


 雷达卡
雷达卡



在大模型技术快速发展的当下,不少初学者在尝试本地部署时常常遇到一个实际难题:如何在硬件资源有限的情况下有效评估模型性能。高端GPU动辄数万元的价格让个人开发者难以承受,而盲目选用大型模型又极易导致系统卡顿、内存溢出等问题。正是基于这一现实背景,我们选择Qwen1.5-1.8B-Chat这款轻量级模型作为实践切入点——它不仅能在普通笔记本的CPU环境下稳定运行,仅需约4GB内存,更为新手提供了一个低门槛的学习平台。
本文将从实际应用角度出发,构建一套完整的大模型性能评估体系。通过具体的代码示例与直观的可视化分析,帮助读者系统掌握模型评估的核心方法。无论是推理速度的量化测试、内存占用的精准测量,还是对话质量的多维度评判,我们都将以通俗易懂的方式进行呈现。该评估框架不仅适用于Qwen系列模型,也可灵活迁移至其他开源模型,助力初学者真正迈入大模型技术实践的大门。
评估维度说明:
- 指标多样性:涵盖速度、质量、内存消耗及稳定性等关键性能指标
- 场景适配性:根据不同应用场景对模型能力提出差异化要求
- 资源约束:在硬件条件受限的前提下进行合理的性能权衡
二、基础性能指标分析
1. 推理速度测试
1.1 基本概念
推理速度是衡量大模型生成效率的关键指标,通常以tokens/秒为单位,表示模型每秒可生成的token数量。为了获得稳定可靠的测试结果,我们将进行多次重复实验,并综合考虑不同生成长度和批次大小的影响。
测试流程如下:
- 准备一组测试输入文本(可相同或不同)
- 记录每次调用模型generate方法前后的起止时间
- 根据输出序列与输入序列的长度差计算实际生成的token数
- 通过“生成token数 ÷ 耗时”得出单次生成速度
- 多次测试后取平均值与标准差,降低随机误差影响
为避免模型初始化带来的性能波动,测试前会先执行一次预热操作(不计入正式数据)。本次测试受限于设备配置,采用纯CPU环境,主要聚焦于单条文本生成任务。
实现细节说明:
- 使用
time.time()获取高精度时间戳 - 确保生成参数(如do_sample、temperature等)保持一致
- 因运行在CPU上,无需处理GPU异步执行相关问题
- 测试内容包括:不同生成长度(如50、100、200 tokens)下的响应速度
代码结构设计:
- 预热阶段:生成一段短文本,激活模型状态
- 主测试阶段:针对不同生成长度进行多轮采样,统计平均表现
import time
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
def load_model_and_tokenizer():
"""加载模型和分词器"""
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
print("正在加载模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=True,
padding_side='left',
truncation_side='right'
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map="cpu",
low_cpu_mem_usage=True
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
def test_inference_speed(model, tokenizer):
"""测试推理速度"""
print("=== 推理速度测试 ===")
test_texts = [
"介绍一下人工智能",
"写一个简短的故事",
"解释机器学习的基本概念"
]
speeds = []
for text in test_texts:
start_time = time.time()
inputs = tokenizer(text, return_tensors="pt", max_length=512, truncation=True)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
end_time = time.time()
time_taken = end_time - start_time
token_count = len(outputs[0]) - len(inputs['input_ids'][0])
speed = token_count / time_taken
speeds.append(speed)
print(f"文本: {text[:30]}...")
print(f"生成 {token_count} tokens, 耗时 {time_taken:.2f}s, 速度: {speed:.2f} tokens/s")
avg_speed = sum(speeds) / len(speeds)
print(f"\n平均生成速度: {avg_speed:.2f} tokens/秒")
return avg_speed
# 主函数:串联所有评估方法
def main():
# 1. 加载模型
print("步骤 1/2: 加载模型和分词器...")
