


 雷达卡
雷达卡



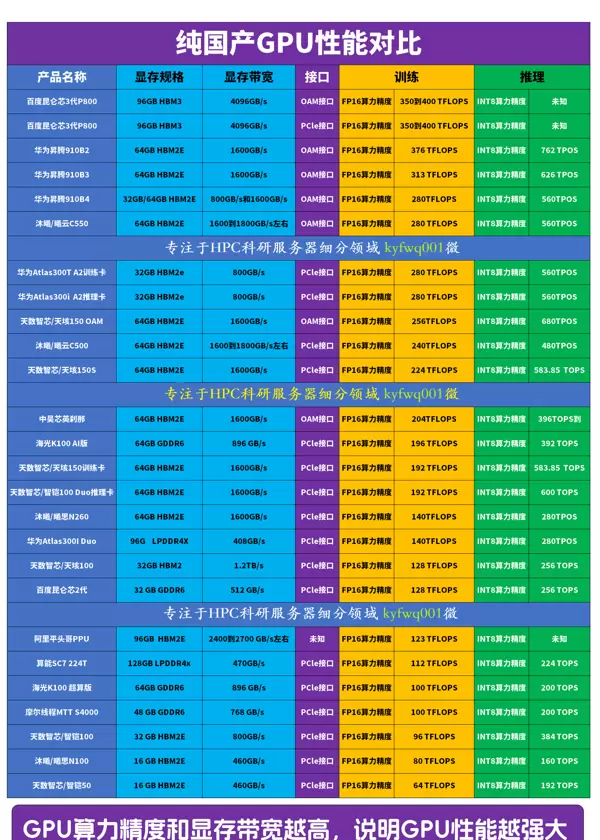
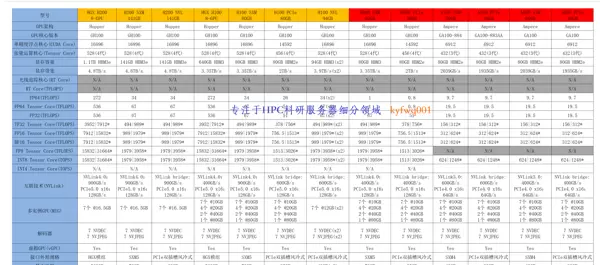
在AI时代,GPU作为核心的“算力心脏”,正以中国速度在科创板展现出强劲的发展势头。
2025年12月5日,摩尔线程(688795.SH)正式登陆科创板。上市首日开盘价较114.28元/股的发行价飙升468.78%。此前两天,即12月3日,沐曦股份(688802.SH)宣布其IPO询价结果落地,最终确定发行价格为104.66元/股,成为当年科创板罕见的“百元新股”之一。

国产GPU四小龙齐聚资本市场
除已上市的摩尔线程与即将挂牌的沐曦股份外,“国产GPU四小龙”中的燧原科技和壁仞科技也均已进入上市辅导阶段,计划登陆科创板。针对当前进展,壁仞科技方面回应称:“目前暂无对外披露的信息。”业内专业人士指出,只要未发布终止A股上市的官方公告,其辅导工作仍在持续推进。截至发稿前,燧原科技未就记者关于上市动态及其他相关问题作出回应。
电子创新网创始人张国斌分析指出:“摩尔线程是全能型选手,产品覆盖桌面图形与AI计算领域,布局广泛;而沐曦股份则聚焦于大模型训练,在性能和性价比上更具优势。”他进一步表示,“这两家头部企业在2025年12月相继登陆科创板,标志着国产GPU行业迈入‘资本+技术’双轮驱动的新阶段,对整个产业链形成积极拉动作用。”
长期关注半导体行业的资深观察者黄烨锋认为:“这几家企业的核心方向高度一致——主攻AI大芯片、布局云端算力。唯一的差异可能在于是否涉足图形渲染。”他还提到,目前“四小龙”均在推进万卡级集群建设,今年国产GPU的一个显著共性就是全面发力超节点架构。
从低谷到曙光:国产GPU五年突围之路
自2012年起,GPU因适配深度学习算法而迅速崛起,成为AI芯片的核心支撑力量。据公开资料,英伟达CEO黄仁勋多次提及,2012年AlexNet模型的出现是深度学习的关键转折点,大幅提升了图像识别精度,并推动了该技术的广泛应用。在此过程中,英伟达凭借GPU强大的并行计算能力占据了主导地位。
长期以来,全球GPU市场由英伟达与AMD垄断,中国市场尤其依赖进口产品。尽管如此,国内仍涌现出一批代表性企业,如寒武纪(688256.SH)、海光信息(688041.SH)、景嘉微(300474.SZ)等上市公司,以及被合称为“国产GPU四小龙”的摩尔线程、沐曦股份、壁仞科技和燧原科技。
这些新兴企业大多成立于2020年前后,正值美国将华为等中国企业列入实体清单之际,国产替代需求快速释放。一批曾在海外GPU巨头任职的技术人才归国创业,同时吸引红杉中国、高瓴资本等顶级投资机构纷纷入场。
然而发展并非一帆风顺。2022年成为行业至暗时刻:企业持续亏损、资本市场情绪低迷、股价下挫、融资困难,部分未上市企业甚至遭遇资本撤离。雪上加霜的是,2023年10月,美国升级出口管制措施,将壁仞科技与摩尔线程纳入实体清单,导致供应链压力进一步加剧。
