


 雷达卡
雷达卡




AlphaGo“退役”了,但Deepmind在围棋上的探索并没有停止。
今年5月的乌镇大会的“人机对局”中,中国棋手、世界冠军柯洁9段以0:3不敌AlphaGo。随后Deepmind创始人Hassabis宣布,AlphaGo将永久退出竞技舞台,不再进行比赛。同时Hassbis表示:“我们计划在今年稍晚时候发布最后一篇学术论文,详细介绍我们在算法效率上所取得的一系列进展,以及应用在其他更全面领域中的可能性。就像第一篇 AlphaGo 论文一样,我们希望更多的开发者能够接过接力棒,利用这些全新的进展开发出属于自己的强大围棋程序。”
今天,Deepmind在如约在Nature发布了这篇论文——在这篇名为《Mastering the game of Go without human knowledge》(不使用人类知识掌握围棋)的论文中,Deepmind展示了他们更强大的新版本围棋程序“AlphaGo Zero”,验证了即使在像围棋这样最具挑战性的领域,也可以通过纯强化学习的方法自我完善达到目的。

摘要
人工智能的一个长期目标是通过后天的自主学习(雷锋网注:tabula rasa,意为“白板”,指所有的知识都是逐渐从他们的感官和经验而来),在一个具有挑战性的领域创造出超越人类的精通程度学习的算法。此前,AlphaGo成为首个战胜人类围棋世界冠军的程序,当时的AlphaGo通过深层神经网络进行决策,并使用人类专家下棋的数据进行监督学习,同时也通过自我对弈进行强化学习。在这篇论文中,我们将介绍一种仅基于强化学习的算法,而不使用人类的数据、指导或规则以外的领域知识。AlphaGo成为自己的老师,这一神经网络被训练用于预测AlphaGo自己的落子选择,提高了树搜索的强度,使得落子质量更高,具有更强的自我对弈迭代能力。从一块白板开始,我们的新程序AlphaGo Zero表现惊人,并以100:0击败了此前版本的AlphaGo。
全新强化学习算法:无需任何人类指导
