


 雷达卡
雷达卡
















By Ujjwal Karn.
An Artificial Neural Network (ANN) is a computational model that is inspired by the way biological neural networks in the human brain process information. Artificial Neural Networks have generated a lot of excitement in Machine Learning research and industry, thanks to many breakthrough results in speech recognition, computer vision and text processing. In this blog post we will try to develop an understanding of a particular type of Artificial Neural Network called the Multi Layer Perceptron.
A Single NeuronThe basic unit of computation in a neural network is the neuron, often called a node or unit. It receives input from some other nodes, or from an external source and computes an output. Each input has an associated weight (w), which is assigned on the basis of its relative importance to other inputs. The node applies a function f (defined below) to the weighted sum of its inputs as shown in Figure 1 below:
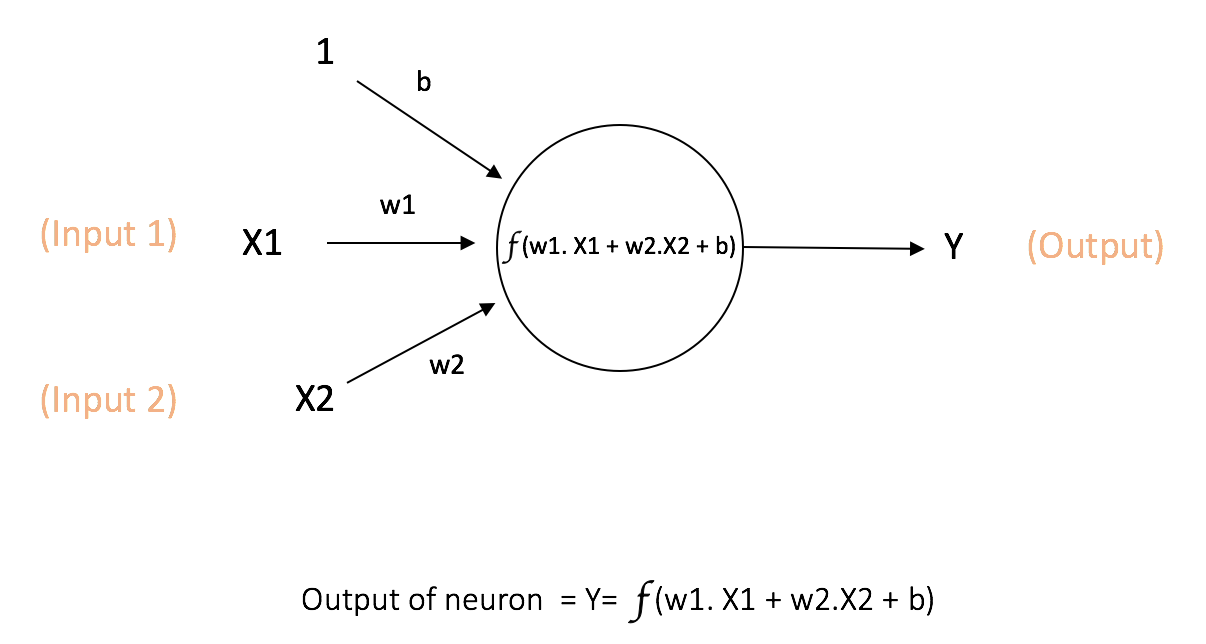
The above network takes numerical inputs X1 and X2 and has weights w1 and w2 associated with those inputs. Additionally, there is another input 1 with weight b (called the Bias) associated with it. We will learn more details about role of the bias later.
The output Y from the neuron is computed as shown in the Figure 1. The function f is non-linear and is called the Activation Function. The purpose of the activation function is to introduce non-linearity into the output of a neuron. This is important because most real world data is non linear and we want neurons to learn thesenon linear representations.
Every activation function (or non-linearity) takes a single number and performs a certain fixed mathematical operation on it [2]. There are several activation functions you may encounter in practice:
- Sigmoid: takes a real-valued input and squashes it to range between 0 and 1
σ(x) = 1 / (1 + exp(−x))
- tanh: takes a real-valued input and squashes it to the range [-1, 1]
tanh(x) = 2σ(2x) − 1
- ReLU: ReLU stands for Rectified Linear Unit. It takes a real-valued input and thresholds it at zero (replaces negative values with zero)
f(x) = max(0, x)
The below figures [2] show each of the above activation functions.
 Figure 2: different activation functions
Figure 2: different activation functionsImportance of Bias: The main function of Bias is to provide every node with a trainable constant value (in addition to the normal inputs that the node receives). See this link to learn more about the role of bias in a neuron.