转机出现在2024年。随着AI算力需求爆发与关键技术突破形成共振,行业迎来拐点:
- 寒武纪推出采用7nm工艺的思元590芯片,推理能效比肩国际旗舰水平,兼容主流国产大模型。全年营收同比增长65%,并在2025年第三季度实现历史性首次盈利,前三季度总营收同比激增2386%。
- 摩尔线程2024年实现营收4.38亿元,同比增长253.65%,其中AI智算产品收入达3.36亿元,占总营收比重高达77.63%。
- 沐曦股份同期营收达到7.43亿元,同比增长约1300%,显示出强劲的商业化落地能力。
从2020年的创业热潮,历经2022年的寒冬,再到2024年开始显现增长动能,国产GPU用五年时间走出了一条充满挑战却逐步明朗的发展路径,逐渐成长为我国AI算力自主化的重要支柱。
张国斌展望未来指出:“短期内,国产GPU有望在2026年将国内AI芯片自给率由30%提升至50%以上,直接带动超过200亿元的晶圆制造、封装测试及设备采购订单。中长期来看,若能建立起资本投入与技术研发的良性循环,预计到2028年前后,国产GPU可在推理端实现真正意义上的崛起,并反向推动本土形成涵盖‘EDA—IP—晶圆—封装—设备—材料’的完整生态体系,完成从单点突破到系统级自主的跃迁。”
不过他也强调,当前国产GPU在制造工艺、软件生态、客户粘性及产业标准等方面,仍与英伟达存在明显差距,未来发展仍需克服多重挑战。
密集冲刺资本市场,AI算力集群实现突破
作为AI芯片中占比最高的品类,GPU赛道在今年迎来了企业上市的高峰期。
以摩尔线程为例,其IPO进程创下三项纪录:
- 从2025年6月30日获受理至9月26日过会,仅耗时88天,成为科创板开板六年来审核速度最快的企业;
- 拟募集资金达80亿元,创下当年科创板在审项目募资规模之最;
- 最终发行价定格为114.28元/股,不仅是当年唯一一只“百元新股”,也是发行定价最高的新股之一。
与此同时,资本市场的步伐并未停歇。证监会官网信息显示,2025年11月1日,燧原科技再次向上海证监局提交辅导备案登记,重启上市进程。此外,具备兆芯生态背景的格兰菲,以及专注于视频处理与AI计算融合的瀚博半导体,目前也都处于上市辅导阶段,蓄势待发。
近年来,关于AI泡沫的讨论逐渐升温,即便英伟达刚刚发布了超出预期的财报,仍难逃投资人的质疑。尤其在谷歌TPU可能强势替代的舆论影响下,其股价也出现明显回调。然而,摩根士丹利基于对亚洲市场的实地调研报告指出,客户普遍反映“无法获得足够的英伟达产品”,这一现象有力支撑了市场对其新一代架构GPU(包括Blackwell和Rubin)在2026财年累计收入有望达到5000亿美元的乐观预期。
与此同时,我国正加快构建从底层芯片、AI服务器到AI算力集群的完整产业链布局,产业发展已由初期的迫切需求,逐步演变为具备全链条自主能力的战略趋势。
