


 雷达卡
雷达卡



本文围绕 Rust 基础语法规则展开,涵盖变量、数据类型、函数、控制流程等核心概念,还介绍了所有权、结构体、枚举、模式匹配、错误处理、生命周期及重影等内容。Rust 是一种强类型和静态类型的编程语言,变量默认不可变,需要使用
mut 变量、基础类型、函数、注释及控制流程——这些概念几乎在所有编程语言中都是“通用配置”。而在 Rust 里,这些基础知识会贯穿每一个程序的编写过程,早点掌握它们,后续学习 Rust 就能少走很多弯路,上手速度也会更快。
一、变量
首先需要明确的是,Rust 是一种强类型语言,但它有一个便利的特点:可以自动判断变量类型。这一点很容易让人误以为它是弱类型语言,实际上却并非如此。
此外,Rust 中的变量默认是“不可变”的,如果希望变量能够更改值,必须使用
变量、基础类型、函数、注释及控制流程——这些概念几乎在所有编程语言中都是“通用配置”。而在 Rust 里,这些基础知识会贯穿每一个程序的编写过程,早点掌握它们,后续学习 Rust 就能少走很多弯路,上手速度也会更快。
一、变量
首先需要明确的是,Rust 是一种强类型语言,但它有一个便利的特点:可以自动判断变量类型。这一点很容易让人误以为它是弱类型语言,实际上却并非如此。
此外,Rust 中的变量默认是“不可变”的,如果希望变量能够更改值,必须使用
mutlet a = 123; // 不可变变量,值定了就改不了
let mut b = 10; // 可变变量,后续能改它的值letlet a = 123;a = "abc";
a = 4.56;
a = 456;aaaaamutlet mut a = 123;
a = 456;let a = 123;
let a = 456;aconst a: i32 = 123;
let a = 456; // 报错,常量不能这么重新定义let a: u64 = 123;aa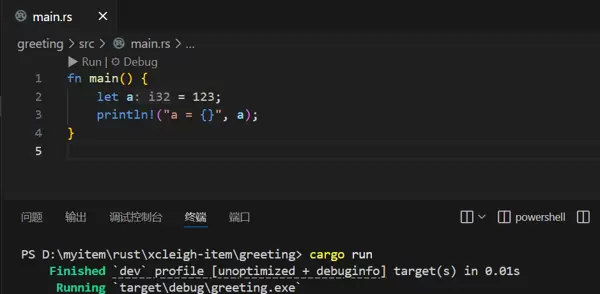 二、数据类型
之前也提到过,Rust 是静态类型语言——在变量声明时可以明确指定类型,不过大多数时候不需要麻烦,依靠其类型推断功能即可。
常用的基础类型有以下几种:
二、数据类型
之前也提到过,Rust 是静态类型语言——在变量声明时可以明确指定类型,不过大多数时候不需要麻烦,依靠其类型推断功能即可。
常用的基础类型有以下几种:
i32u32f64boolcharlet x: i32 = 42; // 32位有符号整数,值是42
let y: f64 = 3.14; // 64位浮点数,值是3.14
let is_true: bool = true; // 布尔类型,值是true
let letter: char = 'A'; // 字符类型,值是'A'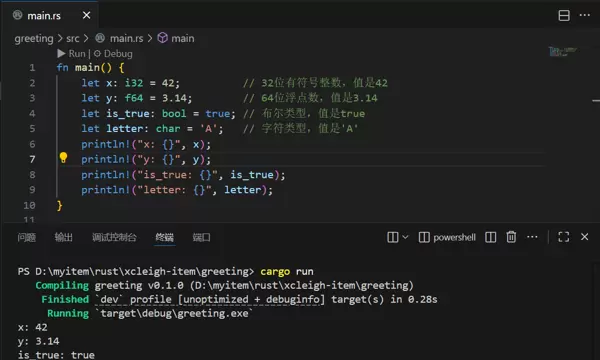 三、函数
在 Rust 中定义函数时需使用
三、函数
在 Rust 中定义函数时需使用
fn->fn add(a: i32, b: i32) -> i32 {
a + b // 函数返回值,不用写return,最后一行表达式的结果就是返回值
}()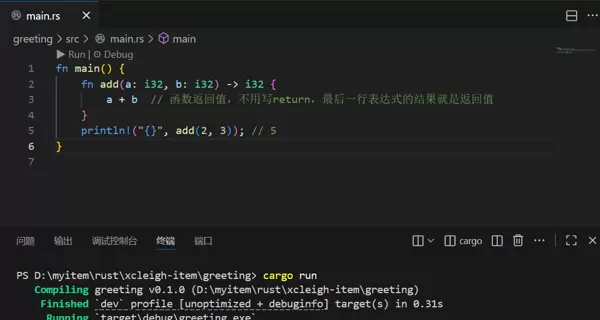 四、控制流程
控制流就是程序执行的路径,Rust 中常用的有 if 表达式、loop 循环、while 循环和 for 循环。我们逐一来看。
if 表达式
四、控制流程
控制流就是程序执行的路径,Rust 中常用的有 if 表达式、loop 循环、while 循环和 for 循环。我们逐一来看。
if 表达式if 表达式用于进行“分支判断”,例如判断一个数值的大小:
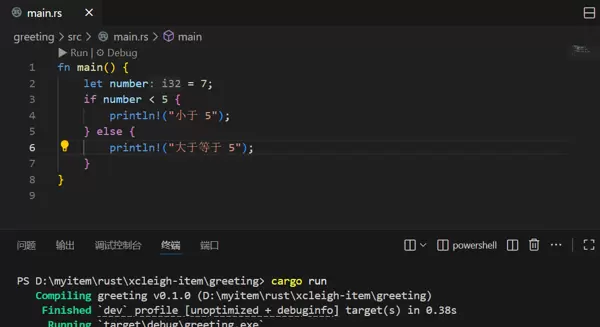
