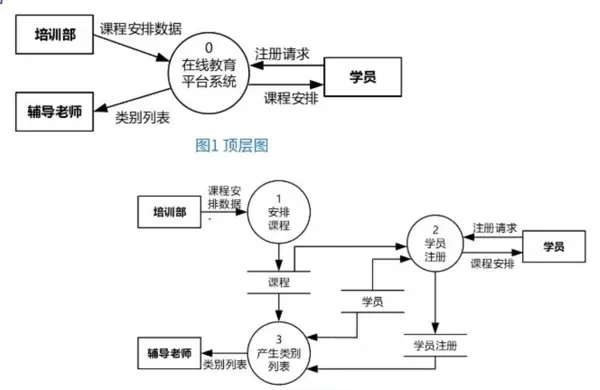
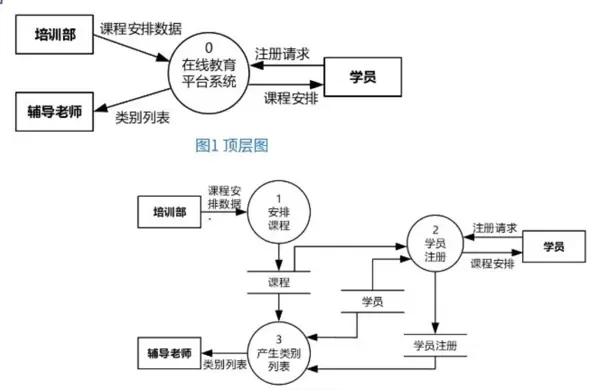
分层图
顶层图
顶层图是DFD的最高抽象层级,仅包含一个代表整个系统的椭圆(如“在线教育平台系统”)及其相关的外部实体。
- 特征:不展示内部结构,只体现系统与外界的主要交互关系。
- 作用:界定系统边界,明确系统与学员、培训部、辅导老师等外部角色的数据交换。
- 局限性:无法反映系统内部的功能分解与处理流程。
0层图
0层图是对顶层图中单一系统节点的首次功能分解。
- 核心变化:将整体系统拆分为多个主要加工模块,如“学员注册”、“安排课程”、“产生类别列表”等。
- 详细程度:展示各模块的输入/输出数据流,以及它们所访问的数据存储(如“课程”表)。
- 设计思想:遵循“自顶向下,逐步求精”的结构化开发原则,逐级细化系统功能。
数据流图平衡原则
平衡原则是解决DFD分层图中缺失或冗余数据流的关键技术手段,在考试中常用于判断和补充“掏空式”题目中的遗漏内容。
- 核心理念:父图与子图之间必须保持数据流的一致性,确保信息守恒。
- 应用方式:通过对比不同层级图的输入输出流,定位异常点并进行修正。

1) 父图与子图之间的平衡
父子图的关系具有相对性:顶层图为零层图的父图;若零层图中的某个加工进一步分解,则形成新的子图,原图为父图。
- 数据流守恒:如同用放大镜观察蚂蚁——放大后腿的数量不变。子图必须完整继承父图的所有输入和输出数据流,不得新增或遗漏。
- 实例说明:在线教育平台中,“注册请求”和“课程安排”等数据流在父图中存在,则其对应的子图也必须保留这些流。
- 验证方法:逐项核对顶层图与0层图之间的数据流是否一致,发现差异即为错误所在。
2)子图内平衡
子图内部需满足逻辑完整性,常见问题类型如下:
① 黑洞
特征:某加工只有输入数据流,却没有输出数据流。
本质问题:数据被“吞噬”,未产生应有的结果,违背功能实现的基本要求。
记忆口诀:“有去无回黑洞现”
示例:用户提交注册信息后,系统无任何反馈或存储操作。
② 奇迹
特征:加工没有任何输入却能生成输出数据流。
本质问题:违反“无中生有”的逻辑规律,数据来源不明。
典型案例:类似一家没有牛奶原料却能生产奶制品的造假工厂。
③ 灰洞
特征:虽有输入和输出,但两者之间缺乏合理的转换逻辑。
判断标准:输出数据不能由输入数据经合理加工得出。
典型示例:
- 面粉加工厂产出米粉(应以大米为原料)
- 使用化学合成物冒充乳制品
检查技巧:需仔细推敲加工过程的合理性,此类问题是隐蔽性最强的错误类型。
记忆要点:“输入输出要匹配,逻辑不通即灰洞”
综合应用策略:
考试时应优先排查黑洞和奇迹这类明显错误,再通过数据溯源法深入分析是否存在灰洞问题,避免被复杂的图形线条干扰判断。
解题技巧1
1)详细分析试题说明
题干文字描述与数据流图之间存在高度一致性。因为DFD本质上是将自然语言需求转化为可视化图形的结果,因此两者必须相互对应。
- 解题方法:逐句阅读题干,提取关键实体、数据流、加工和存储信息,并与图中元素一一匹配。
