


 雷达卡
雷达卡



理解 ForkJoinPool 的重要性及其应用
本文将通过一个简单示例,解析为何需要 ForkJoinPool。随后,我们将探讨 ForkJoinPool 的基本信息及其使用方法,最后深入分析 ForkJoinPool 的工作原理。
创建背景
在线程池的选择上,我们通常倾向于使用 ThreadPoolExecutor 来提高任务处理的效率。大多数情况下,使用 ThreadPoolExecutor 时,各任务间相互独立。然而,在特定情境下,任务间存在依赖关系,比如经典的 Fibonacci 序列问题。
Fibonacci 序列的特点是 F(N) = F(N-1) + F(N-2),这意味着每个数值的计算都依赖于后续数值的结果。这种情况下,ThreadPoolExecutor 并非最佳选择。尽管可以通过单线程递归算法来计算,但这不仅速度慢,而且无法充分利用多核 CPU 的优势。
ForkJoinPool 正是为了应对这种有依赖关系的并行计算任务而设计的。它适用于类似快速排序、二分查找、集合运算等需要处理父子任务依赖的并行计算问题。例如,使用 ForkJoinPool 实现 Fibonacci 序列的代码如下:
@Slf4j
public class ForkJoinDemo {
// 1. 运行入口
public static void main(String[] args) {
int n = 20;
// 为了追踪子线程名称,需要重写 ForkJoinWorkerThreadFactory 的方法
final ForkJoinPool.ForkJoinWorkerThreadFactory factory = pool -> {
final ForkJoinWorkerThread worker = ForkJoinPool.defaultForkJoinWorkerThreadFactory.newThread(pool);
worker.setName("my-thread" + worker.getPoolIndex());
return worker;
};
//创建分治任务线程池,可以追踪到线程名称
ForkJoinPool forkJoinPool = new ForkJoinPool(4, factory, null, false);
// 快速创建 ForkJoinPool 方法
// ForkJoinPool forkJoinPool = new ForkJoinPool(4);
//创建分治任务
Fibonacci fibonacci = new Fibonacci(n);
//调用 invoke 方法启动分治任务
Integer result = forkJoinPool.invoke(fibonacci);
log.info("Fibonacci {} 的结果是 {}", n, result);
}
}
// 2. 定义拆分任务,写好拆分逻辑
@Slf4j
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
public Integer compute() {
//和递归类似,定义可计算的最小单元
if (n <= 1) {
return n;
}
// 想查看子线程名称输出的可以打开下面注释
//log.info(Thread.currentThread().getName());
Fibonacci f1 = new Fibonacci(n - 1);
// 拆分成子任务
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
// f1.join 等待子任务执行结果
return f2.compute() + f1.join();
}
}上述代码中,我们创建了一个继承自 RecursiveTask 抽象类的 Fibonacci 类,定义了任务的拆分逻辑,并通过调用 join() 方法等待子任务的完成。执行此程序后,可以得到如下结果:
17:29:10.336 [main] INFO tech.shuyi.javacodechip.forkjoinpool.ForkJoinDemo - Fibonacci 20 的结果是 6765这里使用的 fork() 和 join() 方法是 ForkJoinPool 提供的关键接口,分别用于启动子任务和等待子任务的返回结果。
应用案例
除了处理有依赖关系的任务外,ForkJoinPool 还能应用于需要收集子任务结果的场景。例如,要计算 1 至 1 亿的总和,为了加速计算过程,可以采用分治策略,将 1 亿个数字划分为 1 万个子任务,每个子任务负责计算 1 万个数字的总和,从而利用多核 CPU 的并行计算能力减少计算时间。
虽然 ThreadPoolExecutor 也能通过 Future 接口获取任务执行结果,但 ForkJoinPool 在这方面提供了更简洁的解决方案。接下来,我们将分别使用 ThreadPoolExecutor 和 ForkJoinPool 来实现这一计算任务,以便比较两者之间的差异。
不论采取哪种方式,基本思路都是相同的:根据线程池中的线程数量 N,将 1 亿个数字均匀分割成 N 份,然后分配给线程池处理。每个子任务使用 Future 接口获取其计算结果,最后汇总所有子任务的结果。
首先,我们尝试使用 ThreadPoolExecutor 来实现这个任务。为此,我们定义了一个名为 Calculator 的接口,用于描述计算总和的行为,具体实现如下所示:
public interface Calculator {
/**
* 把传进来的所有numbers 做求和处理
*
* @param numbers