model, tokenizer = load_model_and_tokenizer()
print("? 模型加载完成")
results = test_inference_speed(model, tokenizer)
return results
# 执行评估
if __name__ == "__main__":
main()1.3 实测输出结果
步骤 1/2: 加载模型和分词器... 正在加载模型... Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat 2025-11-19 13:43:59,181 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat]. 2025-11-19 13:43:59,181 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat. 模型加载完成 === 推理速度测试 === 文本: 介绍一下人工智能... 生成 100 tokens, 耗时 25.58s, 速度: 3.91 tokens/s 文本: 写一个简短的故事... 生成 100 tokens, 耗时 24.25s, 速度: 4.12 tokens/s 文本: 解释机器学习的基本概念... 生成 100 tokens, 耗时 23.62s, 速度: 4.23 tokens/s 平均生成速度: 4.09 tokens/秒
1.4 结果解读
根据官方文档中对Qwen1.5-1.8B模型的性能预期,在CPU环境下应能达到15–25 tokens/秒的生成速度。然而实测结果仅为4.09 tokens/秒,明显偏低。此差异可能源于以下原因:
- 测试期间存在其他后台进程占用系统资源
- 操作系统或Python环境未做性能优化
- 模型加载方式或推理参数设置不够高效
考虑到当前为非优化的默认运行环境,该速度虽偏低但仍具备可用性,后续可通过模型量化、缓存机制等方式进一步提升性能。
2. 内存占用监测
2.1 测量原理
内存使用情况是判断模型是否适合本地部署的重要依据。我们将利用Python中的psutil库实时监控系统RAM使用量;若使用GPU,则结合torch.cuda模块追踪显存(VRAM)变化。
由于本次测试已将模型加载至CPU,因此重点关注物理内存(RAM)的变化趋势。对于GPU用户,建议同步启用CUDA内存监控功能。
具体操作步骤:
- 记录模型加载前系统的初始内存占用
- 加载模型并再次读取内存使用值
- 计算前后差值,得到模型加载所增加的内存开销
- 在生成过程中持续监控内存峰值,评估最大资源需求
该方法能够准确反映模型在整个生命周期内的内存行为,为资源规划提供可靠依据。
三、模型能力评估
1. 语言理解能力
1.1 基础介绍
为实现系统化且便于操作的评估方式,我们采用一种简洁的方法:设定若干预定义的测试问题,并依据模型输出的回答质量进行打分。出于简化考虑,此处使用关键词匹配机制作为评分标准。
实施步骤如下:
- 构建一个测试数据集,每个样本包含:
- 提问内容(prompt)
- 期望出现的关键词列表(可设置为“至少匹配一个”或“必须全部匹配”)
- 针对每个问题,调用模型生成回复。
- 分析生成文本中是否包含预期关键词,并据此进行评分。
评分规则说明:
每个问题的回答若包含至少一个指定关键词,则记为1分;否则记为0分。虽然也可根据命中关键词的数量细化打分,但本方案采取最简形式以提升执行效率。
注意事项:
由于大模型输出具有一定的随机性,理想情况下应对每个问题多次采样并取平均结果。然而这会显著增加耗时。因此,在本次评估中,每个问题仅生成一次回答。为保证输出稳定性,统一固定生成参数(如 temperature=0.7 等)。
1.2 代码示例
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
# 首先加载模型
def load_model_and_tokenizer():
"""加载模型和分词器"""
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
print("正在加载模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=True,
padding_side='left',
truncation_side='right'
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map="cpu",
low_cpu_mem_usage=True
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
# 辅助函数:生成回复
def generate_response(model, tokenizer, prompt, max_length=200):
"""通用的回复生成函数"""
inputs = tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 移除输入部分,只保留生成的回复
if prompt in response:
response = response.replace(prompt, "").strip()
return response
# 3. 中文理解能力测试
def test_chinese_understanding(model, tokenizer):
"""测试中文理解能力"""
print("=== 中文理解能力测试 ===")
test_cases = [
{
"category": "语义理解",
"prompt": "这句话是什么意思:'他这是醉翁之意不在酒'",
"expected_keywords": ["真实意图", "表面", "实际目的", "另有目的"]
},
{
"category": "逻辑推理",
"prompt": "如果所有猫都喜欢鱼,而咪咪是一只猫,那么咪咪喜欢什么?",
"expected_keywords": ["鱼", "喜欢"]
},
{
