


 雷达卡
雷达卡



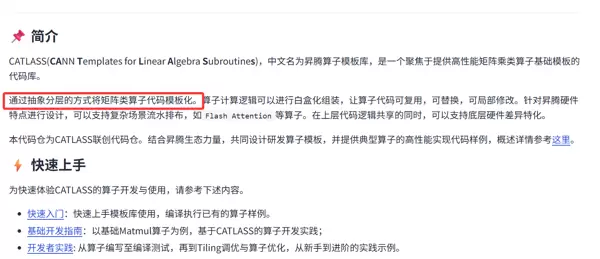
前言
在昇腾AI处理器的算子开发中,Catlass的引入标志着一次重要的技术跃迁。它不再要求开发者完全依赖Ascend C从零实现复杂的矩阵运算逻辑,而是提供了一套基于模板元编程的高效算子开发模式。
本文将深入解析Catlass的核心架构与设计思想,帮助开发者掌握其编程范式,快速构建高性能自定义算子。
1. Catlass的设计理念
Catlass全称为CANN Templates for Linear Algebra Subroutines,其设计借鉴了NVIDIA CUTLASS的思想,但针对昇腾AI Core特有的Cube+Vector+Scalar硬件结构进行了深度优化和重构。
它的核心设计理念可归纳为三个关键词:分层、解耦与白盒化。
- 分层(Layered):将完整的算子计算流程划分为多个抽象层级,覆盖从全局任务调度到单条指令执行的全过程。
- 解耦(Decoupled):将算法逻辑(如GEMM)与硬件适配策略(如分块、流水线)分离,提升代码复用性与灵活性。
- 白盒化(White-box):不同于传统闭源库,Catlass以开源模板形式呈现,开发者可通过特化模板参数深度定制内部行为,实现“算子级魔改”。
2. 四层抽象模型解析
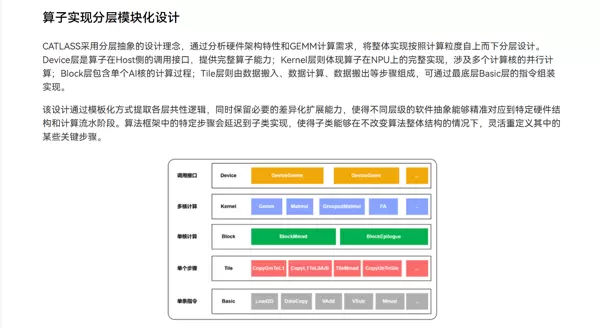
Catlass采用自顶向下的四层抽象结构,是理解其代码组织方式的关键所在。
2.1 Device 层(主机端视角)
作为Host侧的控制入口,该层主要负责与上层框架交互及整体资源协调。
核心功能包括:
- Tiling 策略计算:结合输入张量形状与硬件参数(如AI Core数量、L2缓存大小),确定最优数据分块方案。
- Workspace 管理:在NPU上分配必要的临时显存空间。
- Kernel 启动调度:将计算任务分发至多个AI Core并启动执行。
2.2 Kernel 层(集群/网格视图)
此层运行于NPU侧,是整个计算网格的入口函数,描述了跨AI Core的并行计算逻辑。
编程特征:
- 多核并行处理:通过获取当前核ID,动态计算各自的数据偏移位置。
GetBlockIdx()- 主循环结构:通常包含一个迭代处理大矩阵切片(Tiles)的主循环,驱动整体计算流程。
2.3 Block 层(CTA/核心视图)
聚焦于单个AI Core内的执行逻辑,是性能调优的核心区域。
关键技术机制:
- 三级流水线编排:利用Ascend C提供的机制,实现CopyIn(加载)、Compute(计算)、CopyOut(回写)的重叠执行。
TQue- 双缓冲技术(乒乓操作):当Cube单元处理Buffer A时,Vector单元预取下一批数据至Buffer B,隐藏内存延迟。
- GEMM 抽象封装:将矩阵乘累加操作抽象为专用对象,便于统一调度与优化。
BlockMmad2.4 Tile 层(Warp/指令级视图)
处于最底层,直接映射到硬件ISA指令,定义微内核级别的原子操作。
操作粒度涵盖:
- Load:从全局内存(GM)搬移到局部内存(L1/L0)。
- Math:调用特定指令完成 $$16 \times 16 \times 1$$ 的分形矩阵乘法运算。
Mmad- Store:将计算结果写回全局内存。
整体算子的分层结构示意图如下:
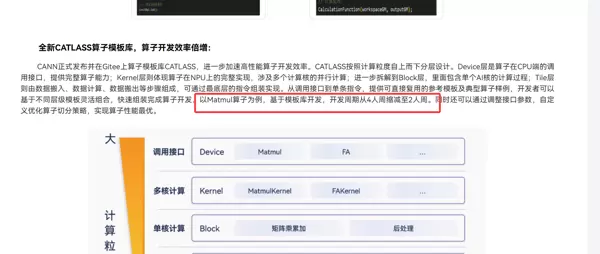
3. 核心机制:基于策略的模板设计(Policy-Based Design)
Catlass广泛运用C++模板机制实现策略模式,使开发者无需修改核心逻辑,仅通过调整模板参数即可改变算子行为。
3.1 调度策略(Dispatch Policy)
在GEMM模板中,调度策略决定数据如何在不同AI Core间划分。
- RowParallel:按行分割,适用于M维度较大的场景。
- ColParallel:按列分割,适合N维度较大的情况。
- BlockSwizzle:对Core ID进行重映射(Swizzle),优化L2 Cache命中率,降低跨核内存争抢。
DispatchPolicy3.2 分块策略(Tiling Policy)
