


 雷达卡
雷达卡




我们知道,在各种数据分析方法中,除了部分方法本身对数据值不敏感外,离群值、极端值对于分析结果都是具有影响的。这种影响尤其体现在需要对数据具体的值进行运算的方法中,比如回归类型的问题。极端值出现频率过高,极端值过于极端,都有可能造成分析结果的严重偏误,在探索数据之间关系和规律的过程中,这种极端值造成了很大困扰。
而金融数据分析中,无论是金融理论在实践分析中的应用,比如尝试使用CAPM,Fama-Franch因子模型对现实经济标的进行分析,还是在量化决策过程中应用模型进行择时或品种选择,都离不开对原始数据的处理和运算。对于数据在这些领域的应用,模型能否给出精准结果至关重要,前者决定着学术观点是否能被现实情况有力支撑,后者则直接决定了投资行为是否能最大化的产生效益。虽然保证模型结果的精确性是一个多步骤的复杂过程,但一定离不开对原始数据的维护。在这个前提下,对待极端值的态度和处理方法也就成了需要不断探索的问题。
对于极端数据,在量化领域有一些常用的方法。比如3-Mad方法,3-Sigmod方法,这些方法在剔除离群的数据方面是简单而有效的,受到了广泛的认可。用沪深300股票的市值数据为例,沪深300的原始市值分布如下:
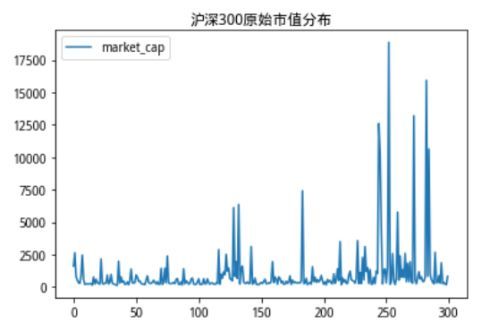
图1:沪深300成分股票市值分布
我们可以看到,沪深300成分股市值分布十分极端,存在部分市值规模过于庞大的股票,如果用这样的数据进行运算,得出的结果会收到极端值非常严重的影响,我们使用3-Mad方法进行剔除(如下图)。
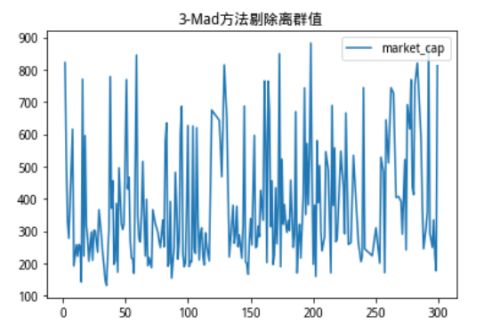
图2:3-Mad方法剔除离群值
无论是从纵坐标的值域还是分布图像上都可以看出,3-Mad方法剔除后,筛选出的股票市值波动都被压缩到了一定的范畴内,并且对比原始分布,几乎完全剔除了特别极端的离群点。
我们再看一看以标准差为参照基准的3-Sigmod方法对离群点的剔除效果。
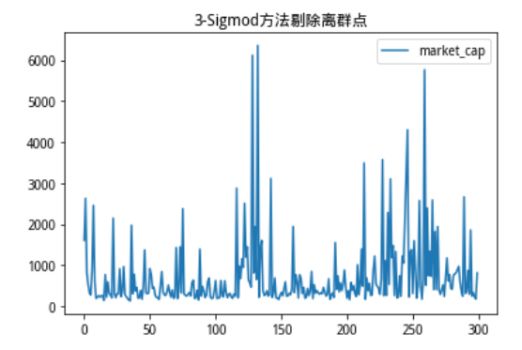
图3:3-Sigmod方法剔除离群值
对比原始分布的图例值域,可以看出极端离群的市值点被3-Sigmod方法过滤掉了,而对比3-Mad方法,3-Sigmod方法在剔除条件上更宽松一点,两者各有优劣,3-Mad方法严格地保证了数据在一定范围内波动,而3-Sigmod方法则保留了更多的数据值,可以根据不同的需求对方法进行选择。
