


 雷达卡
雷达卡




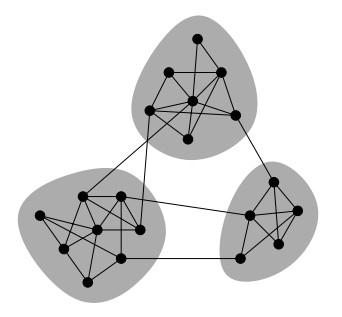
图1. 基于图的拓扑结构进行社区发现
社区发现综述社区发现作为网络科学的经典问题之一,长期受到研究者的广泛关注。
- Girvan等人使用GN算法进行求解,首先求解每条边的介数(betweenness),然后将介数最大的边删去,再重新求解每条边新的介数,依此循环。对应图1,连接不同社区的边的介数最大,把它们删去后即可得若干个独立的社区。但是求解介数时间复杂度高,在大图上并不实用,这时候需要考虑对图的抽样等问题。
- Label Propagation Algorithm使用邻居节点的信息来决定当前节点的社区,并且也可应用到多社区(Overlapping)的发现中,但会存在有结果震荡等问题,性能不稳定。
- 此外,也可以结合Game Theory、Particle Competition、KCore等方面的知识,求解社区发现问题。如Peng等人认为,图的部分重要节点可以决定社区的整体框架,所以可以首先求解图的KCore节点,缩小图的规模确定社区基本框架,再逐步将其他点添加进已有的社区中。
Modularity值用于评估社区发现的效果,对比社区发现结果与随机图(Null Model)的差异。对于同一个输入图进行不同的社区发现策略,取得Modularity值较高的策略性能较好。具体计算公式如下:

其中,Aij 表示节点i与节点j之间的边的权重;ki 表示所有连接到节点i的边的权重之和;ci 表示当前节点i归属的社区;而当u等于v时,函数δ(u,v)的值为1,否则为0。
对上述公式进行化简,如下:

其中,∑in 表示一个社区内部的连线数,∑tot 表示一个社区所有节点的度数之和。对比公式(1),它少了判断两个节点是否属于同一个社区的δ(u,v)函数,在后面的章节中我们可以看到,这种化简带来的计算量上的好处。
FastUnfolding算法综合数据规模、运行时间等多方面的考虑,本文选择Blondel等人提出的FastUnfolding算法进行实现。算法的基本步骤如下:
1.初始化,将每个节点划分在不同的社区中。
2.逐一选择各个节点,根据公式(3)计算将它划分到它的邻居社区中得到的Modularity增益。如果最大增益大于0,则将它划分到对应的邻居社区;否则,保持归属于原社区。
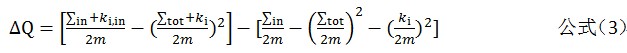
3.重复步骤2,直到节点的社区不再发生变化。
4.构建新图。新图中的点代表上一阶段产生的不同社区,边的权重为两个社区中所有节点对的边权重之和。重复步骤2,直到获得最大的Modularity值。
可以将上述步骤分为两阶段(Pass)
- 1st Pass: 包含步骤1至3,用于设定各节点的归属社区,直到不再发生变化
- 2nd Pass: 由步骤4组成,用于构建新图,并重新执行1st Pass的操作,直到Modularity值不再增加
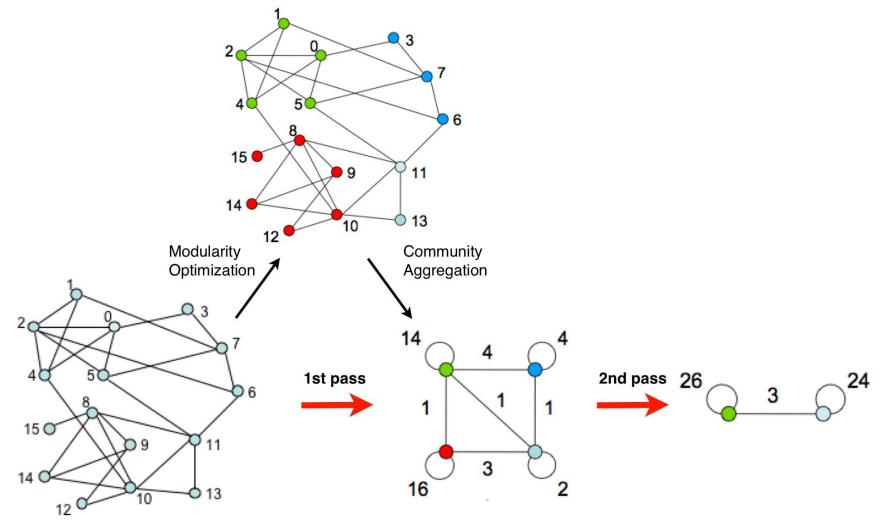
图2.FastUnfolding算法示意图
串行化实现原始的FastUnfolding算法采用的是串行化实现方式:逐个选择节点,重新计算它的社区,不断进行迭代。这种串行化的计算方式,对分布式计算框架非常不友好,因为在选择一个节点计算它的增益的时候,其它的节点是不能进行变化的。这样不能进行并行化计算,也不能充分利用分布式框架的高并发、集群计算优势。另外Spark对于这种细粒度的操作,也非常的不合适,它为了改变单个结点的值,也需重新生成一个包含所有数据的RDD,开销非常的大。
并行化实现为了将算法搬到分布式框架和集群上运行,我们需要对算法进行并行化改造。并行化的算法实现,会在每轮迭代中同步更新多个节点的信息,即根据t-1轮中邻居节点的信息来更新t轮中节点的信息,从而充分发挥高并发性的优势。
对照FastUnfolding的算法思路,定义一个新的数据结构VertexData,结构如下:
有了上述信息,就可以记录当前节点及它的邻居节点的信息。同时,为了提升性能,后续还可以使用kryo的序列化方法来替代Java的Serializable方法,获得时间和空间性能上的提升。
整体上,我们使用mrTriplets函数来实现算法,在map阶段,每个节点生成它所有邻居节点的VertexData消息,在reduce阶段将其合并,组成一个数组,包含这个节点的所有邻居信息。有了一个节点的所有邻居信息后,我们就可以使用公式(3)来计算它新归属的社区。上述操作对应于1st Pass的过程。
对于2nd Pass的操作,直接使用RDD处理起来更为直观。当前图的边信息保存在edgeRdd中,每行为节点对< srcId, dstId >。同时,我们将节点Id与它归属的社区信息保存在communityRdd中,每行为节点对< nodeId, communityId >。所以,执行两次的leftOuterJoin即可得到新图的边信息,具体代码如下:
有了新图的边信息后,使用Graph.fromEdgeTuples即可构建新图,完成2nd Pass的过程。
并行化问题及解决策略进行并行化处理时,我们主要遇到两个问题:一是中间计算量过大,二是消息滞后。
- 中间计算量过大
尝试的一个解决方法是,进行分步计算,如根据节点Id的hash值将数据划分成100个分区,每次只对分区内的节点进行计算。但是这种方法处理不直观,效率也不高。
经过反复尝试后,我们发现,更好的解决方法是使用化简后的公式(2)进行处理,避免了pairwise的过程。
- 消息滞后

