


 雷达卡
雷达卡







简介
合成数据,顾名思义,是人工创建的数据,而非从真实世界采集。它外观与真实数据一致,同时规避了隐私问题和高昂的数据采集成本。你可以用它轻松测试软件、模型,模拟产品发布后的运行效果。
市面上已有 Faker、SDV、SynthCity 等库,甚至大语言模型(LLM)也被广泛用于生成合成数据,但本文的重点是不依赖这些外部库和AI工具。你将学会用原生Python代码实现相同效果,从而真正理解数据集的构造逻辑,以及偏差、错误是如何产生的。我们从简单的示例脚本开始,掌握基础后,你就能更从容地使用专业库。
1. 生成简单随机数据
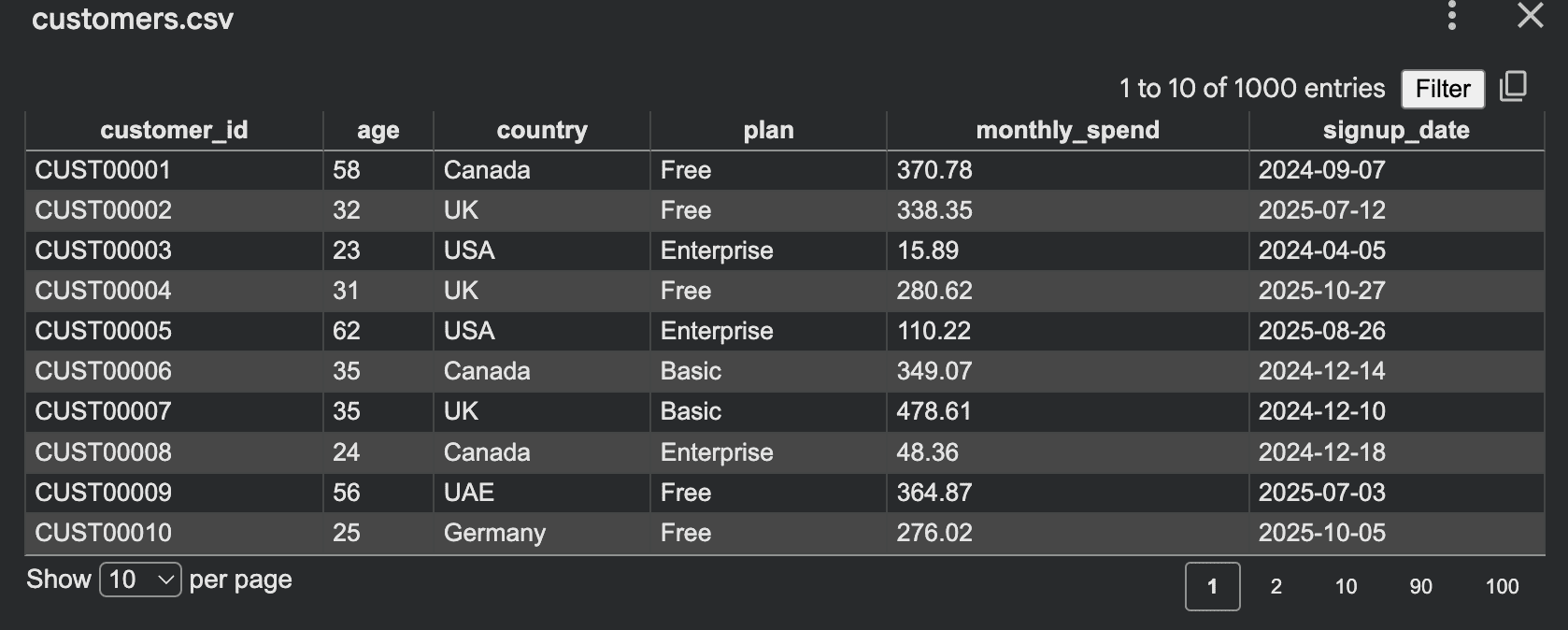
最基础的入门方式是生成表格数据。例如,你需要一份虚拟客户数据用于内部演示,可以运行脚本生成CSV格式数据:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
countries = ["Canada", "UK", "UAE", "Germany", "USA"]
plans = ["Free", "Basic", "Pro", "Enterprise"]
def random_signup_date():
start = datetime(2024, 1, 1)
end = datetime(2026, 1, 1)
delta_days = (end - start).days
return (start + timedelta(days=random.randint(0, delta_days))).date().isoformat()
rows = []
for i in range(1, 1001):
age = random.randint(18, 70)
country = random.choice(countries)
plan = random.choice(plans)
monthly_spend = round(random.uniform(0, 500), 2)
rows.append({