通过上文的介绍,我们已经看出,在剔除离群点上,已经有很多行之有效的方法可供选择。但是,事实上我们仍然面对一个问题,那就是,上文介绍的所有方法,都是对于单一序列的处理,如果我们现在面对的是有两个以上维度的高维数据,我们该如何考虑离群点的处理方法。
可能有人会说,高维数据也是由不同截面下的一维序列构成的,对于每个不同的维度应用一下上面的方法就可以了。但事实上并不能这么做,这样做的,光是显然易见的弊端就有两个:第一,会造成更大规模的信息损失,因为逐一进行剔除,不同的纬度之间剔除的部分是取并集的,最极端会出现提出所有数据的情况;第二,这样的方法在高维度上没有考虑到不同维度之间联合分布。
方法介绍
基于上述问题,我们思考了对高维数据剔除极端值的一种新方法,并且对极端值的处理重新做了设计。
首先我们知道高维数据是形如这样的向量组:
这些向量组虽然无法直接可视化描述,但是对于他们联合分布的关系我们可以使用替代的方法去描述标志。在这里我选择了距离作为这个替代变量,距离计算公式表示如下。

为了能够描述数据点之间的分布,我们需要找到一个目标数据点,使得所有其他数据点到这个目标数据点距离最小化,然后用其他数据点到目标数据点之间的距离来近似地描述所有数据在高维上的分布情况,数学表示如下:
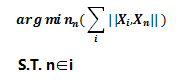
我把找到的这个目标向量称为核向量。还是以沪深300股票为例子,我们使用的数据维度为市值,ROE和市盈率(pe ratio),我们观察一下通过寻找核向量而计算得出的数据分布情况。
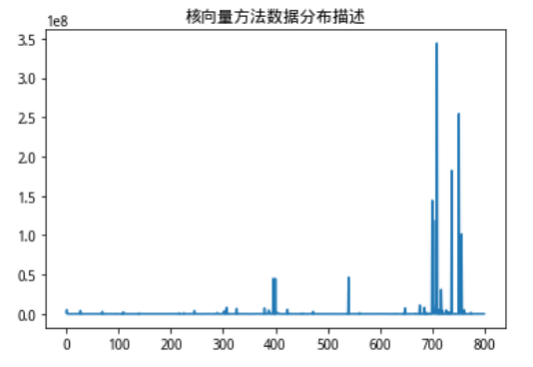
图4:核向量方法数据分布描述
这时候我们发现了一个问题,我们看一看数据点各个维度单一序列的分布情况。
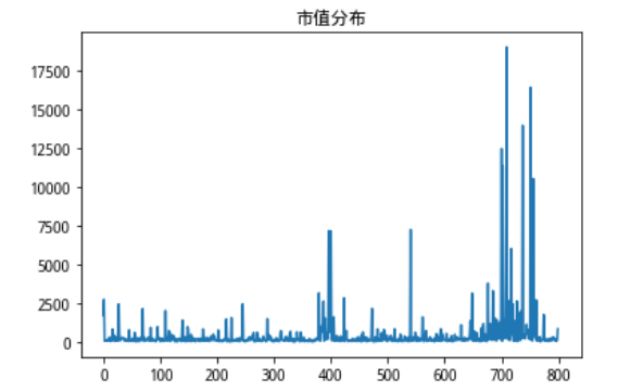

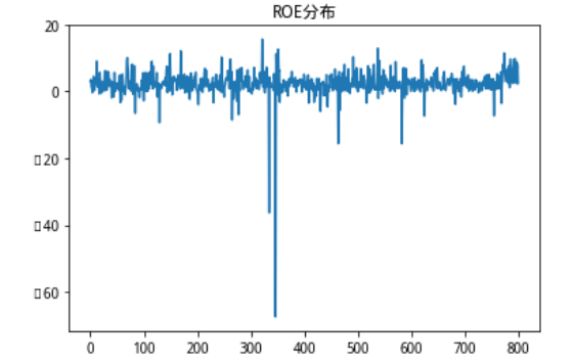
图5:3种不同维度单一序列分布情况