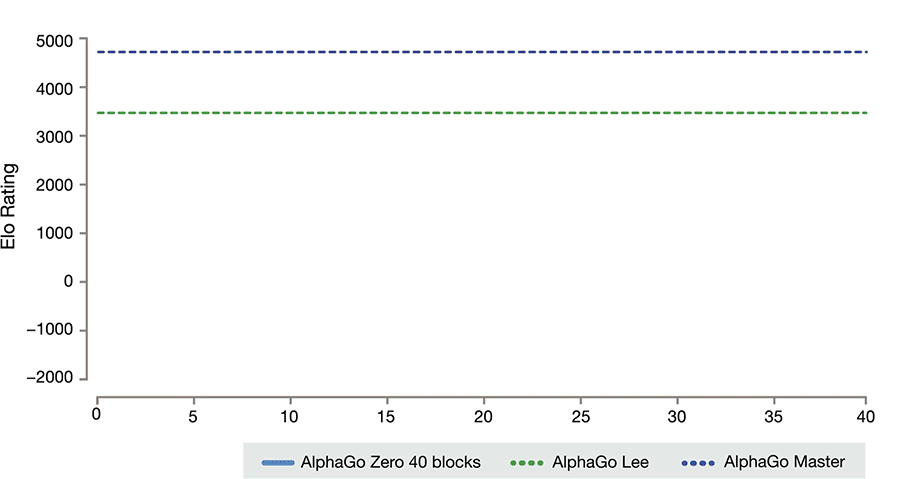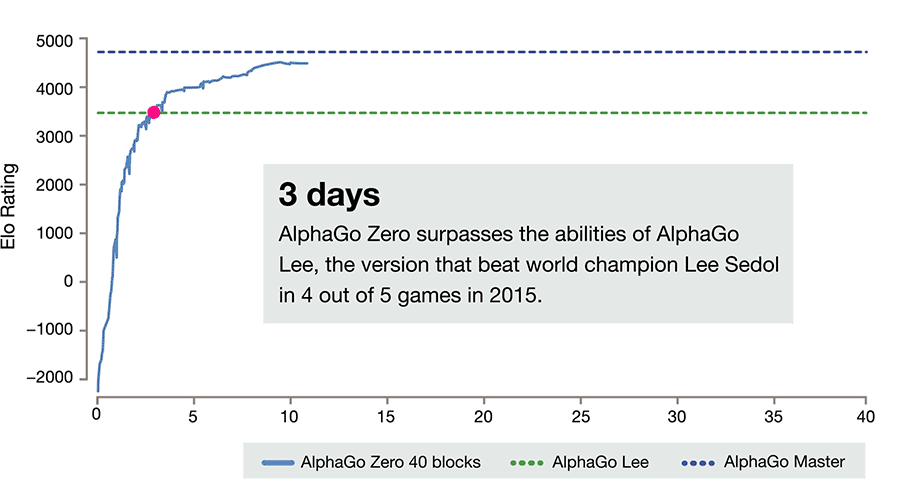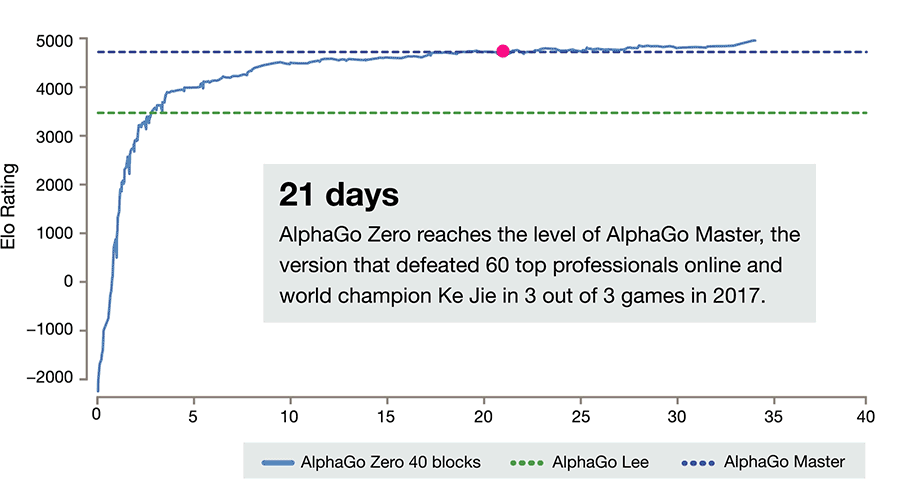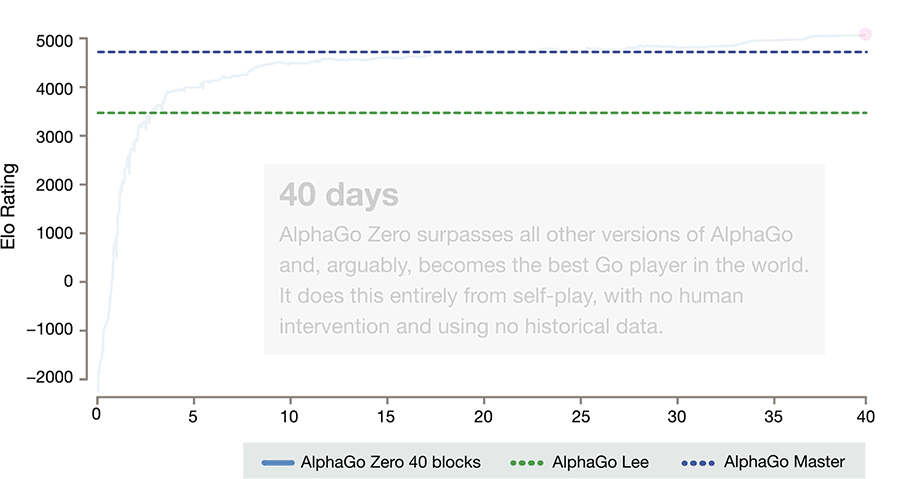
雷锋网发现,这篇论文的最大亮点,在于无需任何人类指导,通过全新的强化学习方式自己成为自己的老师,在围棋这一最具挑战性的领域达到超过人类的精通程度。相比起之前使用人类对弈的数据,这一算法训练时间更短,仅用3天时间就达到了击败李世石的AlphaGo Lee的水平,21天达到了之前击败柯洁的AlphaGo Master的水平。
在3天内——也就是AlphaGo Zero在击败AlphaGo Lee之前,曾进行过490万次自我对弈练习。 相比之下,AlphaGo Lee的训练时间长达数月之久。AlphaGo Zero不仅发现了人类数千年来已有的许多围棋策略,还设计了人类玩家以前未知的的策略。
据Deepmind博客介绍,AlphaGo Zero采用了新的强化学习方法,从一个不知道围棋游戏规则的神经网络开始,然后通过将这个神经网络与强大的搜索算法结合,然后就可以实现自我对弈了。在这样的训练过程中,神经网络被更新和调整,并用于预测下一步落子和最终的输赢。
这一更新后的神经网络将再度与搜索算法组合,这一过程将不断重复,创建出一个新的、更强大版本的AlphaGo Zero。在每次迭代中,系统的性能和自我对弈的质量均能够有部分提高。“日拱一卒,功不唐捐”,最终的神经网络越来越精确,AlphaGo Zero也变得更强。
Alpha Zero与之前版本有如下不同:
AlphaGo Zero 只使用棋盘上的黑子和白子作为输入,而之前版本AlphaGo的输入均包含部分人工特征;
AlphaGo Zero使用一个神经网络而不是之前的两个。以前版本的 AlphaGo 使用一个“策略网络”来选择落子的位置,并使用另一个“价值网络”来预测游戏的输赢结果。而在AlphaGo Zero中下一步落子的位置和输赢评估在同一个神经网络中进行,从而使其可以更好地进行训练和评估。