let number = 7;
if number < 5 {
println!("小于 5");
} else {
println!("大于等于 5");
}这里 number 是 7,超过 5,因此会显示“大于等于 5”。
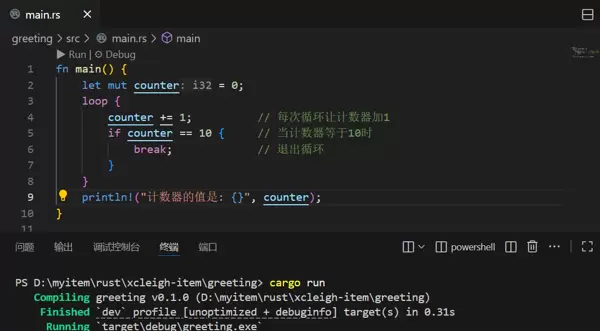
loop 循环
loop 是 Rust 中的“无限循环”,如果不主动终止,它将一直运行。要退出循环,可以使用
break关键字。例如,编写一个计数器:
let mut counter = 0;
loop {
counter += 1; // 每次循环让计数器加1
if counter == 10 { // 当计数器等于10时
break; // 退出循环
}
}这段代码执行后,counter 会从 0 增加到 10,之后循环停止。
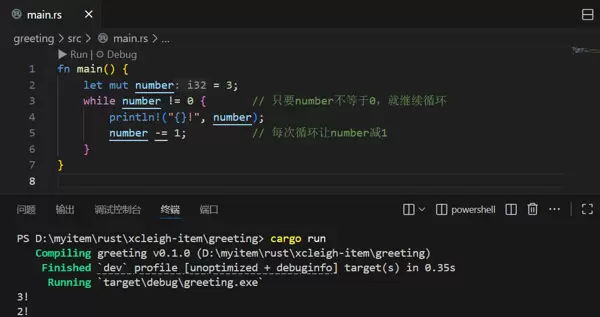
while 循环
while 循环适用于“条件满足时继续运行”的场景,当条件不再满足时退出。例如倒计时:
let mut number = 3;
while number != 0 { // 只要number不等于0,就继续循环
println!("{}!", number);
number -= 1; // 每次循环让number减1
}执行后会依次显示“3!”“2!”“1!”,直到 number 变成 0,循环结束。
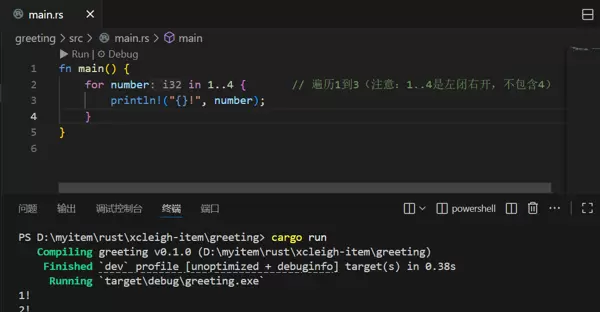
for 循环
for 循环在遍历序列时非常方便,例如遍历一个范围:
for number in 1..4 { // 遍历1到3(注意:1..4是左闭右开,不包含4)
println!("{}!", number);
}这段代码会显示“1!”“2!”“3!”,简洁且不易出错,比手动控制计数器更加便捷。
五、所有权(Ownership)
所有权是 Rust 独特的内存管理机制,也是其核心特性之一。要理解所有权,需要先了解三个关键概念:所有权(ownership)、借用(borrowing)和引用(reference)。
所有权规则
Rust 中每个值都有一个“所有者”——即哪个变量持有该值。
每个值在同一时间只能有一个所有者,不能多个同时拥有。
当所有者超出其“作用域”(如函数执行完毕、代码块结束),该值将被自动删除,释放内存。
例如:
let s1 = String::from("hello");
let s2 = s1; // 这里s1的所有权被“转移”给了s2,s1再也不能用了
// println!("{}", s1); // 这里编译会报错,因为s1已经没有这个值的所有权了借用和引用
如果不想转移所有权,只是临时使用某个值,该怎么办?这时就需要“借用”。借用允许你引用数据,但不获取所有权,通过
&符号即可实现。
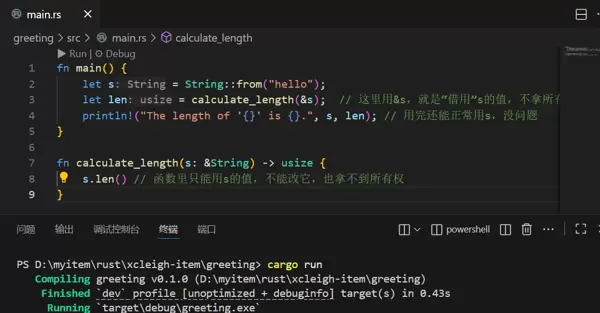
例如编写一个计算字符串长度的函数:
fn main() {
let s = String::from("hello");
let len = calculate_length(&s); // 这里用&s,就是“借用”s的值,不拿所有权
println!("The length of '{}' is {}.", s, len); // 用完还能正常用s,没问题
}
fn calculate_length(s: &String) -> usize {
s.len() // 函数里只能用s的值,不能改它,也拿不到所有权
}
六、结构体(Structs)
结构体的作用是“创建自定义类型”,其字段可以包含多种不同的数据类型,非常适合描述具有多个属性的事物。