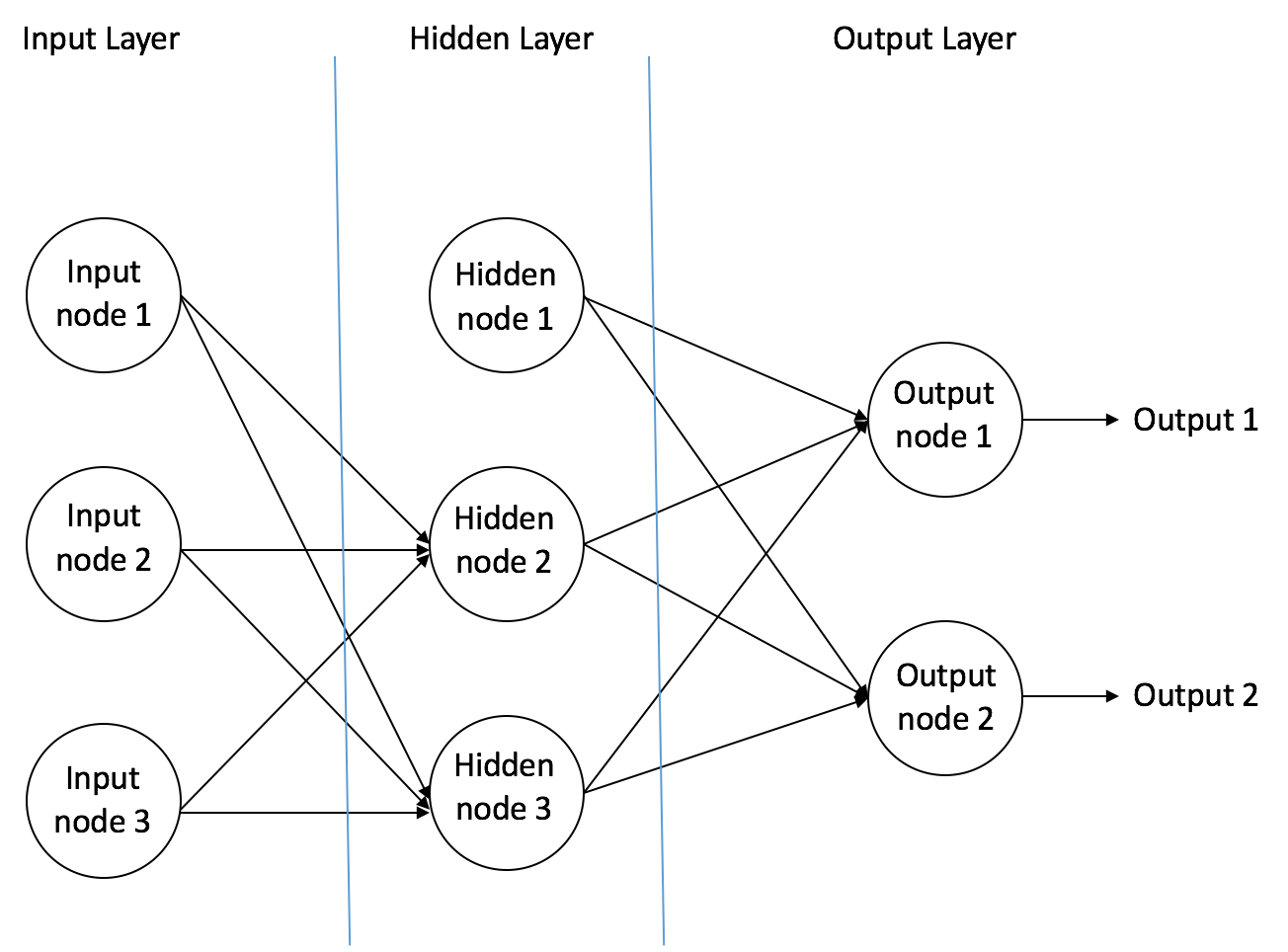
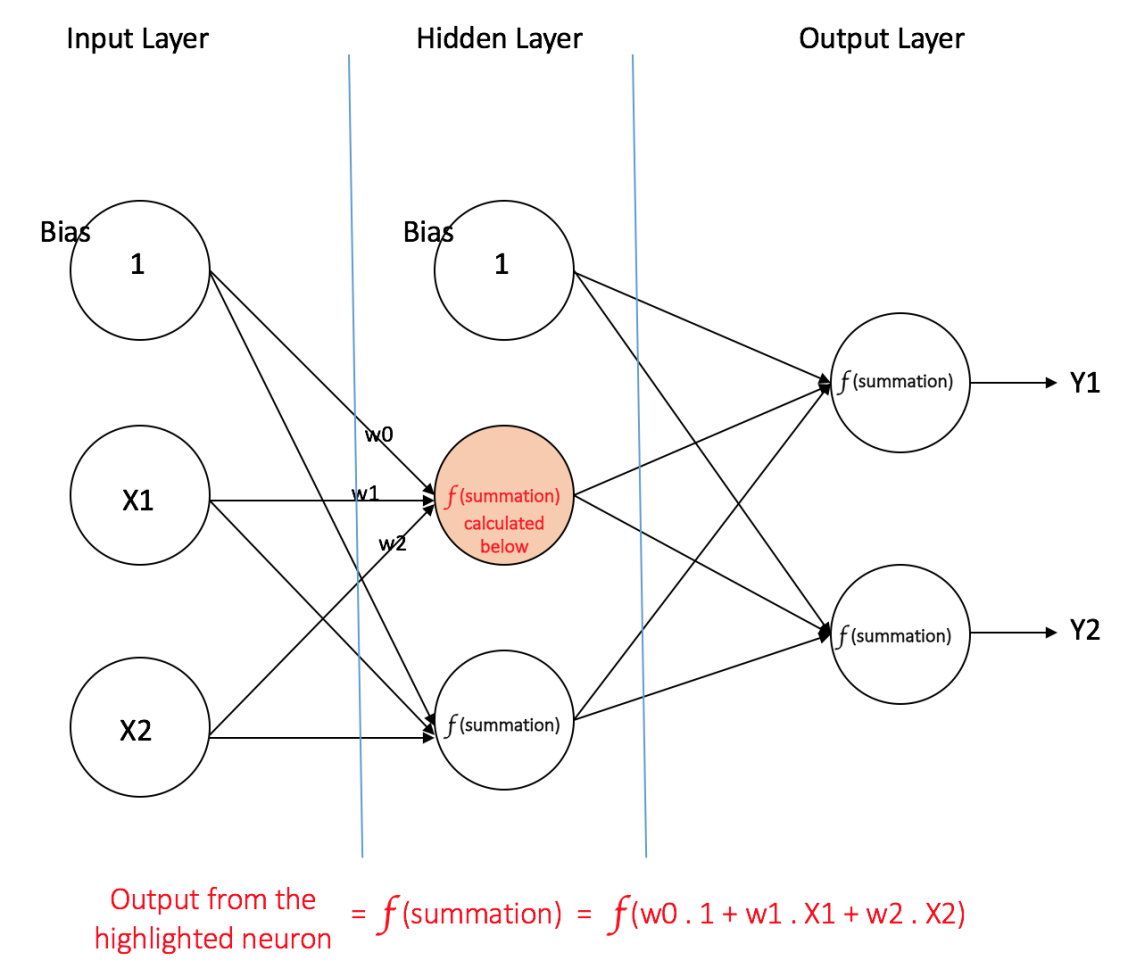
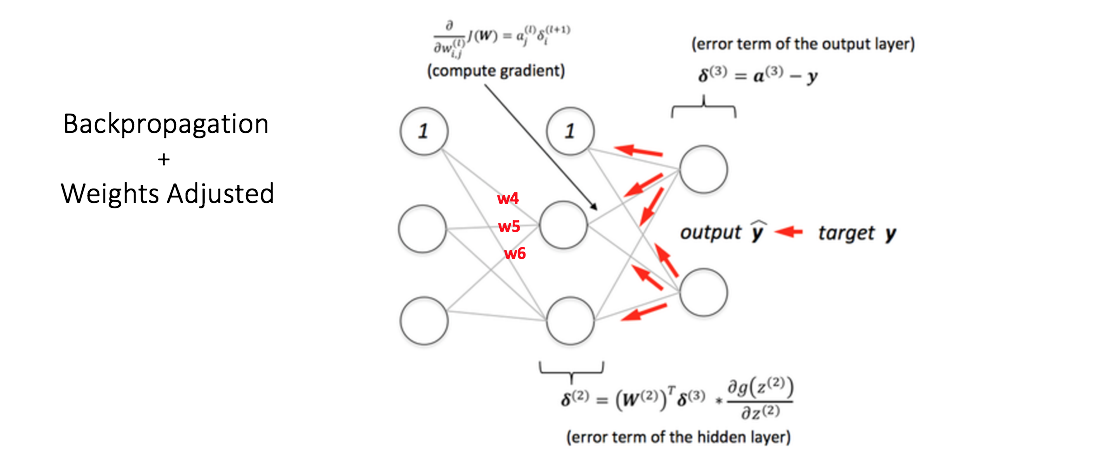
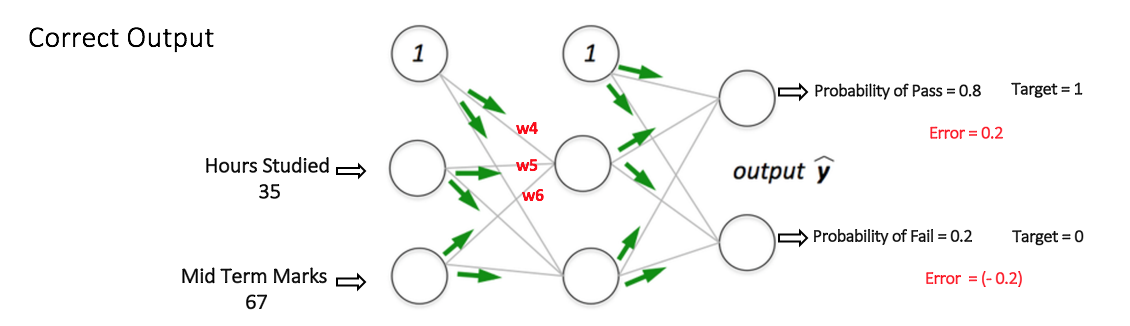
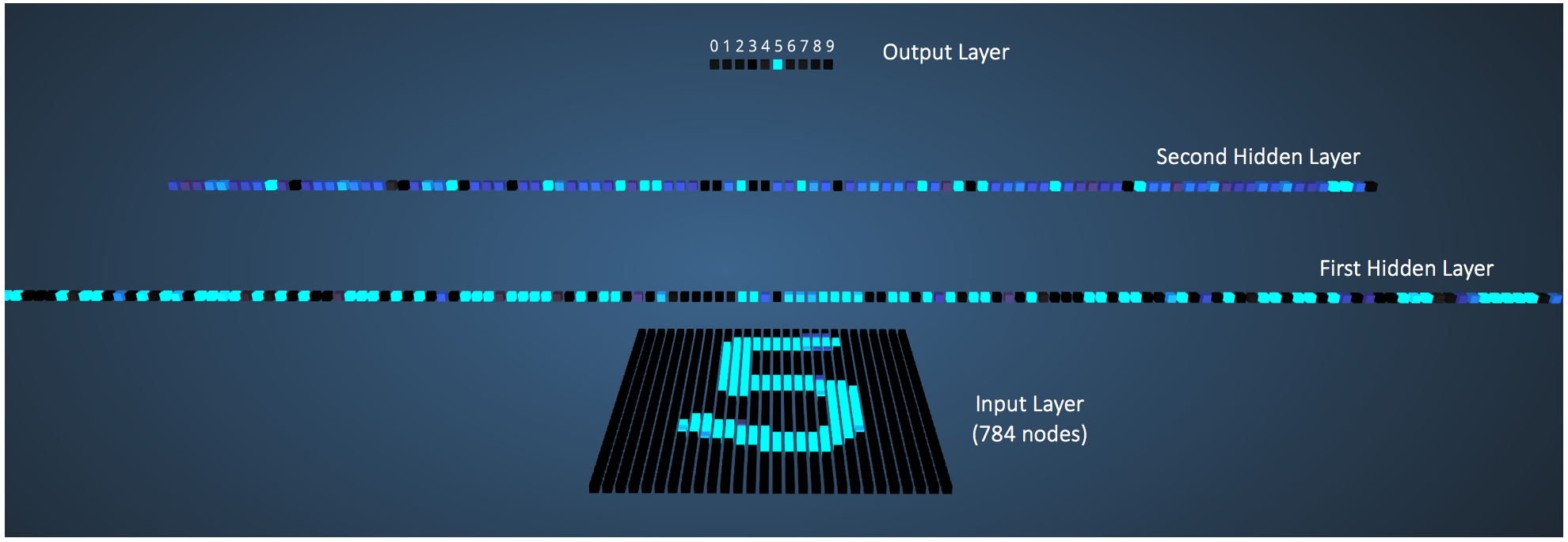
Feedforward Neural NetworkThe feedforward neural network was the first and simplest type of artificial neural network devised [3]. It contains multiple neurons (nodes) arranged in layers. Nodes from adjacent layers have connections or edges between them. All these connections have weights associated with them.
An example of a feedforward neural network is shown in Figure 3.


 京公网安备 11010802022788号
京公网安备 11010802022788号