Tiling是性能优化的关键环节。Catlass允许通过模板参数灵活配置以下参数:
- 分块大小:
—— M轴分块尺寸BlockM
—— N轴分块尺寸BlockN
—— K轴分块尺寸BlockK
此外,结合自动调优工具:
msTuner可实现Tiling参数组合的自动搜索与性能寻优。
4. 实战示例:构建Matmul算子
基于上述四层模型与策略机制,开发者可以系统性地构建一个高效的矩阵乘法算子,充分发挥昇腾AI Core的计算潜力。
在 Catlass 中,构建一个高性能 Matmul 算子的过程如同搭建积木一般直观且高效。
步骤 1:定义配置 (Traits)
首先需要明确算子的核心属性与执行策略,这是整个实现的基础。通过合理配置 Traits,可以灵活控制数据类型、分块大小、流水线阶段等关键参数。
// 伪代码示例,展示 Catlass 风格的配置定义
using MyMatmulPolicy = catlass::gemm::MatmulPolicy<
catlass::gemm::MatmulShape<256, 128, 64>, // Block 大小: M, N, K
catlass::gemm::Layout<catlass::RowMajor, catlass::ColMajor>, // 内存布局
float, // 输入类型
float // 输出类型
>;步骤 2:实例化 Kernel 模板
基于已定义的配置,调用预设的 Kernel 模板进行实例化。该模板封装了底层硬件交互逻辑,开发者只需传入合适的参数即可生成目标算子。
GemmKernel// 实例化 Kernel
using MyGemmKernel = catlass::gemm::GemmKernel<MyMatmulPolicy>;
// 在 Device 代码中调用
extern "C" __global__ void my_matmul_kernel(...) {
MyGemmKernel kernel;
kernel.Run(args); // 自动处理 CopyIn -> Compute -> CopyOut 流水线
}步骤 3:流水线优化 (Pipeline)
Catlass 的模板内部集成了 Ascend C 的完整流水线机制,自动协调多个计算与内存传输阶段:
- Stage 1:将数据从 Global Memory 搬运至 Local L1 缓存,使用 DMA 实现高效异步传输。
- Stage 2:进一步将数据从 Local L1 传送到 Local L0,利用 DataMove 指令提升访存效率。
- Stage 3:在 Cube Unit 上执行核心矩阵乘法计算,充分发挥硬件并行能力。
- Stage 4:完成计算后,将结果回写到输出内存区域。
大多数场景下,开发者无需手动编写复杂的同步控制代码,除非涉及极端定制化需求。
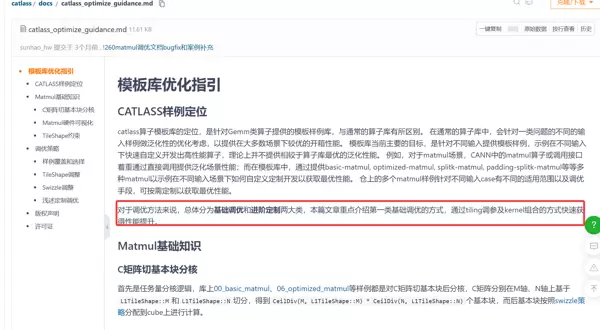
5. Catlass 引发的开发变革
相较于直接采用 Ascend C 手动编写算子,Catlass 在多个维度带来了显著提升:
开发效率倍增
典型案例显示,Matmul 类算子的开发周期由原来的 4 人周 缩短至仅需 2 人周。超过 50% 的代码量被消除,大量重复性的流水线管理代码已被高度抽象并内置于模板中。
性能下限高
模板库融合了华为专家团队长期积累的最佳实践(Best Practices),默认集成 Double Buffering、Swizzle 等高级优化技术。即使经验较少的开发者也能轻松写出接近最优性能的算子。
易于维护与扩展
分层清晰的架构设计使得问题定位更加高效。当平台引入新硬件特性(例如新一代 Cube 单元)时,通常只需更新底层模板实现,上层业务逻辑可保持不变,极大增强了系统的可延续性。
6. 总结
Catlass 不只是一个简单的代码库,它代表了一种面向未来的昇腾算子开发标准。借助模板元编程技术,Catlass 成功实现了高性能与灵活性之间的理想平衡。对于致力于在昇腾平台上开展高性能计算创新的开发者而言,掌握 Catlass 的编程范式已成为迈向高阶开发不可或缺的关键一步。

 京公网安备 11010802022788号
京公网安备 11010802022788号