图3. “互换社区”问题示意图
变化情况如图3所示:
- 每个节点被分配到不同的社区中(节点1属于G1,节点2属于G2,节点3属于G3,节点4属于G4)
- 第二轮b图时,每个节点根据它邻居的信息进行更新(如节点1的新社区为邻居节点2在第一轮的社区G2)
- 最终情况会导致不相连的节点反而归属同一社区(如节点1与3均受到节点2的影响,归属社区G2)
- 第三轮c图类似,造成社区的互换。造成这种情况的原因在于,每个节点根据它的邻居前一轮的信息进行变化,而它的邻居也在同步改变。

图4.”社区归属延迟”问题示意图
考虑有以下两种解决策略:
- 添加随机值,即每轮迭代中会有部分节点的社区保持不变。如果阈值足够高,其实相当于逐个节点进行社区信息的更新,也即与串行的方法等价。使用随机值带来的问题是不能保证结果,得到的Modularity值有时高,有时低。并且,“互换社区”的问题不一定能解决。考虑到的一种解决思路是,多次运行,取最优。但是,这种方法也不太可靠,随机性较大。
- 得到结果后构建逻辑图,求解连通区域,将同一个连通区域的点都归为一个社区。比如初始结果是互换社区的<1,2>,<2,1>(格式为<节点Id,归属社区>),求连通区域就可以将它们都归属同一社区。这种思路也可以解决 “社区归属延迟”的问题,如初始结果是<1,2>,<2,3>,<3,4>,节点1应该与归属社区2,但是节点2又归属于社区3,所以最终应该节点1,2,3都归属社区3。
总结FastUnfolding算法,基于结果Modularity值的优化进行,得到的社区发现效果比较理想,对比LPA算法会更稳定。并且,FastUnfolding算法会不断合并节点构造新图,大大减少了计算量,使得大规模图数据的计算成为可能。
原始的FastUnfolding算法采用串行化的实现思路,不适合面对海量数据。实现中需要进行算法并行化,充分利用并行化框架带来的计算优势。在将传统的串行化算法改造成并行化算法的过程中时,会遇到中间计算量过大、消息滞后造成的问题,如“互换社区”和“社区归属延迟”问题。解决的思路是考虑图的特性,对结果再次求解连通图区域,并通过重置社区得到最终结果。这样既保证了算法的准确性,又保证其性能,从而能够在大规模的网络上,进行实际的生产应用。
根据我们的初步测评,在三千万的用户数据上,可以在2个小时的级别,发现四万的社区,基本满足生产预期。

 京公网安备 11010802022788号
京公网安备 11010802022788号







