


 雷达卡
雷达卡






[后Transformer时代]DeepMind/KAIST新作-混合递归Mixture-of-Recursions原理解读及初步分析
推荐理由
传统基于Transformer的模型存在计算和存储开销高带来的性能问题,每个attention block都需要储存像Q,K,V,Attn Matrix,MLP权重等大量的矩阵,并进行相关的计算。有鉴于此,DeepMind, Google Research联合KAIST基于他们之前提出了Mixture of Depth (MoD),提出了采用混合式递归复用的方法,在减少attention block的同时,保证推理输出质量和全量模型持平,甚至更好。MoR的方法主要贡献有2点:1)路由机制将tokens按照语意重要度分配到不同的blocks,避免n^2的复杂度;2)KV-cache的缓存策略,支撑循环路由机制。
正文
技术解读摘要:通过层复用策略、tokens分层过滤、KV cache一致性保障减少计算量及模型参数大小,实验结果表明MoR性能表现持平或优于基于传统Transformer架构的模型。
先说结论:外网上有很多声音,把MoR称为Transformer的替代,从技术角度分析,MoR还是没有走出Transformer的注意力机制等经典方法,说是替代可能还太早,但是MoR创造性的采用递归、层重用等机制节省计算和存储,将算力放在重要的Tokens上。 实验显示,在相同计算预算及训练数据的前提下,MoR能比传统Transformer节省大约25%的内存需求(外网说能减少50% KV存储开销),训练时间减少19%,整体节省了25%左右的计算开销,但是模型few-shot accuracy要优于传统Transformer结构的模型。
第一节 当前transformer的架构的模型有什么问题
当前的Transformer架构在训练和部署大型语言模型时面临几个主要问题:
计算和内存需求高:每一层的 Self-Attention 操作的复杂度是 O(nd)(其中n是序列长度,d是嵌入维度),当序列较长时计算量急剧上升。
通讯开销高: 大模型分布式训练(如ZeRO、Pipeline并行)中,层与层之间或参数同步带来显著通信延迟。
冗余的内存访问和计算:标准Transformer在进行注意力计算时面临二次计算的开销,同时也会导致冗余的内存访问,这导致资源的浪费和效率的降低,虽然有KV-Cache这样的机制,但是存算开销依然很大。
显存带宽瓶颈: LayerNorm、QKV投影、Feedforward MLP层频繁调用内存,存在带宽瓶颈。
有鉴于此,AI研究社区在推进Transformer架构优化的同时,同时也在积极寻找Transformer的替代,像Mamba这样的SSM就是很好的一个实例(后面计划出一个专题)。除了激进型的方法,也包括循序渐进式的,例如这次介绍的Mixture-of-Recursions框架我认为就是属于后者。
第二节 MoR核心机制
为了解决上述问题,MoR采用了推理层复用的办法,其实这个想法也是基于DeepMind 2024年的一篇文章,Mixture of Depth,核心思想是尽量把算力放在重要的Token上,提出Top-k路由机制。在这个基础上,MoR引入了两个核心方法:1)通过路由策略将Token分配到特定的层,进行递归推理,增加权重的复用率;2)通过KV-Cache策略保证KV-Cache的前后一致性。
2.1 路由策略
作者一共讨论了两种Token路由的方法,Expert-choice routing和Token-choice Routing。实验结果看专家路由的方法的效果要优于后者,下面对前者进行详细分析,感兴趣的同学可以自己去看Token-Choice routing方法。
在expert-choice routing中,每个递归深度被视为一个“专家”,该专家选择其偏好的前k个Tokens。具体来说,在每个递归步骤r中,对应的路由使用当前递归块的输入隐藏状态H_t^r和其路由参数Theta_{r}来计算Token t的得分。然后,选择得分最高的前k个令牌通过递归块。