例如定义一个“用户”结构体:
struct User {
username: String, // 用户名,字符串类型
email: String, // 邮箱,字符串类型
sign_in_count: u64, // 登录次数,无符号64位整型
active: bool, // 是否活跃,布尔类型
}
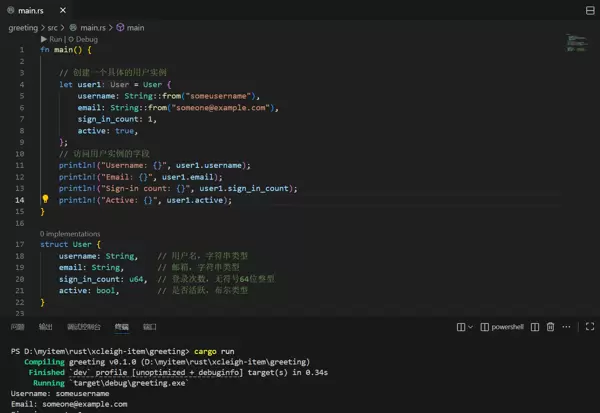
// 创建一个具体的用户实例
let user1 = User {
username: String::from("someusername"),
email: String::from("someone@example.com"),
sign_in_count: 1,
active: true,
};这样一来,user1 就是一个 User 类型的变量,包含了所有用户信息,使用起来非常清晰。
七、枚举(Enums)
枚举的作用是定义“一个值可能是几种类型中的一种”,不需要像结构体那样包含多个字段,更适合描述不同的选项。
例如定义 IP 地址的类型(IPv4 和 IPv6):
enum IpAddrKind {
V4, // IPv4类型
V6, // IPv6类型
}
// 创建枚举实例
let four = IpAddrKind::V4; // four是IpAddrKind::V4类型
let six = IpAddrKind::V6; // six是IpAddrKind::V6类型这样可以明确区分不同的 IP 类型,在后续处理时不容易混淆。
八、模式匹配(match)
match 是 Rust 中特别强大的控制流工具,类似于其他语言中的 switch 语句,但功能更强大。它可以帮你“匹配”枚举的不同类型,并执行相应的代码。
例如定义一个“硬币”枚举,然后编写一个函数计算硬币的面值:
enum Coin {
Penny, // 1美分硬币
Nickel, // 5美分硬币
Dime, // 10美分硬币
Quarter, // 25美分硬币
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1, // 匹配到Penny,返回1
Coin::Nickel => 5, // 匹配到Nickel,返回5
Coin::Dime => 10, // 匹配到Dime,返回10
Coin::Quarter => 25, // 匹配到Quarter,返回25
}
}调用该函数时,传入不同的 Coin 实例,可以得到对应的面值,逻辑非常清晰。
九、错误处理
在 Rust 中处理错误主要依靠两种方式:
Result<T, E>和
Option<T>。它们能帮助你明确处理“可能出错”的情况,避免程序崩溃。
Result
Result<T, E>是一个枚举,专门用于表示“操作成功”或“操作失败”。T 是成功时返回的值类型,E 是失败时返回的错误类型。其定义大致如下:
enum Result<T, E> {
Ok(T), // 成功,里面存着成功的值
Err(E), // 失败,里面存着错误信息
}例如编写一个除法函数,如果除数为 0 则返回错误:
fn divide(a: i32, b: i32) -> Result<i32, String> {
if b == 0 {
Err(String::from("Division by zero")) // 除数为0,返回错误信息
} else {
Ok(a / b) // 计算成功,返回结果
}
}Option
Option<T>也是一个枚举,用于表示“有值”或“没值”,避免出现空指针错误。其用法非常简单,例如编写一个“从数组中取元素”的函数:
fn get_element(index: usize, vec: &Vec<i32>) -> Option<i32> {
