


 雷达卡
雷达卡



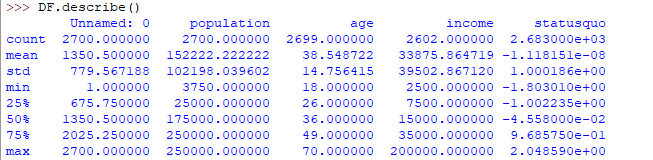
描述性统计信息是了解数据特征并快速汇总数据的有用方法。python中的pandas提供了一个有趣的方法describe()。describe函数对数据集应用基本统计计算,如极值,数据点标准偏差等。自动跳过任何缺失值或NaN值。describe()函数给出了数据分布的大致情况。
DF.describe()
这是在代码上运行时输出的输出:
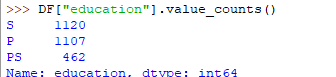
另一个有用的方法,如果value_counts()可以计算分类属性值系列中每个类别的计数。例如,假设您正在处理客户数据集,这些客户在列名称年龄下划分为年轻,中等和旧类别,而您的数据框架为“DF”。您可以运行此语句以了解有多少人属于各自的类别。在我们的数据集示例中,可以使用教育列
DF["education"].value_counts()
上面代码的输出将是:
另一个有用的工具是boxplot,您可以通过matplotlib模块使用它。Boxplot是数据分布的图形表示,显示极值,中位数和四分位数。我们可以通过使用箱线图轻松找出异常值。现在考虑我们再次处理的数据集,并绘制属性总体的箱线图
import pandas as pd
import matplotlib.pyplot as plt
DF = pd.read_csv("https://raw.githubusercontent.com / fivethirtyeight / data / master / airline-safety / airline-safety.csv")
y = list(DF.population)
plt.boxplot(y)
plt.show()

 京公网安备 11010802022788号
京公网安备 11010802022788号