- 线索获取:题干中提到的操作流程、参与角色、数据传递等均可作为补充图形缺失部分的重要依据。
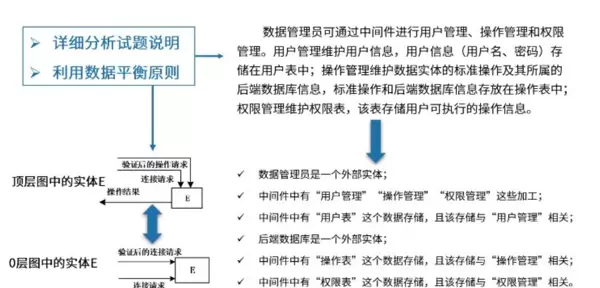
2)运用数据平衡原则解题
当遇到需要补充数据流的题目时,应首先利用父图与子图之间的平衡关系进行比对。
- 确认父图中存在的输入/输出流是否全部出现在子图中。
- 检查子图内部是否存在黑洞、奇迹或灰洞现象。
- 通过逆向追踪数据源头,验证每一条输出是否有合理的输入支撑。
3)中间件管理功能识别
在某些复杂系统中,存在起协调作用的中间处理模块(即中间件),负责数据转发、格式转换或权限控制等功能。
- 识别特征:连接多个子系统,接收多方数据并进行整合或路由。
- 常见表现:加工节点具有多个输入和多个输出,且不直接对应终端实体。
- 应对策略:结合上下文判断其是否承担调度、验证或分发职责。
解题技巧2
1)补充实体
外部实体指位于系统之外,但与系统进行数据交互的角色或系统。
- 判断依据:查看题干中提及的参与者(如管理员、客户、第三方接口等)是否已在图中标注。
- 遗漏情况:若某角色发出或接收数据流但未列入外部实体,则需补充。
2)补充存储
数据存储用于保存系统运行所需或产生的持久化数据(如数据库表、文件等)。
- 识别线索:当加工需要读取或写入历史数据时,应存在对应的数据存储。
- 常见遗漏:如“查询课程”操作未连接“课程”表,“学员注册”未写入“用户信息”库。
3)补充数据流(最难)
数据流表示数据在系统各组件间的传输路径,是最容易出错也是最难补充的部分。
- 解题步骤:
- 明确起点(外部实体或加工)和终点(加工或数据存储)。
- 根据题干描述还原操作流程(如“提交订单”、“生成报表”)。
- 判断是否有缺失的传递路径(如注册成功后未通知用户)。
- 难点解析:需综合理解业务逻辑、数据流向和加工职责,才能准确补全。
4)补充加工名
加工代表系统中对数据进行处理的功能单元。
- 命名规范:应使用动词短语,如“验证身份”、“计算费用”、“发送通知”等。
- 补充依据:根据输入输出数据流的内容反推其功能目的。
- 常见错误:使用名词命名(如“注册模块”)或过于笼统(如“处理”)。
在解答数据流图相关题目时,题干通常会提供详尽的系统描述信息,而对应的数据流图则存在多处空白需要补全。正确的方法是将题干内容与图形结构紧密结合,确保文字说明与图示表达之间保持一致性和对应性。
对于父图与子图之间的关系分析,需遵循数据平衡原则:顶层图和零层图之间的数据流必须一一匹配。例如,若顶层图显示有3条数据流(2条输入、1条输出),但零层图仅体现出2条输入流,则可判断其缺少“操作结果”这一输出数据流。这种层级间的对比有助于发现遗漏或多余的元素。
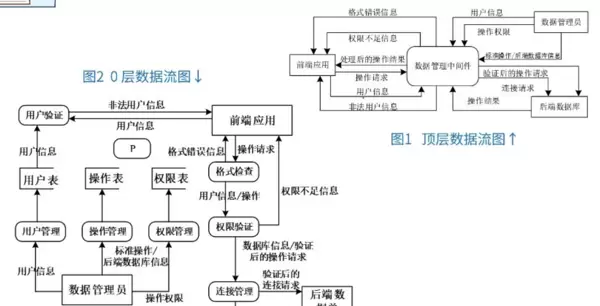
在完整性检查中,若出现某个加工点既无输入也无输出(如示例中的P点),则该加工显然不符合逻辑。因为任何有效的功能模块都应具备输入和输出,否则即为冗余设计,违背了数据流图的基本构建准则。