在AI算力集群领域,国内企业通过超节点技术实现了对海外同类系统的赶超。张国斌将“超节点”理念概括为:以集群规模弥补单卡算力短板,用系统工程突破工艺代差限制,以规模化部署换取整体性能提升。
今年世界人工智能大会上,上海仪电联合曦智科技、壁仞科技与中兴通讯共同发布了国内首个基于光互连与光交换技术的GPU超节点方案——光跃LightSphere X。 该方案利用光缆在远距离传输中的优势,实现交付与机柜布局的解耦。通过光互连技术扩展机柜数量,可根据大模型算力需求动态调整超节点规模,支持高达2000卡的部署能力。
此外,中科曙光近期推出了全球首个单机柜级640卡超节点scaleX640。该方案采用“一拖二”高密度架构设计,实现单机柜内640张加速卡的高速总线互联,综合算力成倍增长,算力密度相较传统方案提升达20倍。经过30天以上的连续稳定性测试验证,scaleX640可稳定支持十万卡级别的集群扩展部署。
9月,昆仑芯首次公开展示其自研超节点解决方案,支持单机柜灵活部署32至64张加速卡。结合DeepSeek V3/R1 PD分离推理架构的优化,其实现了单卡性能提升95%,单实例推理性能最高提升8倍,并已在百度内部实现大规模应用。
随着算力集群迈入“万卡协同”新阶段,华为在全连接大会上公布了其未来超节点演进路线图,计划于2026年第四季度正式推出Atlas 950超节点。据华为轮值董事长徐直军介绍:“Atlas 950将在未来多年保持全球最强算力超节点地位,在关键指标上全面领先业界主流产品。相较于英伟达预计明年下半年发布的NVL144,Atlas 950的规模达其56.8倍,总算力为6.7倍,内存容量提升至15倍(达1152TB),互联带宽更是高达62倍,达到16.3PB/s。即使面对英伟达规划于2027年推出的NVL576,Atlas 950依然在多项核心参数上保持领先。”
在AI服务器层面,联想集团与浪潮信息不仅在国内市场占据主导地位,国际市场份额和排名也在持续攀升。根据IDC发布的数据,2025年第一季度,联想集团服务器收入位居全球第三,同比增长高达74.8%;在中国AI云服务器市场的份额突破35%,稳居行业第一梯队。
聚焦芯片环节,沐曦股份首款通用GPU产品C600以全流程国产化为核心亮点,展现出替代英伟达H20的能力。根据该公司向交易所提交的回复函显示,其第三代高性能通用GPU芯片——曦云C700系列研发项目已于今年4月正式立项,目标对标英伟达H100。
同样在2025世界人工智能大会上,燧原科技发布最新一代训推一体产品“燧原L600”,适用于大模型训练与推理任务,原生支持FP8(8位浮点数)低精度计算,有效提升训练效率并降低运算成本。据悉,“燧原S60”已于2024年下半年进入量产阶段,当前出货量及订单总量已超过10万片。

 京公网安备 11010802022788号
京公网安备 11010802022788号