"customer_id": f"CUST{i:05d}",
"age": age,
"country": country,
"plan": plan,
"monthly_spend": monthly_spend,
"signup_date": random_signup_date()
})
with open("customers.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved customers.csv")
输出:
适用场景
前端演示
仪表盘测试
API开发
SQL学习
输入管道单元测试
核心缺陷
所有数据完全随机,不符合真实业务逻辑:
企业版用户可能只消费2美元,免费版用户却消费400美元
不同年龄、套餐的用户行为完全一致
无内在关联,数据显得生硬不自然
优化版:带业务规则的可控数据
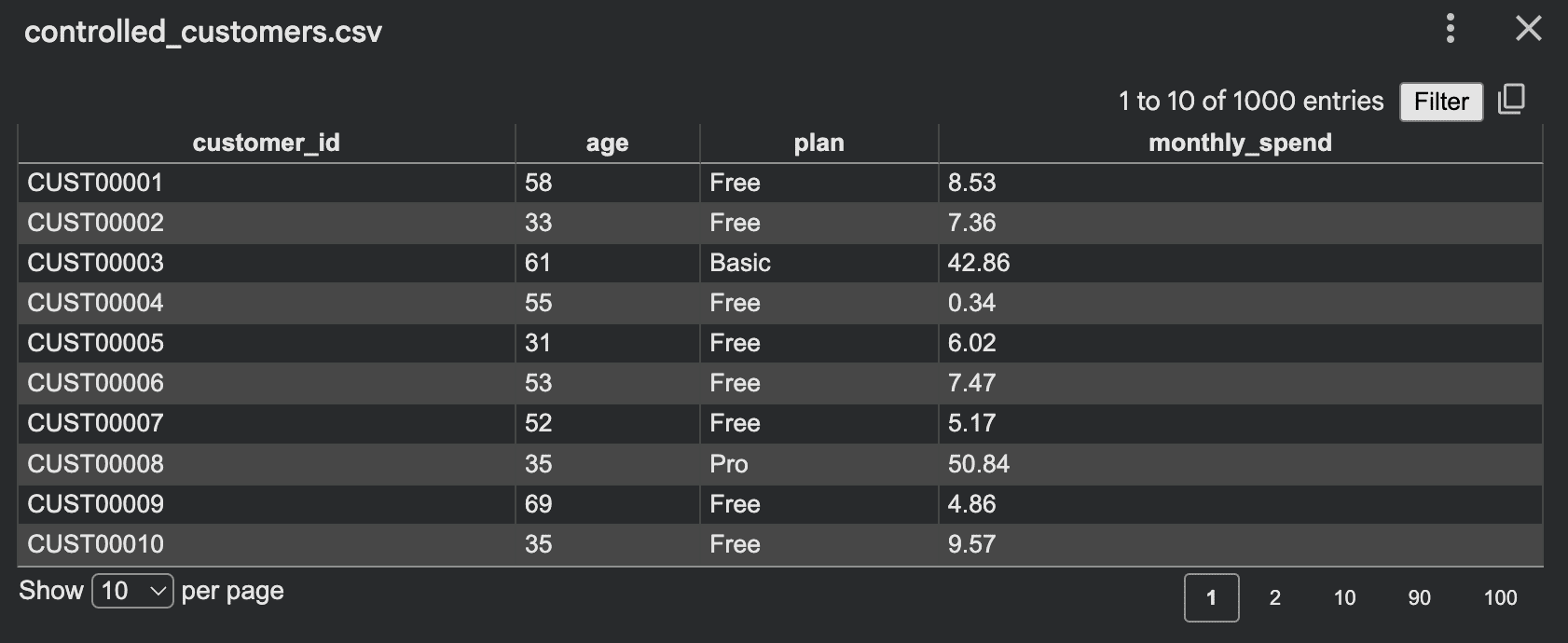
我们加入权重、条件逻辑、关联特征,让数据更真实:
import csv
import random
random.seed(42)
plans = ["Free", "Basic", "Pro", "Enterprise"]
# 按权重选择套餐
def choose_plan():
roll = random.random()
if roll < 0.45:
return "Free"
if roll < 0.75:
return "Basic"
if roll < 0.93:
return "Pro"
return "Enterprise"
# 根据年龄和套餐生成消费金额
def generate_spend(age, plan):
if plan == "Free":
base = random.uniform(0, 10)
elif plan == "Basic":
base = random.uniform(10, 60)
elif plan == "Pro":
base = random.uniform(50, 180)
else:
base = random.uniform(150, 500)
# 40岁以上用户消费增加15%
if age >= 40:
base *= 1.15
return round(base, 2)
rows = []
for i in range(1, 1001):
age = random.randint(18, 70)
plan = choose_plan()
spend = generate_spend(age, plan)
rows.append({
"customer_id": f"CUST{i:05d}",
"age": age,
"plan": plan,
"monthly_spend": spend
})
with open("controlled_customers.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved controlled_customers.csv")
输出:
有效控制手段
加权分类选择
符合现实的数值范围
列之间的条件逻辑
刻意加入稀有边界案例
低比例缺失值
关联特征(而非独立特征)
2. 基于流程模拟的合成数据
流程模拟是生成高真实感合成数据的最佳方式之一:不直接填充列,而是模拟真实业务流程。
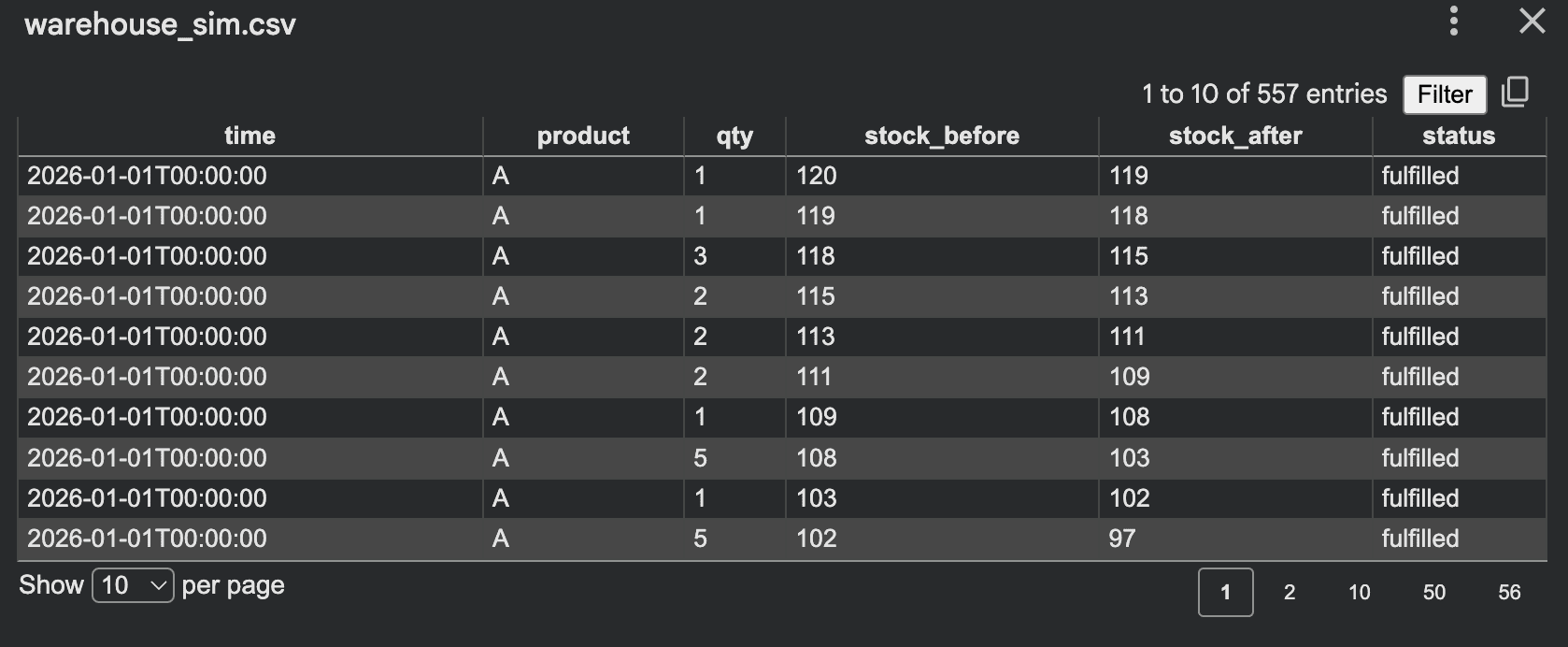
示例:小型仓库订单、库存、补货模拟:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
inventory = {"A": 120, "B": 80, "C": 50}
rows = []
current_time = datetime(2026, 1, 1)
# 模拟30天库存变化
for day in range(30):
for product in inventory:
daily_orders = random.randint(0, 12)
# 处理订单
for _ in range(daily_orders):
qty = random.randint(1, 5)
