


 雷达卡
雷达卡



BIOMOD2是一款基于R语言开发的软件包,专门用于构建和评估物种分布模型(SDMs)。该工具整合了多种统计建模与机器学习技术,例如广义线性模型(GLM)、广义加性模型(GAM)以及支持向量机(SVM)等,使研究人员能够预测物种在不同环境条件下的潜在地理分布格局。借助这一功能,用户可深入探讨气候变化、栖息地退化等因素对生物多样性的影响。
课程核心优势
- 理论与实践融合:课程注重理论讲解与动手实操的结合,既涵盖物种分布模型的核心原理,也包含大量实际操作环节,如利用BIOMOD2进行数据分析与建模练习。
- 多模型方法覆盖:内容涉及多种建模技术,包括传统统计模型与现代机器学习算法,帮助学员掌握多样化的建模手段,提升模型选择与应用的能力。
- 专题深度解析:围绕当前生态热点问题,如全球变暖与外来物种入侵,设置专题讨论和案例分析模块,展示物种分布模型在现实环境问题中的应用价值。
- 跨学科能力培养:不仅聚焦于生态模型构建,还强化数据科学技能训练,涵盖数据预处理、统计推断及结果可视化等内容,助力科研人员适应数据驱动的研究趋势。
第一章:引言与基础理论
课程概览:介绍课程目标、整体流程及预期学习成果。
生态模型基础知识:阐述生态模型的基本概念,并强调物种分布模型(SDMs)在生态学研究中的关键作用。
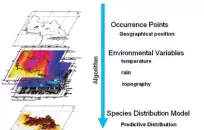
biomod2功能解析:回顾biomod2的发展历程,梳理其主要功能与技术特点。
R语言核心工具入门:介绍R语言在数据读写、科学计算、空间数据分析及图形可视化方面的基本操作与常用函数。
第二章:数据获取与前期处理
地球科学数据类型概述:讲解常见数据来源及其特征,主要包括:
- 物种观测记录数据;
- 环境变量数据(包括地面监测数据与遥感影像数据)。
基于R语言的数据预处理流程:
- 数据提取:根据研究需求,实现多源数据的批量获取与裁剪;
- 数据清洗:介绍数据去噪、缺失值处理与异常值识别的基本原则与方法;
- 特征变量筛选:运用相关性检验、主成分分析(PCA)等手段,挑选出最具代表性的环境因子,以优化模型输入。
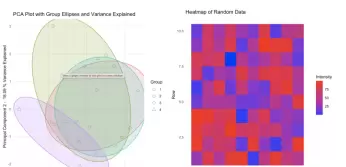
第三章:模型构建与性能评估
机器学习基础与R语言实现:
- 讲解机器学习的基本思想与发展脉络;
- 介绍主流算法类别及其典型工作流程。
以最大熵模型(MaxEnt)为例,演示如何使用单一机器学习算法模拟物种分布特征。

biomod2程序包详解与操作实践:说明其设计架构与核心模块,并指导用户完成首个物种分布模型的搭建,包括模型类型选定与参数设定。
模型评估策略:采用ROC曲线、AUC指标等量化方法,评估模型的预测精度与稳定性。
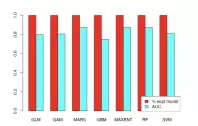
第四章:模型优化与集成建模
典型算法参数调优:针对随机森林、最大熵等常用算法,开展超参数调整实验,以提升模型表现。
多模型集成技术:通过组合多个独立模型的输出结果,增强预测的一致性与可靠性。
物种分布预测应用:分别基于单个模型与集成模型,预测物种在未来气候情景下的潜在分布范围。
实战训练环节:学员可使用提供的示例数据或自带数据集,尝试完成多模型集成的全流程操作。
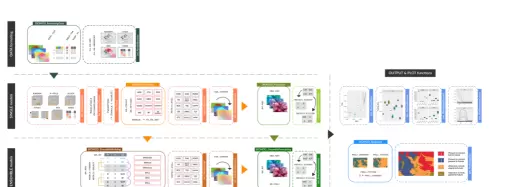
第五章:结果解读与案例应用
结果综合分析:解析模型输出结果,探讨物种分布格局、关键环境驱动因子及其对未来变化的响应特征。
科学图表制作:学习生成栅格地图、柱状图、降维可视化图等多种专业图形,用于成果展示。
案例研究模块:通过真实研究案例,展示如何将所学知识应用于实际生态问题的分析中。
课程总结:系统回顾各章节重点内容,探讨如何将掌握的技术有效迁移至后续科研项目中。

 京公网安备 11010802022788号
京公网安备 11010802022788号







