


 雷达卡
雷达卡





数据科学(Python/R/Julia)数据分析、机器学习、深度学习
0 前言
说到处理循环,我们习惯使用for, while等,比如依次打印每个列表中的字符:

在打印内容字节数较小时,全部载入内存后,再打印,没有问题。可是,如果现在有成千上百万条车辆行驶轨迹,叫你分析出其中每个客户的出行规律,堵车情况等,假如是在单机上处理这件事。
你可能首先要面临,也可能被你忽视,最后代码都写好后,才可能暴露出的一个问题:outofmemory, 这在实际项目中经常遇到。
这个问题提醒我们,处理数据时,如何写出高效利用内存的程序,就显得很重要。今天,我们就来探讨如何高效利用内存,节省内存同时还能把事情办好。
其实,Python已经准备好一个模块专门用来处理这件事,它就是itertools 模块,这里面几个函数的功能其实很好理解。
我不打算笼统的介绍它们所能实现的功能,而是想分析这些功能背后的实现代码,它们如何做到高效节省内存的,Python内核的贡献者们又是如何写出一手漂亮的代码的,这很有趣,不是吗?
OK,let's go. Hope you enjoy the journey!
1 拼接元素
itertools 中的chain 函数实现元素拼接,原型如下,参数*表示个数可变的参数
chain(iterables)
应用如下:

哇,不能再好用了,它有点join的味道,但是比join强,它的重点在于参数都是可迭代的实例。
那么,chain如何实现高效节省内存的呢?chain大概的实现代码如下:

以上代码不难理解,chain本质返回一个生成器,所以它实际上是一次读入一个元素到内存,所以做到最高效地节省内存。
2 逐个累积
返回列表的累积汇总值,原型:
accumulate(iterable[, func, *, initial=None])
应用如下:

accumulate大概的实现代码如下:
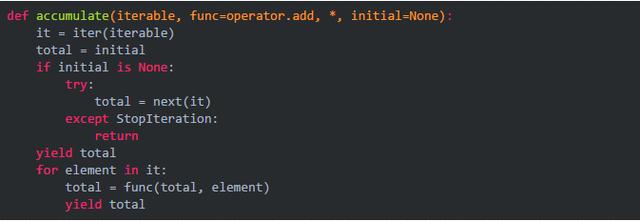
以上代码,你还好吗?与chain简单的yield不同,此处稍微复杂一点,yield有点像return,所以 yield total那行直接就返回一个元素,也就是iterable的第一个元素,因为任何时候这个函数返回的第一个元素就是它的第一个。又因为yield返回的是一个generator对象,比如名字gen,所以next(gen)时,代码将会执行到 for element in it:这行,而此时的迭代器it 已经指到iterable的第二个元素,OK,相信你懂了!
3 漏斗筛选
它是compress 函数,功能类似于漏斗功能,所以我称它为漏斗筛选,原型:
compress(data, selectors)

容易看出,compress返回的元素个数等于两个参数中较短的列表长度。
它的大概实现代码:

这个函数非常好用
4 段位筛选
扫描列表,不满足条件处开始往后保留,原型如下:
dropwhile(predicate, iterable)
应用例子:

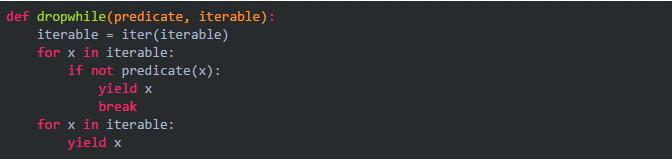
实现它的大概代码如下:

关注“AIU人工智能”公众号,回复“白皮书”获取数据分析、大数据、人工智能行业白皮书及更多精选学习资料!













 京公网安备 11010802022788号
京公网安备 11010802022788号