before = inventory[product]
if inventory[product] >= qty:
inventory[product] -= qty
status = "fulfilled"
else:
status = "backorder"
rows.append({
"time": current_time.isoformat(),
"product": product,
"qty": qty,
"stock_before": before,
"stock_after": inventory[product],
"status": status
})
# 库存过低自动补货
if inventory[product] < 20:
restock = random.randint(30, 80)
inventory[product] += restock
rows.append({
"time": current_time.isoformat(),
"product": product,
"qty": restock,
"stock_before": inventory[product] - restock,
"stock_after": inventory[product],
"status": "restock"
})
current_time += timedelta(days=1)
with open("warehouse_sim.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved warehouse_sim.csv")
输出:
其他可模拟场景
呼叫中心队列
打车请求与司机匹配
贷款申请与审批
订阅与流失
患者预约流程
网站流量与转化
3. 生成时间序列合成数据
合成数据不仅限于静态表格,大量系统会产生时序数据(流量、传感器、订单、服务耗时)。
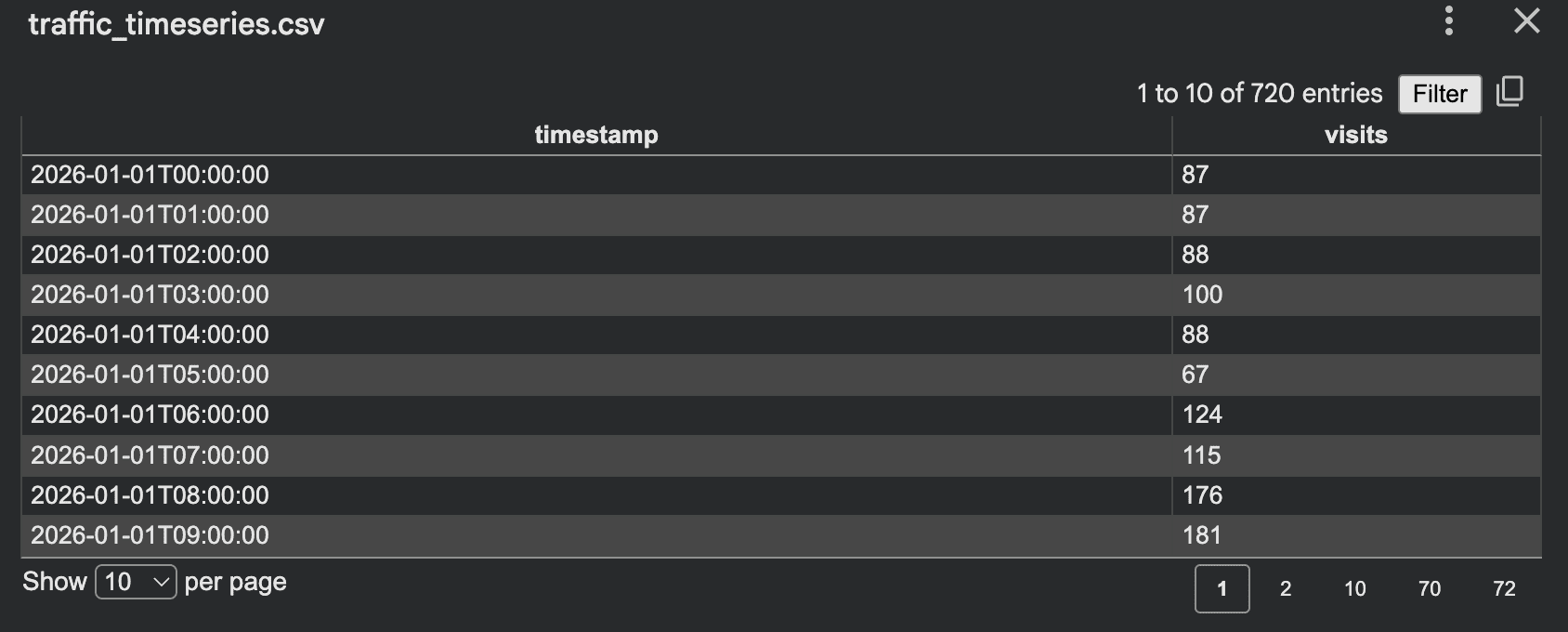
示例:带工作日/时段规律的网站每小时访问量:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