用简单的话说就是每一个transformer block都是一个专家,都有一个路由参数,路由参数决定了那些Tokens可以进入下一个专家。这些进如下一轮的Tokens(Top-k)被认为语意上的重要性要高于被过滤掉的Tokens (文章中称为分层过滤)
然而,expert-choice routing存在一个关键问题:在训练过程中,top-k选择操作需要对后续序列中出现的Token的信息进行访问,这违反了自回归推理中的因果关系。这种非因果依赖可能导致模型推理时的不确定性,从而降低模型的可靠性。为了缓解这个问题,采用了两种方法:辅助路由器(auxiliary router)和辅助损失(auxiliary loss)。辅助路由器是一个轻量化的网络,在推理时使用,预测Token是否会进入top-k选择。辅助损失则是对主路由器施加的损失,促使其在训练期间学习将top-k令牌推向1的同时,推动其他Token接近0,从而提高推理时的准确性。
2.2 KV Cache策略
作者提出了两种KV-Cache策略,目的在于优化递归Transformer计算过程中的内存使用:
递归方式缓存(Recursion-wise Caching):这种策略为每个递归步骤保持单独的本地KV缓存,确保仅关注当前递归块生成的KV对,从而在降低内存和计算成本的同时保持模型的准确性。
递归KV共享(Recursive KV Sharing):递归KV共享在第一个递归步骤计算KV对并在所有后续步骤中重复使用。虽然这种方法进一步减少了内存使用并消除了在预填充阶段必须计算更深递归的需要,但它可能会带来潜在的匹配问题,因为后续递归步骤收到的KV表示可能是为前一步骤准备的。这种不匹配可能会在Token路由精确时对模型性能产生负面影响。
第三节 实验结果分析
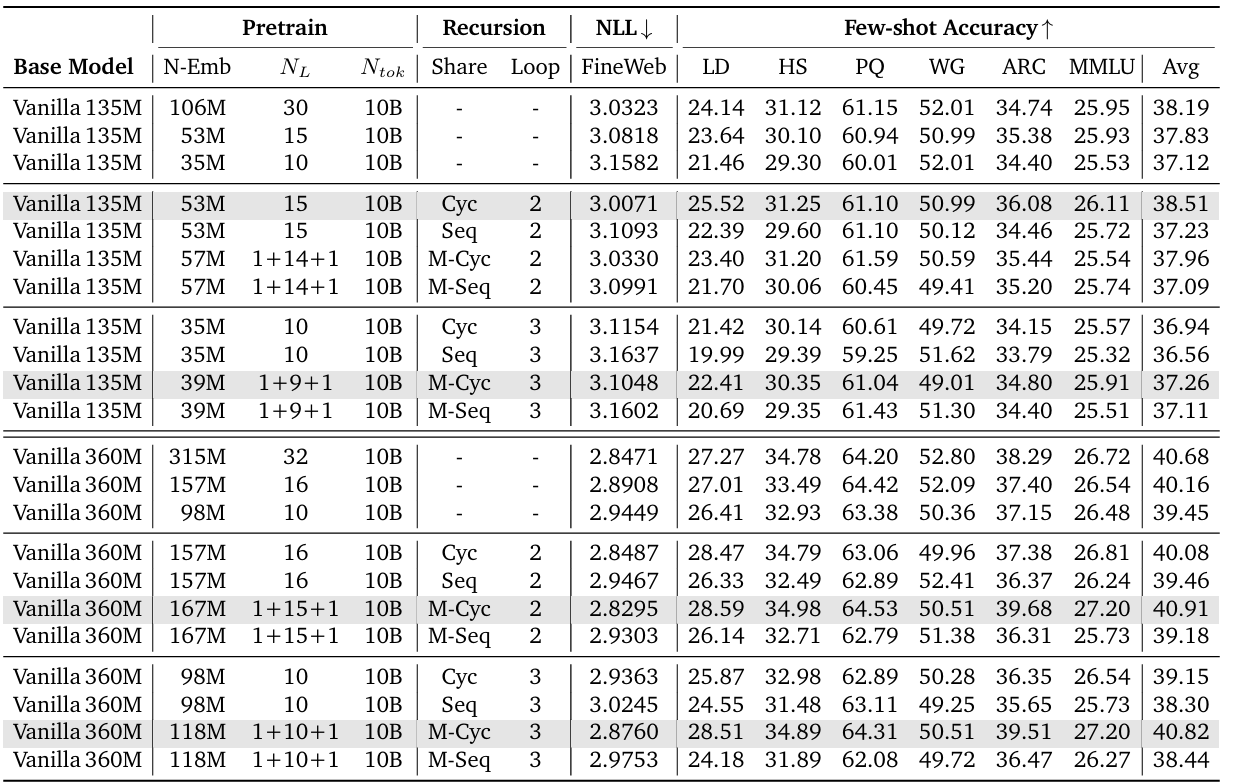
模型规模和参数共享策略:比较了不同模型规模(135M 和 360M)及不同递归深度(NR = 2 和 NR = 3)下的参数共享策略(如 Cycle、Sequence、Middle-Cycle 和 Middle-Sequence)。结果显示,Middle-Cycle 策略在负对数似然(NLL)和平均任务准确率上均表现优异,特别是在较高的递归深度时。
IsoFLOP分析:IsoFLOP 分析中评估了不同计算预算下的负对数似然(NLL)和几个下游任务的少量样本准确率。结果表明,MoR 模型在多种模型规模下(如 135M、360M、730M 和 1.7B)表现出比传统模型更好的性能,尤其是在计算预算受到限制的情况下。
KV缓存策略:实验还考察了 KV 缓存共享策略的影响。通过参数共享和 KV 缓存共享的约束,MoR 在多个基准测试中显示了更低的 NLL 和更高的少量样本准确率,证明了其参数效率与计算效率的潜力。
总体而言,实验结果表明 MoR 框架在提高LLM的计算效率和性能方面具有显著优势,能够在保持低资源消耗的同时,实现更好的建模能力和更高的准确率。这些结果推动了在动态计算策略和有效语言建模技术领域的研究进展。
第四节 总结
1) MoR并不是破坏式的创新方法,而还是基于传统Transformer架构之上,是Transformer的优化演进,借鉴了recursive transformer、early existing、adaptive computation等大量先期研究成果。
2) 递归复用、Expert Routing策略的确能有效的提升计算效率,大幅度降低计算和存储开销。
3) 从层的递归复用的有效性可以推测,基于传统Transformer的LLM存在大量的冗余参数,除了撑大模型尺度,对于模型质量可能贡献不大。
4) 开个脑洞:如果我们可以把省下的算力投资到test-time scaling上是否会带来更好的结果?对于计算infrastructure来说,会不会带来比较大的影响?
5) 在我们相信LLM大力出奇迹的当前,需要考虑怎么把力气使用在对的地方,把计算的蛮力化成巧力。
学习入口:https://edu.cda.cn/goods/show/3814?targetId=6587&preview=0
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !






 京公网安备 11010802022788号
京公网安备 11010802022788号