我们发现,寻找核向量并计算出来用以描述高维联合分布情况地距离数据,和市值数据的分布情况一致性程度非常高,也就是说,市值数据由于本身数值巨大,完全影响了我们对距离的计算,占到了巨大的权重,但事实上,在我们的想法以及现实经济意义中,我们认为这些财务情况对股票的影响权重虽然不一定等权,但不可能是这样不平衡的极端情况,鉴于此,我们修改了核向量的寻找方法,在加入了距离惩罚项,以此来平衡不同量纲的数据对距离计算的影响。当然这个距离惩罚项可以有多种计算方法,比如Max-Min,、Z-score等,这里我们使用最简单的均值作为距离惩罚。
我们观察一下修改方法后的数据情况:
首先把修改方法前所有的原始数据分布绘制出来看一看
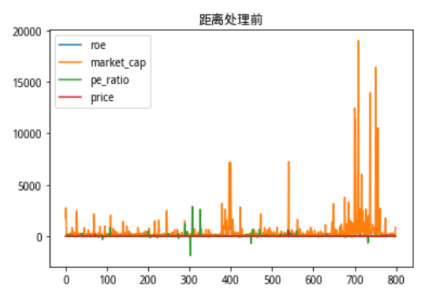
图6:方法修改前各个维度数据分布情况
可以看到市值在数据上的体量完全覆盖掉了其他数据的分布情况。
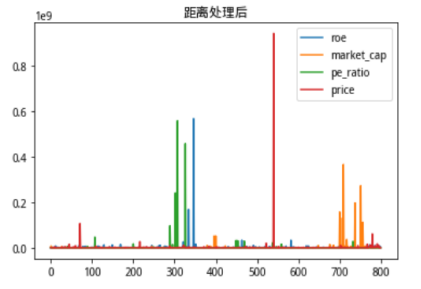
图7:方法修改前各个维度数据分布情况
这个时候我们可以看到修改方法后,不同数据的分布情况都能够较为明显得体现出来。当前计算出来的核向量距离数据分布如下:
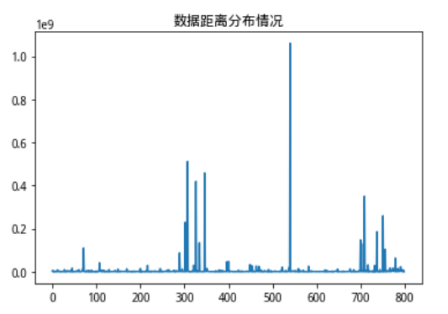
图8:修改方法后核向量距离分布情况
经过以上计算,我们就可以进行下一步,处理数据了。
处理极端数据的方法,我并没有直接使用传统的直接剔除的方法,因为鉴于目前各种统计方法对数据量的需求,我们更愿意保留一些数据信息使得模型更加平滑可靠。在统计学习领域有一种叫做KNN的计算方法,聚宽的量化课堂上有详细的描述,我之前也写过如何实现KNN的文章,有需求的读者可以去阅读,在这里不再赘叙。
简单来说,我们的模型使用的历史数据都是有标注的,一个特征向量对应一个特征值,我们经常通过KNN算法对特征值进行预测,但是这个方法中我们反向运用KNN,首先我们通过一个准则来确定一个特征向量是不是离群点,如果是,则通过寻找和它标签值最邻近的K个值特征向量,然后将这个离群点的特征向量值替换为K个点对应特征值的平均值。这样既处理了数据,又部分保留了特征信息,同时没有减少数据量。
这时候我们又遇到了一个问题,在回归问题中,特征向量的标签值是连续的数字,寻找最临近数据点,但是分类问题中,标签大多为离散取值,甚至在二分类问题中我们的标签全都是bool值,总不能随机选取几个bool值进行KNN计算吧?