start = datetime(2026, 1, 1, 0, 0, 0)
hours = 24 * 30
rows = []
for i in range(hours):
ts = start + timedelta(hours=i)
weekday = ts.weekday()
# 基础流量:工作日120,周末80
base = 120
if weekday >= 5:
base = 80
# 时段波动
hour = ts.hour
if 8 <= hour <= 11:
base += 60
elif 18 <= hour <= 21:
base += 40
elif 0 <= hour <= 5:
base -= 30
# 高斯噪声
visits = max(0, int(random.gauss(base, 15)))
rows.append({
"timestamp": ts.isoformat(),
"visits": visits
})
with open("traffic_timeseries.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["timestamp", "visits"])
writer.writeheader()
writer.writerows(rows)
print("Saved traffic_timeseries.csv")
输出:
优势
包含趋势、噪声、周期性规律
逻辑清晰,易于调试
高度贴近真实时序数据
4. 创建事件日志
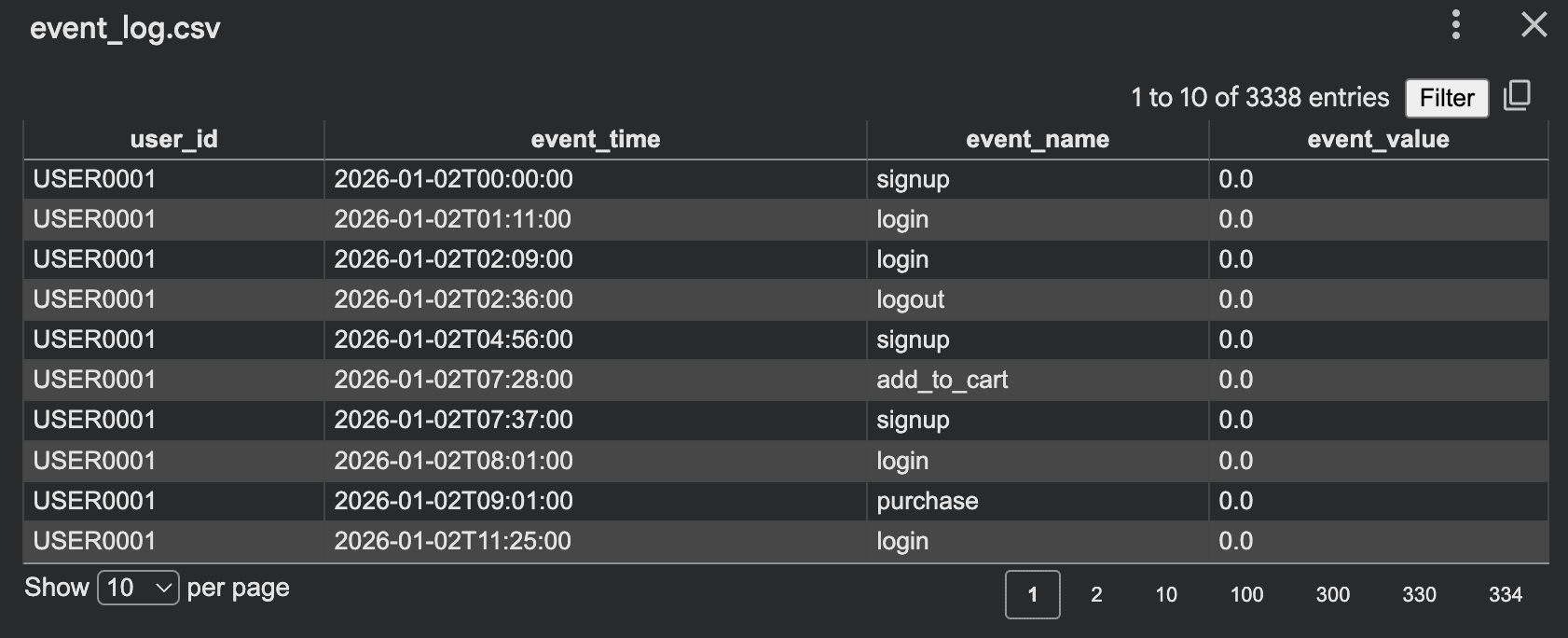
事件日志非常适合产品分析、流程测试,每行代表一个用户行为:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
events = ["signup", "login", "view_page", "add_to_cart", "purchase", "logout"]
rows = []