if index < vec.len() {
Some(vec[index]) // 索引合法,返回“有值”,里面存着数组元素
} else {
None // 索引越界,返回“没值”
}
}调用该函数时,可以清楚地知道是否获取到了元素,无需猜测。
十、所有权与借用的生命周期
前面介绍了借用和引用,但还有一个问题:如何确保引用始终“有效”,不会出现“引用了一个已被删除的值”的情况?这就需要“生命周期”了。
Rust 使用生命周期标注来管理引用的有效性。标注时使用
'a这样的符号。不过大多数情况下不需要手动编写,编译器会自动推断。
例如编写一个“返回两个字符串中较长的那个”的函数:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}这里的
'a就是生命周期标注,它告诉编译器:x、y 这两个引用以及函数的返回值具有相同的生命周期。这样编译器就能确保,返回的引用不会在 x 或 y 被删除后继续使用。
十一、重影(Shadowing)
最后我们讨论“重影”。它与面向对象语言中的“重写”(Override)或“重载”(Overload)完全不同。前面提到的“变量重新绑定”,指的就是重影——简单来说,就是同一个变量名可以被重新使用,表示另一个变量。
例如:
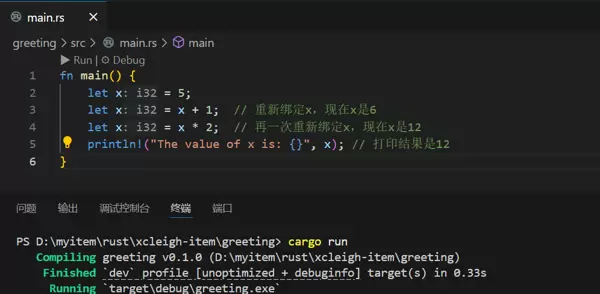
fn main() {
let x = 5;
let x = x + 1; // 重新绑定x,现在x是6
let x = x * 2; // 再一次重新绑定x,现在x是12
println!("The value of x is: {}", x); // 打印结果是12
}这段程序运行后,输出结果是“The value of x is: 12”。
这里要注意,重影和“可变变量赋值”不是一回事。重影是“用同一个名字重新表示另一个变量”,新变量的类型、是否可变、值都能改变;但可变变量赋值只能改“值”,类型和可变属性则不能变动。
例如下面这段代码就会报错:
let mut s = "123"; // s是可变字符串变量
s = s.len(); // 报错!不能给字符串变量赋整型值s 本来是字符串类型,即使加了
mut能改值,也不能把
s.len()(整型)赋值给它——类型不匹配。重影能做的事情,可变变量却做不到。
十二、总结
到这里,我们已经把 Rust 最核心的基础语法过了一遍。从变量的“可变与不可变”设计,到数据类型的精确区分;从函数的定义逻辑,到控制流的灵活应用;再到 Rust 独有的所有权、借用、生命周期,以及自定义类型的结构体与枚举——这些内容不仅是孤立的知识点,更是构成 Rust 安全、高效特性的基石。
例如变量默认不可变与所有权机制,本质上是 Rust 从语言层面帮助我们规避并发安全和内存泄漏问题;重影与可变变量的区别、模式匹配的灵活用法,则体现了它在“严谨性”和“易用性”之间的平衡。而错误处理的 Result 和 Option 枚举,更是让我们能写出更健壮、可维护的代码,避免了很多隐性 bug。
这些基础概念就像搭建房子的砖块,刚开始接触时可能会觉得“规矩有点多”,比如所有权转移、生命周期标注等设计,与其他语言的习惯不太相同。但只要多动手写代码、多琢磨每段代码背后的逻辑,慢慢就能体会到这些设计的巧妙之处。后续再学习 Rust 更复杂的特性(如并发、Trait、泛型等)时,你会发现这些基础打得越牢,上手后续内容就越轻松。因此建议大家把这些基础语法多练几遍,用小例子验证每个知识点,真正吃透它们,再往下进阶就会顺理成章啦!

 京公网安备 11010802022788号
京公网安备 11010802022788号