所以我们给出的权衡方法是,在分类问题中,如果数据点A是离群点,那么我们就寻找和数据点A到核向量数据点距离值最接近且不为离群点的的K个数据点作为A的临近点进行计算。这样可以比较妥当的解决不同问题中由于数值特性带来的计算问题。
最后要提及的是,我们的离群点确认方法是在核向量距离中确定离群点,我们认为距离核向量过于远的数据为离群点,这里我还是使用了3-Mad的方法,和上文一致,我们可以看下这样处理后,单一维度的分布情况。
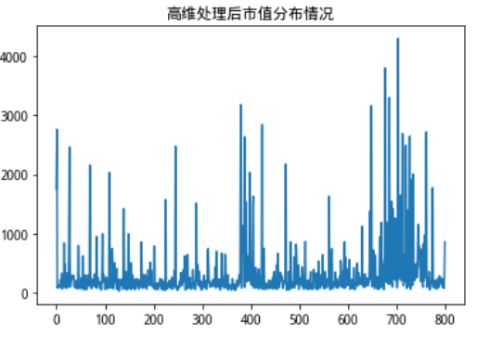
图9:高维处理后3种不同维度单一序列分布情况
大家可以对比一下上图完全无处理时候的单一序列分布图,可以明显看出各个特征维度在极端值和值分布上都得到了较好的处理。
方法实证
>>> 截面回归实证
为了检验数据情况,我们直接使用截面数据进行一次OLS回归,看看是否能提升模型的解释能力。
选取股票池:以沪深300为例子
选取解释变量为:30日后的收益率
选取被解释变量为:上文进行处理的市值,ROE和市盈率财务指标
未进行数据处理前的回归情况:

图10:无任何处理直接回归结果
可以看到无论是参数置信程度还是回归R^2效果都很差
进行上述处理方法后的回归结果:
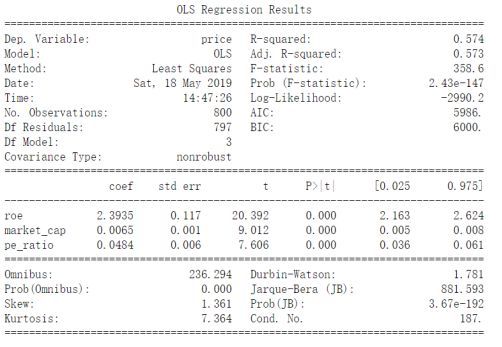
图11:数据处理后回归结果
可以看到无论是参数置信程度还是回归R^2效果都得到了显著提升,从截面角度验证了处理方法有效。
>>> 策略实证
我们选取一个对数据相对敏感的策略进行测试,通过观察直接使用原始数据和使用处理后的数据是否能带来绩效提升来判断处理方法是否有效。
为了方便起见,我设计了一个SVM分类对未来股票走势进行预测的简单策略,使用股票池仍为沪深300指数成分股票。使用特征数据为Fama-Franch三因子模型中的因子值(并非是分组收益率的形式,而是直接使用因子的原始值)。预测目标为未来30天的股票的涨幅情况。
未处理前绩效如下:
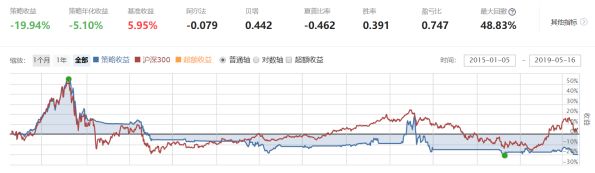
图12:无任何处理前策略绩效
数据处理后绩效情况如下:
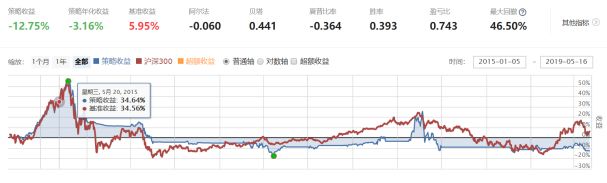
图13:数据处理后策略绩效
我们看到,虽然绩效均不理想,或者可以说非常差劲。但是数据处理后的绩效结果,对比直接使用原始数据的策略绩效有了一些提升。一个策略的收益程度会受到多方面的影响,可能是模型思路需要改进,选取因子、数据需要调整仓位管理等等。但绩效的改变,对我们数据处理方法的有效性提供了一定的参考。

 京公网安备 11010802022788号
京公网安备 11010802022788号