start = datetime(2026, 1, 1)
# 生成200个用户的行为事件
for user_id in range(1, 201):
event_count = random.randint(5, 30)
current_time = start + timedelta(days=random.randint(0, 10))
for _ in range(event_count):
event = random.choice(events)
# 购买行为附带金额
if event == "purchase" and random.random() < 0.6:
value = round(random.uniform(10, 300), 2)
else:
value = 0.0
rows.append({
"user_id": f"USER{user_id:04d}",
"event_time": current_time.isoformat(),
"event_name": event,
"event_value": value
})
current_time += timedelta(minutes=random.randint(1, 180))
with open("event_log.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved event_log.csv")
输出:
适用场景
漏斗分析
分析管道测试
BI仪表盘
会话重建
异常检测实验
进阶技巧
让事件依赖前置行为(例如:购买必须发生在登录/浏览页面之后),数据会更真实。
5. 用模板生成合成文本数据
合成数据对NLP任务同样重要,无需LLM,用模板就能生成高质量文本数据。
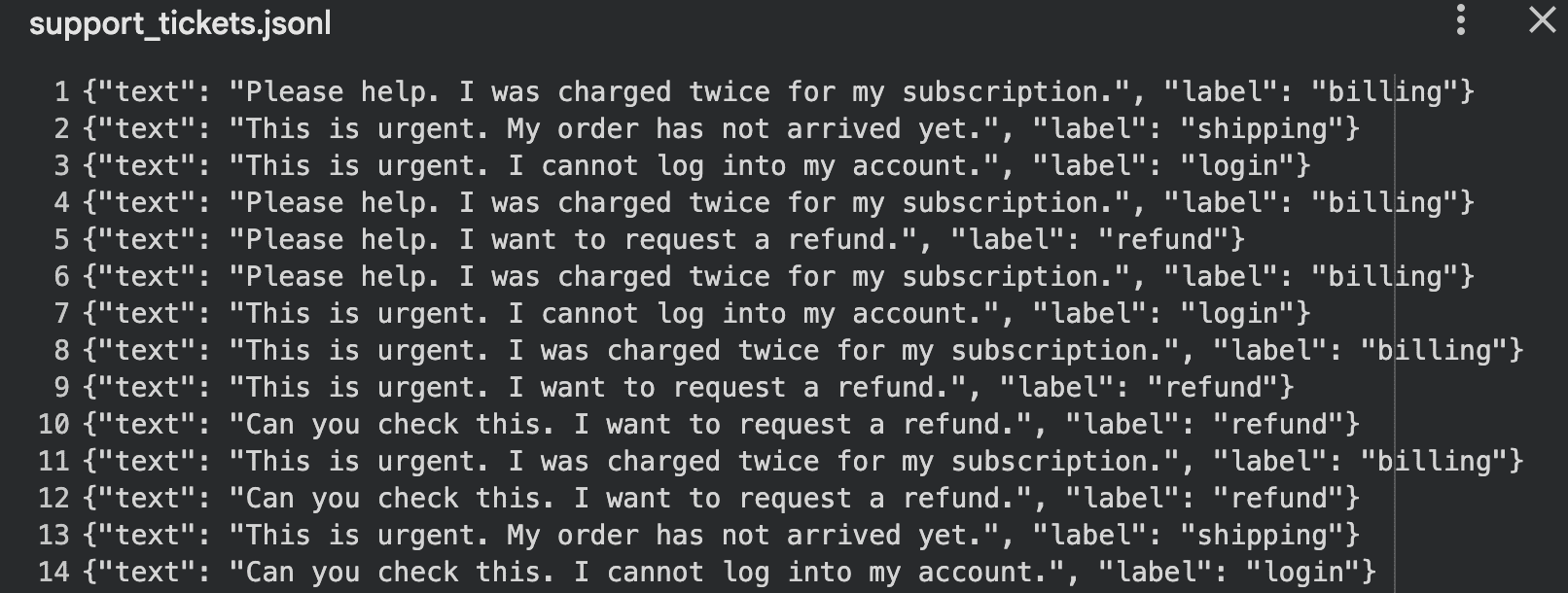
示例:客服工单分类训练数据:
import json
import random
random.seed(42)
issues = [
("billing", "I was charged twice for my subsc ription"),
("login", "I cannot log into my account"),
("shipping", "My order has not arrived yet"),
("refund", "I want to request a refund"),
]
tones = ["Please help", "This is urgent", "Can you check this", "I need support"]
records = []
for _ in range(100):
label, message = random.choice(issues)
tone = random.choice(tones)
text = f"{tone}. {message}."
records.append({"text": text, "label": label})
# 保存为JSONL格式
with open("support_tickets.jsonl", "w", encoding="utf-8") as f:
for item in records:
f.write(json.dumps(item) + "\n")
print("Saved support_tickets.jsonl")
输出:
适用场景
文本分类演示
意图识别
聊天机器人测试
提示词评估
最后总结
合成数据脚本功能强大,但容易被错误使用,务必避开这些常见问题:
所有数据使用均匀随机分布
忽略字段间的依赖关系
生成违反业务逻辑的数据
认为合成数据天然安全无风险
数据过于“干净”,无法测试真实边界案例
模式重复,数据可预测、不自然
隐私提醒
合成数据降低了真实数据泄露风险,但并非绝对安全。如果生成器与原始敏感数据绑定过紧,仍可能发生数据泄露。因此,差分隐私等隐私保护方法必不可少。
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 京公网安备 11010802022788号
京公网安备 11010802022788号