实际操作中,可通过逐条比对具体数据流来定位问题。例如,“权限不足信息”、“非法用户信息”、“格式错误信息”等在图中均已体现,唯独缺失“处理后的结果”,由此可迅速识别出数据流的断点所在。
中间件管理功能解析
用户管理:负责维护用户名、密码等用户基本信息,并将其存储于用户表中,该过程与“用户管理”这一加工环节直接关联。
操作管理:用于定义数据实体的标准操作及其对应的后端数据库信息,相关信息保存在操作表中,属于“操作管理”加工的职责范围。
权限管理:管理用户被授权执行的操作列表,数据存入权限表,与“权限管理”加工形成对应关系。
数据存储结构:中间件系统内包含三大核心数据存储单元——用户表、操作表和权限表,分别支撑上述三个管理功能模块的运行。
常见题型及解题策略
主要考察方向包括:补充实体、补充数据存储、补充数据流、补充加工名称四种类型。核心思路在于识别题目中缺失的元素类别,并采用针对性方法进行推导还原。
1)补充实体
识别特征:
- 人物角色:如客户、管理员、主管、经理、老师、学生等出现在系统外部并与之交互的角色。
- 外部系统:如银行系统、工资系统、后台数据库(在中间件开发场景下)等非本系统内部组件。
解题步骤:
- 从题干中提取所有可能作为实体的候选对象;
- 重点关注处于系统边界之外、与系统发生交互的对象;
- 结合三类典型实体特征进行验证确认。
记忆技巧:实体本质上是系统的“对话者”,既可以是自然人身份,也可以是第三方系统。
2)补充数据存储
关键词提示:凡含有“文件”、“表”、“库”、“清单”、“档案”等后缀的名词,往往指向数据存储元素。
关联性验证:每个数据存储必须与至少一个加工存在数据流入或流出的关系。例如,权限表必然与“权限管理”加工产生数据交互。
解题流程:
- 通读题干,圈定疑似存储名称的关键词;
- 查找与其相关的加工节点,确认其输入/输出数据流;
- 评估该存储在数据流图中的位置是否合理、是否存在缺失。
3)补充数据流(难度最高)
① 遵循数据平衡原则
- 层级一致性:顶层图与0层图之间的数据流数量和方向必须完全一致,不得有多余或遗漏。
- 加工校验:每一个加工都应同时拥有输入和输出数据流。
- 异常情况排查:仅存在输入无输出、仅有输出无输入、或输入无法生成对应输出的情形均为错误。
- 典型问题:加工无法依据所接收的输入数据生成应有的输出结果。
② 结合题干与图形匹配分析
- 逐句对照法:题干中的每一句话都应在数据流图中有对应的图形元素体现。
- 重点标注:标记出涉及实体和数据流的关键术语。
- 错误定位技巧:先建立题干要素与图中元素的映射关系表,再通过排除法精准锁定缺失或错误部分。
4)补充加工名称
命名规范:普遍采用“动词+名词”结构,例如“生成报告”、“批改作业”等;少数已固化术语如“物流跟踪”、“用户管理”除外。
推导方式:
- 明确该加工涉及的所有输入与输出数据流;
- 在题干相关语句中提取具有动作含义的短语;
- 检验该短语是否准确反映数据处理的核心行为。
功能本质:加工代表的是一个具体的数据处理模块,其名称应当清晰体现该模块所执行的主要操作动作。

 京公网安备 11010802022788号
京公网安备 11010802022788号







