


 雷达卡
雷达卡



线性回归与KNN算法的核心原理及实践应用
一、机器学习基础概念
作为人工智能的关键分支,机器学习通过从大量数据中进行学习和训练,使计算机系统具备预测未来趋势或做出决策的能力。通常情况下,数据量越大,模型的训练效果越理想。针对不同类型的数据特征和任务需求,需选择合适的数学建模方法以实现最优性能。
二、线性回归分析
2.1 相关关系与回归分析
在统计学中,变量之间的相关关系主要分为两类:
- 因果关系:适用于回归分析,强调一个变量(自变量)对另一个变量(因变量)的影响,必须明确区分原因与结果。
- 平行关系:适用于相关分析,仅反映两个变量间的协同变化趋势,不涉及因果判断,无需指定自变量与因变量。
2.2 一元线性回归模型
该模型的基本形式为:
y = β + βx + ε
其中:
- β 和 β 是待估计的模型参数,分别表示截距和斜率;
- ε 表示误差项,用于捕捉除输入变量外其他随机因素引起的波动。
2.3 误差项分析
误差项具有以下关键性质:
- 独立同分布:每个样本点的误差相互独立,并服从相同的概率分布;
- 高斯分布假设:误差期望值为0,方差恒定为σ;
- 不可忽略性:误差是建模过程中必然存在的部分,其特性直接影响参数估计的准确性。
2.4 参数估计方法
极大似然估计
该方法基于“所观测到的样本是最可能发生的事件”这一理念,通过构建似然函数并使其最大化来求解最优参数。
最小二乘法
目标是最小化预测值与真实值之间的平方误差总和,优化目标函数定义如下:
J(β) = (1/2) ∑i=1m (y(i) βTX(i))
2.5 模型评价指标
皮尔逊相关系数(r)
衡量两个变量之间线性相关程度的指标,计算公式为:
r = [∑(x x)(y )] / √[∑(x x) · ∑(y )]
判定系数 R(拟合优度)
取值范围为 [0,1],数值越接近1,说明模型对数据的解释能力越强,拟合效果越好。
三、K-近邻算法(KNN)
3.1 算法原理
KNN是一种典型的基于实例的学习算法。对于新输入的样本,算法会计算其与训练集中所有样本的距离,选取距离最近的k个邻居,根据这些邻居的类别标签进行投票,得票最多的类别即为该样本的预测结果。
3.2 距离度量
常用的相似性度量方式包括:
- 欧氏距离(对应p=2的闵可夫斯基距离);
- 曼哈顿距离(p=1);
- 闵可夫斯基距离:一种通用的距离公式,可通过调节参数p适应不同场景。
3.3 算法优缺点
优点:
- 逻辑清晰,易于理解与实现;
- 无需显式训练过程,属于懒惰学习;
- 对异常值具有一定的鲁棒性;
- 适合处理稀有类别分类问题。
缺点:
- 当训练集规模较大时,预测阶段计算开销显著增加;
- 在类别分布极度不平衡的情况下,分类效果可能下降。
四、实践案例
4.1 一元线性回归实现
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
data = pd.read_csv("data.csv")
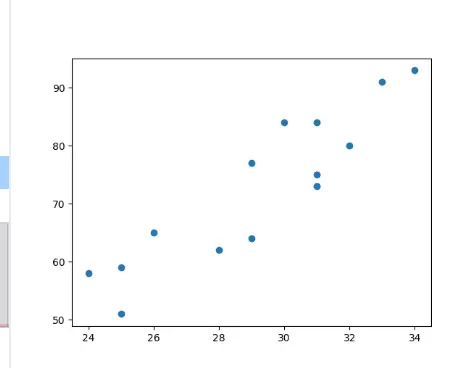
# 绘制散点图
plt.scatter(data.广告投入, data.销售额)
plt.show()
# 建立回归模型
lr = LinearRegression()
x = data[['广告投入']]
y = data[['销售额']]
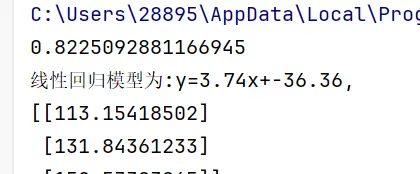
lr.fit(x, y) # 训练模型
# 模型检验
result = lr.predict(x)
score = lr.score(x, y)
a = round(lr.intercept_[0], 2) # 截距
b = round(lr.coef_[0][0], 2) # 斜率
print("线性回归模型为:y = {}x + {}.".format(b, a))
# 利用回归模型进行预测
predict = lr.predict([[40], [45], [50]])
print(predict)
4.2 KNN算法实现
import matplotlib.pyplot as plt
import numpy as np
# 读取数据
data = np.loadtxt('datingTestSet2.txt')
data_1 = data[data[:, -1] == 1]
data_2 = data[data[:, -1] == 2]
4.3 鸢尾花分类案例
结合KNN算法对鸢尾花数据集进行分类,利用特征空间中的邻近样本信息完成类别判定,验证算法在实际多分类任务中的有效性。
五、模型评价与优化
5.1 混淆矩阵
混淆矩阵是一种评估分类模型性能的重要工具,能够直观展示真实标签与预测结果之间的匹配情况,帮助分析准确率、召回率等关键指标,进而指导模型调优。
# KNN算法实现
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
# 加载数据
data = np.loadtxt('datingTestSet2.txt')
X = data[:, :-1] # 特征数据:除最后一列外的所有列
y = data[:, -1] # 标签数据:最后一列表示类别
# 构建KNN分类器,设置邻居数为5
neigh = KNeighborsClassifier(n_neighbors=5)
neigh.fit(X, y)
# 对单个样本进行预测
print(neigh.predict([[19739, 2.816960, 1.686219]]))
# 批量预测多个样本
predict_data = [
[9744, 11.440364, 0.760461],
[16191, 0.100000, 0.605619],
[42377, 6.519522, 1.058602],
[27353, 11.475155, 1.528626]
]
print("再次多人同时预测")
print(neigh.predict(predict_data))
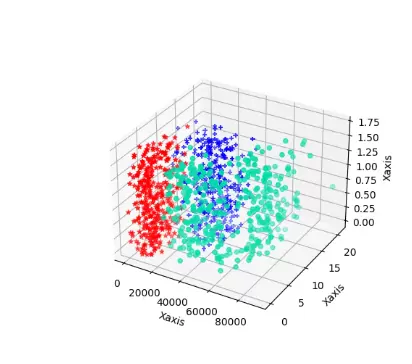 # 数据可视化:三维散点图展示三类数据分布
fig = plt.figure()
ax = plt.axes(projection="3d")
# 提取三类数据(根据标签值划分)
data_1 = data[data[:, -1] == 1]
data_2 = data[data[:, -1] == 2]
data_3 = data[data[:, -1] == 3]
# 绘制每一类的散点
ax.scatter(data_1[:, 0], data_1[:, 1], zs=data_1[:, 2], c="#00DDAA", marker="o", label="类别1")
ax.scatter(data_2[:, 0], data_2[:, 1], zs=data_2[:, 2], c="#FF5511", marker="^", label="类别2")
ax.scatter(data_3[:, 0], data_3[:, 1], zs=data_3[:, 2], c="#000011", marker="+", label="类别3")
# 设置坐标轴标签
ax.set(xlabel="Xaxes", ylabel="Yaxes", zlabel="Zaxes")
ax.legend()
plt.show()
# 数据可视化:三维散点图展示三类数据分布
fig = plt.figure()
ax = plt.axes(projection="3d")
# 提取三类数据(根据标签值划分)
data_1 = data[data[:, -1] == 1]
data_2 = data[data[:, -1] == 2]
data_3 = data[data[:, -1] == 3]
# 绘制每一类的散点
ax.scatter(data_1[:, 0], data_1[:, 1], zs=data_1[:, 2], c="#00DDAA", marker="o", label="类别1")
ax.scatter(data_2[:, 0], data_2[:, 1], zs=data_2[:, 2], c="#FF5511", marker="^", label="类别2")
ax.scatter(data_3[:, 0], data_3[:, 1], zs=data_3[:, 2], c="#000011", marker="+", label="类别3")
# 设置坐标轴标签
ax.set(xlabel="Xaxes", ylabel="Yaxes", zlabel="Zaxes")
ax.legend()
plt.show()

