


 雷达卡
雷达卡





数据科学(Python/R/Julia)数据分析、机器学习、深度学习
为什么要筛选有效的输入变量
提高模型的稳定性;
提高模型准确性;
提高运算速度和运算效率。

除了根据业务经验去筛选变量以外,也可以通过许多原理和算法去进行筛选。而非常方便的一点是这些方法一般都可以在数据挖掘软件中直接调用,下面将简单的介绍几种常用的方法及其原理。
共线性问题
共线性是指输入变量之间存在较强甚至完全的线性相关关系,当输入变量之间高度相关时,模型参数会变得不稳定,模型的预测能力会降低。同时也增加了解释模型的成本,无法确切分辨每个输入变量对目标变量的影响。
可以通过以下几种方法发现共线性问题
在前期筛选输入变量时通过相关性系数的方法,如皮尔逊相关系数进行识别;
观察模型的结论,结合相关指标进行分析;
主成分分析,某几个变量的主成分载荷系数较大,且数值接近,可能存在共线性问题;
聚类分析,对区间性变量聚类,同一类中的变量具有较强的相似性,也可能存在共线性问题;
通过业务经验判断,原本没有预测能力的变量突然变得有很强的统计性,可能存在共线性问题。
如何处理共线性呢
对高度共线性的变量,只保留最有价值和意义的,过滤其他变量;
对变量进行组合,衍生一个新的综合性变量;
对相关变量做一些形式上的转换,如分箱、标准化等。
删除明显无价值的变量

什么是明显无价值的变量?
常数变量或只有一个取值的变量;
缺失值比例很高的变量;
取值太泛的类别型变量。
用线性相关性指标进行筛选
当输入变量之间的相关性较高时,只需要保留一个变量就可以。

皮尔逊相关系数
r的取值在[-1,+1]之间,当
|r|<0.3时,表示低度线性相关;
当多个变量属于中度线性相关以上时,只需保留一个即可。
R平方
这种方法是借鉴多元线性回归的分析算法来判断和选择对目标变量有重要预测意义及价值的自变量。R平方表示模型输入的自变量在多大程度上可以解释目标变量的可变性。取值范围在[0,1]之间,值越大说明模型的拟合越好。
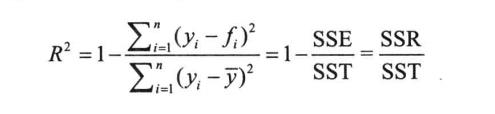
yi表示目标变量的真实值,fi表示模型的预测值,y上划线标识目标变量真实值的平均值。
SSE为残差平方和,自由度为P,P代表自变量的个数;
SST代表总平方和,自由度为N-1,N代表样本数量;
SSR代表回归平方和,自由度为N-P-1。
卡方检验
主要用来度量类别型变量(包括次序型变量)等定性变量之间的相关性。基本思想是比较理论频数与实际频数的吻合程度或拟合度。一般是用于检验类别型目标变量和类别型输入变量的相关程度。
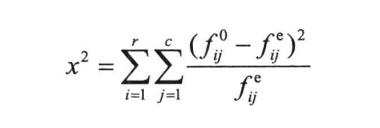
x2值越大表明期望值与观测值之间的差异越大,相对应的P-value值也就越小,P-value代表上述差异发生的偶然性。
通常,P-value小于0.01,同时x2比较大,则说明可以拒绝该输入变量与目标变量之间相互独立的假设,也就是输入变量与目标变量有强关联关系。
IV和WOE
当目标变量是二元变量,输入变量是区间型变量时,可以通过IV和WOE进行变量的筛选。
应用前需要先把区间型输入变量分箱转化为类别型(次序型)变量。
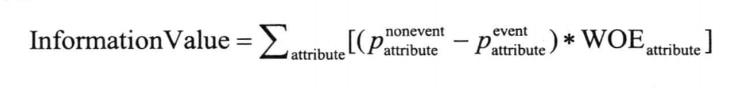
IV公式
IV可以用来表现一个变量在总的预测能力,代表了该变量区分目标变量中事件和非事件的能力。
其中
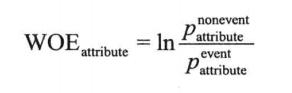
WOE公式
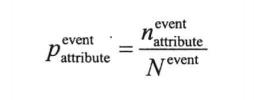
分箱得到的各个属性区间中目标事件占总事件的比例
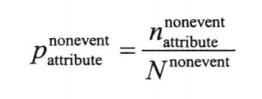
分箱得到的各个属性区间中非目标事件占总事件的比例
通过WOE变化来调整最佳的分箱阈值。然后通过IV值筛选出有较高预测价值的输入变量。
使用部分算法模型进行变量筛选
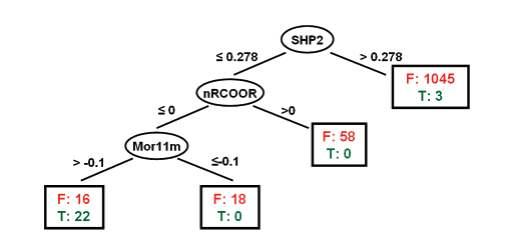
决策树、线性回归、逻辑回归等都可以用于变量的筛选。
降维

如主成分分析、因子分析、变量聚类等,这些方法可以精简输入变量的数量。

关注“AIU人工智能”公众号,回复“白皮书”获取数据分析、大数据、人工智能行业白皮书及更多精选学习资料!


 京公网安备 11010802022788号
京公网安备 11010802022788号