AlphaGo Zero 无需进行随机推演(Rollout)——这是一种在其他围棋程序中广泛使用于胜负的快速随机策略,从而通过比较确定每一手之后输赢的概率选择最佳落子位置,相反,它依赖于高质量的神经网络来评估落子位置。
上述差异均有主于提高系统的性能和通用性,但使最关键的仍是算法上的改进,不仅使得AlphaGo Zero更加强大,在功耗上也更为高效。
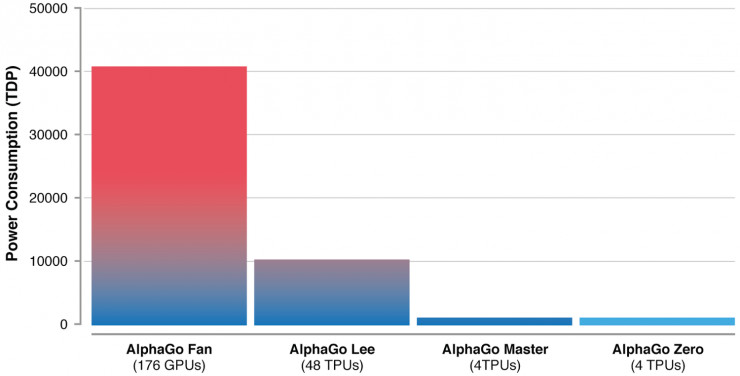
AlphaGo不同版本所需的GPU/TPU资源,雷锋网(公众号:雷锋网)整理
技术细节新方法使用了一个具有参数θ的深层神经网络fθ。这个神经网络将棋子的位置和历史状态s作为输入,并输出下一步落子位置的概率,用, (p, v) = fθ(s)表示。落子位置概率向量p代表每一步棋(包括不应手)的概率,数值v是一个标量估值,代表棋手下在当前位置s的获胜概率。
AlphaGo Zero的神经网络通过新的自我对弈数据进行训练,在每个位置s,神经网络fθ都会进行蒙特卡洛树(MCTS)搜索,得出每一步落子的概率π。这一落子概率通常优于原始的落子概率向量p,在自我博弈过程中,程序通过基于蒙特卡洛树的策略来选择下一步,并使用获胜者z作为价值样本,这一过程可被视为一个强有力的评估策略操作。在这一过程中,神经网络参数不断更新,落子概率和价值 (p,v)= fθ(s)也越来越接近改善后的搜索概率和自我对弈胜者 (π, z),这些新的参数也会被用于下一次的自我对弈迭代以增强搜索的结果,下图即为自我训练的流程图。
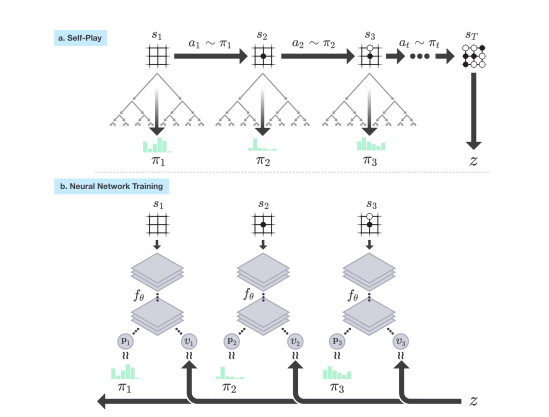
AlphaGo Zero 自我对弈训练的流程示意图
虽然这一技术还处于早期阶段,但AlphaGo Zero的突破使得我们在未来面对人类面对的一些重大挑战(如蛋白质折叠、减少能源消耗、寻找革命性的新材料等)充满信心。众所周知,深度学习需要大量的数据,而在很多情况下,获得大量人类数据的成本过于高昂,甚至根本难以获得。如果将该技术应用到其他问题上,将会有可能对我们的生活产生根本性的影响。



 京公网安备 11010802022788号
京公网安备 11010802022788号