"category": "上下文理解",
"prompt": "小明说:'我昨天去了北京。' 小红问:'你去哪里了?' 小明回答:",
"expected_keywords": ["北京"]
}
]
scores = []
for case in test_cases:
response = generate_response(model, tokenizer, case["prompt"])
print(f"\n[{case['category']}]")
print(f"问题: {case['prompt']}")
print(f"回答: {response}")
# 简单关键词匹配评分
keyword_score = sum(1 for keyword in case["expected_keywords"] if keyword in response)
score = keyword_score / len(case["expected_keywords"])
scores.append(score)
print(f"匹配度: {score:.2f}")
avg_score = sum(scores) / len(scores)
print(f"\n中文理解平均得分: {avg_score:.2f}/1.0")
return avg_score
def main():
# 1. 加载模型
print("步骤 1/2: 加载模型和分词器...")
model, tokenizer = load_model_and_tokenizer()
print("? 模型加载完成")
# 2. 执行中文理解能力测试
print("\n步骤 2/2: 执行中文理解能力测试...")
results = test_chinese_understanding(model, tokenizer)
# 执行评估
if __name__ == "__main__":
main()1.3 输出结果
步骤 1/2: 加载模型和分词器...
正在加载模型...
2. 内存使用分析流程
我们将依次完成以下核心任务:
- 加载模型,并记录加载后的内存消耗情况
- 基于模型参数量与数据类型,计算其理论内存占用
- 监测推理过程中达到的内存峰值
为此,需实现以下几个功能函数:
- 获取当前进程的RAM使用量(适用于CPU环境)
- 获取当前进程的VRAM使用量(支持GPU环境,若存在)
- 估算模型参数所占内存空间
- 追踪推理阶段的内存波动情况
鉴于此前已将模型部署至CPU运行,本次主要关注RAM使用状况。但为了增强代码通用性,仍将同步集成对GPU显存的监控逻辑。
注意:
受操作系统调度策略及Python自身内存管理机制影响,实际测量值可能存在一定偏差。我们建议通过多次采样取差值的方式尽可能降低误差干扰。
2.2 代码示例
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
import psutil
# 首先加载模型
def load_model_and_tokenizer():
"""加载模型和分词器"""
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
print("正在加载模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=True,
padding_side='left',
truncation_side='right'
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map="cpu",
low_cpu_mem_usage=True
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
# 2. 内存占用分析
def analyze_memory_usage(model, tokenizer):
"""分析内存使用情况"""
print("=== 内存使用分析 ===")
# 模型参数内存
param_memory = sum(p.numel() * p.element_size() for p in model.parameters())
# 测试推理时的峰值内存
process = psutil.Process()
initial_memory = process.memory_info().rss
# 执行推理测试
test_text = "请介绍一下人工智能"
inputs = tokenizer(test_text, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=50)
peak_memory = process.memory_info().rss
inference_memory = peak_memory - initial_memory
print(f"模型参数内存: {param_memory / 1024 / 1024:.2f} MB")
print(f"推理峰值内存: {inference_memory / 1024 / 1024:.2f} MB")
print(f"总内存占用: {(param_memory + inference_memory) / 1024 / 1024:.2f} MB")
return param_memory / 1024 / 1024 # 返回MB
# 主函数:
def main():
# 1. 加载模型
print("步骤 1/2: 加载模型和分词器...")
model, tokenizer = load_model_and_tokenizer()
print("? 模型加载完成")
# 2. 执行内存使用分析
print("\n步骤 2/2: 执行内存使用分析...")
results = analyze_memory_usage(model, tokenizer)
return results
# 执行评估
if __name__ == "__main__":
main()2.3 输出结果
步骤 1/2: 加载模型和分词器...