* @return 总和
*/
long sumUp(long[] numbers);
}接下来,我们定义了一个使用 ThreadPoolExecutor 线程池的类,其实现细节如下:
package tech.shuyi.javacodechip.forkjoinpool;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class ExecutorServiceCalculator implements Calculator {
private int parallism;
private ExecutorService pool;
public ExecutorServiceCalculator() {
// CPU的核心数 默认就用cpu核心数了
parallism = Runtime.getRuntime().availableProcessors();
pool = Executors.newFixedThreadPool(parallism);
}
// 1. 处理计算任务的线程
private static class SumTask implements Callable<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
public Long call() {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
}
}
// 2. 核心业务逻辑实现
@Override
public long sumUp(long[] numbers) {
List<Future<Long>> results = new ArrayList<>();
// 2.1 数字拆分
// 把任务分解为 n 份,交给 n 个线程处理 4核心 就等分成4份呗
// 然后把每一份都扔个一个SumTask线程 进行处理
int part = numbers.length / parallism;
for (int i = 0; i < parallism; i++) {
int from = i * part; //开始位置
int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1; //结束位置
//扔给线程池计算
results.add(pool.submit(new SumTask(numbers, from, to)));
}
// 2.2 阻塞等待结果
// 把每个线程的结果相加,得到最终结果 get()方法 是阻塞的
// 优化方案:可以采用CompletableFuture来优化 JDK1.8的新特性
long total = 0L;
for (Future<Long> f : results) {
try {
total += f.get();
} catch (Exception ignore) {
}
}
return total;
}
}如上所述,我们实现了一个名为 SumTask 的类,用于计算单个任务的总和。在 sumUp() 方法中,我们将 1 亿个数字分割成多个子任务,提交给线程池处理,并最终汇总这些子任务的结果。
运行上述代码,可以成功获得最终结果,如下所示:
耗时:10ms
结果为:50000005000000现在,让我们使用 ForkJoinPool 来实现同样的功能。我们首先创建一个继承自 RecursiveTask 的 SumTask 类,并在 compute() 方法中定义任务的拆分逻辑和计算过程。最后,在 sumUp() 方法中调用 pool 方法执行计算,具体代码如下:
public class ForkJoinCalculator implements Calculator {
private ForkJoinPool pool;
// 1. 定义计算逻辑
private static class SumTask extends RecursiveTask<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
//此方法为ForkJoin的核心方法:对任务进行拆分 拆分的好坏决定了效率的高低
@Override
protected Long compute() {
// 当需要计算的数字个数小于6时,直接采用for loop方式计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else {
// 否则,把任务一分为二,递归拆分(注意此处有递归)到底拆分成多少分 需要根据具体情况而定
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
public ForkJoinCalculator() {
// 也可以使用公用的线程池 ForkJoinPool.commonPool():
// pool = ForkJoinPool.commonPool()
pool = new ForkJoinPool();
}
@Override
public long sumUp(long[] numbers) {
Long result = pool.invoke(new SumTask(numbers, 0, numbers.length - 1));
pool.shutdown();
return result;
}
}运行以上代码,得到的结果为:
耗时:860ms
结果为:50000005000000通过对比 ThreadPoolExecutor 和 ForkJoinPool 的实现,可以看出两者都包含了任务拆分和结果汇总的逻辑。不过,ForkJoinPool 在实现上做了更多的封装,例如:
- 无需手动获取子任务的结果,可以直接使用 join() 方法。
- 任务拆分的逻辑被封装在 RecursiveTask 的子类中,而非暴露在外。
因此,即使在没有父子任务依赖的情况下,只要需要获取子任务的执行结果,也可以考虑使用 ForkJoinPool。这样做不仅简化了代码实现,还提高了封装的质量。
使用方法
利用 ForkJoinPool 进行并行计算,主要涉及以下两个步骤:
- 定义继承自 RecursiveTask 或 RecursiveAction 的任务子类。
- 初始化线程池及计算任务,将其提交给线程池处理,并获取处理结果。
首先,我们要创建一个继承自 RecursiveTask 或 RecursiveAction 的子类,在这个子类的 compute() 方法中明确任务分解和计算的逻辑。
这两个抽象类的主要区别在于:RecursiveTask 类会返回一个结果,而 RecursiveAction 类则不会。例如,之前讨论过的从 1 累加至 1 亿的问题,我们定义了一个 SumTask 类来实现 RecursiveTask,其代码如下:
private static class SumTask extends RecursiveTask<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
// 1. 定义拆分退出逻辑
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else {
// 2. 定义计算逻辑
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}compute() 方法的关键在于确定如何将大任务分解成多个小任务,以及何时停止分解。
接下来,我们需要初始化 ForkJoinPool 线程池,创建计算任务实例,最后将任务提交给线程池执行。
// 初始化线程池
public ForkJoinCalculator() {
pool = new ForkJoinPool();
}
// 初始化计算任务,将任务丢入线程池
public long sumUp(long[] numbers) {
Long result = pool.invoke(new SumTask(numbers, 0, numbers.length - 1));
pool.shutdown();
return result;
}通过上述步骤,我们就完成了 ForkJoinPool 任务的基本编写。
原理分析
ForkJoinPool 的核心理念是分治法,即不断地将任务分割(fork)成更小的部分,直到这些小部分可以被独立处理,然后将它们的结果合并(join)。这种方法能够最大化地利用 CPU 资源,配合工作窃取算法(work-stealing)进一步提升整体性能。下面的流程图展示了这一过程:

图示来源:思否用户「日拱一兵」
从图中可以看到,ForkJoinPool 必须先完成所有子任务,然后才能继续处理上一级任务。因此,ForkJoinPool 特别适用于存在父子任务依赖关系的场景,或者是需要收集子任务执行结果的情况,如 Fibonacci 序列、快速排序和二分查找等。
源码实现
ForkJoinPool 的主要实现依赖于 ForkJoinPool 类和 ForkJoinTask 抽象类。ForkJoinTask 继承了 Future 接口,允许我们获取任务的处理结果。它有两个抽象子类:RecursiveAction 和 RecursiveTask,它们的区别在于前者不返回任何结果,而后者会返回结果,具体类图如下所示:
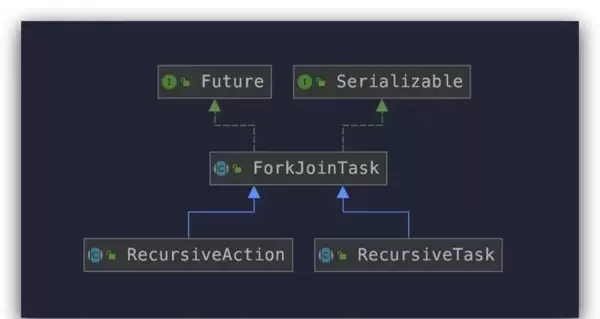
图示来源:思否用户「日拱一兵」
至于 ForkJoinPool 的内部实现细节,由于目前没有具体的应用场景,这里不做深入探讨。有兴趣的朋友可以查阅这篇文章:ForkJoinPool 大型图文现场(一阅到底 vs 直接收藏) - SegmentFault 思否。
工作窃取算法
既然 ForkJoinPool 的父子任务间存在依赖,那么它是如何协调这些任务的执行顺序呢?答案在于使用不同的任务队列来执行任务。
ForkJoinPool 内部包含一个名为 workQueue[] 的数组成员,代表一系列的任务队列,每个队列对应一个消费者线程。当任务被提交到线程池时,它们会根据一定的规则被分配到这些队列中。
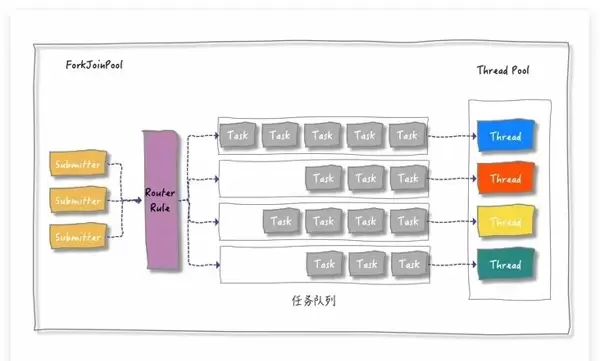
图示来源:思否用户「日拱一兵」
然而,这种分配方式可能导致某些队列中的任务过多,而其他队列的任务较少,造成各线程之间的负载不均衡,影响整体效率。为解决这一问题,引入了工作窃取算法,即空闲的线程会从其他队列的尾部“窃取”任务到自己的队列中进行处理。
通常情况下,线程从自己的队列中获取任务遵循 LIFO(Last In First Out,后进先出)原则,类似于栈的操作。如图所示,任务首先被推送到队列的顶端(top),随后从顶端弹出并执行。
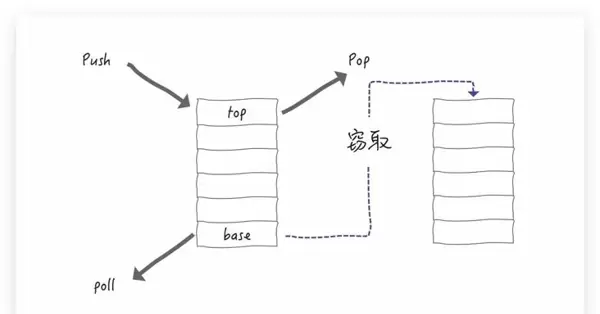
图示来源:思否用户「日拱一兵」
当某个线程的队列为空时,该线程会尝试从其他队列的底部(base)“窃取”任务到自己的队列中执行。选择从底部而非顶部获取任务的原因是为了避免多线程间的冲突。如果两个线程同时尝试从顶部获取任务,可能会发生并发冲突,需要加锁机制来解决,这将降低执行效率。

 京公网安备 11010802022788号
京公网安备 11010802022788号