4.3 鸢尾花分类案例
import pandas as pd
# 读取训练集和测试集数据
train_data = pd.read_excel("鸢尾花训练数据.xlsx")
test_data = pd.read_excel("鸢尾花测试数据.xlsx")
# 提取训练集特征与标签
train_X = train_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
train_y = train_data['类型_num']
# 对训练集特征进行标准化处理
from sklearn.preprocessing import scale
data = pd.DataFrame()
data['萼片长标准化'] = scale(train_X['萼片长(cm)'])
data['萼片宽标准化'] = scale(train_X['萼片宽(cm)'])
data['花瓣长标准化'] = scale(train_X['花瓣长(cm)'])
data['花瓣宽标准化'] = scale(train_X['花瓣宽(cm)'])
# 训练KNN模型(k=5)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(train_X, train_y)
# 处理测试集数据
test_X = test_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
test_y = test_data['类型_num']
# 对测试集特征进行标准化
data_test = pd.DataFrame()
data_test['萼片长标准化'] = scale(test_X['萼片长(cm)'])
data_test['萼片宽标准化'] = scale(test_X['萼片宽(cm)'])
data_test['花瓣长标准化'] = scale(test_X['花瓣长(cm)'])
data_test['花瓣宽标准化'] = scale(test_X['花瓣宽(cm)'])
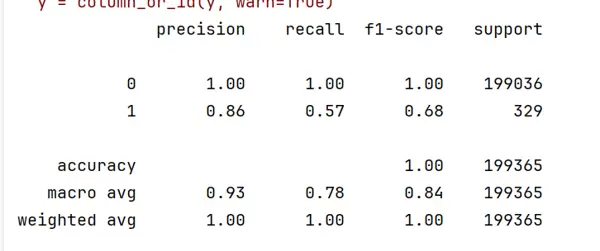
# 进行预测并计算准确率
test_predicted = knn.predict(test_X)
score = knn.score(test_X, test_y)
print(score)

五、模型评价与优化

 京公网安备 11010802022788号
京公网安备 11010802022788号