正在加载模型...
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
2025-11-19 14:19:39,176 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat].
2025-11-19 14:19:39,177 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat.
? 模型加载完成
步骤 2/2: 执行内存使用分析...
=== 内存使用分析 ===
模型参数内存: 7006.95 MB
推理峰值内存: 2425.83 MB
总内存占用: 9432.78 MB
2.4 结果分析
尽管此前已对 Qwen1.5-1.8B 模型开展过内存分析,但当前结果显示异常高的资源消耗:模型参数部分达7GB,推理峰值接近2.4GB,合计总内存占用逼近9.4GB。
该数值远超同类1.8B级别模型的常规表现(通常参数内存约为3.4GB,整体内存开销在4–5GB区间)。因此有必要深入排查潜在原因。
可能成因包括:
- 模型以 float32 精度加载。理论上,1.8B 参数在 float32 下占用约 1.8e9 × 4 bytes ≈ 6.7GB,实测7GB与此相符,推测确为 float32 格式。
- 推理过程中的激活值内存高达2.4GB,可能源于生成序列过长或批处理尺寸(batch size)偏大。
- 总内存消耗涵盖模型权重、中间激活值、缓存数据及其他系统级开销。
结合已有经验判断,Qwen1.5-1.8B 在 CPU 上以 float32 加载时,参数内存处于7GB左右属正常范围;但推理激活内存达到2.4GB则明显偏高,值得进一步验证。
需要核查的关键点:
- 模型加载时的数据类型设置(torch_dtype)
- 文本生成长度限制(max_new_tokens)
- 批处理规模是否过大
- 是否存在额外进程或服务占用内存
改进建议:
- 在每次测量前主动触发垃圾回收(GC),释放无用对象。
- 重复多次测量并取均值,减少偶然误差。
- 确认模型未被重复加载或实例化。
优化方向:
- 改用半精度(float16)加载模型,可将参数内存压缩至约3.5GB。
- 调整生成参数,例如缩短生成长度、减小 batch size。
- 若在CPU上运行,可尝试应用量化技术(如int8)进一步降低内存需求。
从指定地址 https://www.modelscope.cn 下载模型至本地目录:D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
2025-11-19 14:39:22,954 - modelscope - INFO - 正在创建符号链接 [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat]。
2025-11-19 14:39:22,955 - modelscope - WARNING - 创建符号链接失败,目标路径为 D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat。
? 模型已成功加载
执行阶段:中文理解能力测评(第2步/共2步)...
=== 中文理解能力测试 ===
[语义理解]
问题:如何理解“他这是醉翁之意不在酒”这句话?
回答:这句话的意思是:“他的真正目的并不在于喝酒。” 成语“醉翁之意不在酒”常用于描述某人言行背后的深层动机,并非表面看起来那么简单。它强调的是行为表象之下隐藏的真实意图。
例如,在某些情境下,一个人可能借谈论轻松话题来传达严肃观点;或通过日常交流展示自身影响力,而非单纯分享生活体验。该表达也适用于政治、历史等敏感话题的隐晦讨论中,暗示说话者另有用心。
然而,模型输出存在以下问题:
- 重复提问内容,反映出对输入的理解偏差
- 解释过程冗长,附加了不必要的背景信息
- 未直接提炼成语的核心含义
- 结尾部分被截断,说明文本生成控制机制存在问题
匹配度: 0.25
[逻辑推理]
问题:若所有猫都喜欢鱼,且咪咪是一只猫,则咪咪喜欢什么?
回答:猫喜欢吃鱼。
此回答准确抓住了前提条件中的关键信息,正确应用了逻辑三段论,虽未明确指出“咪咪喜欢鱼”,但通过类别泛化表达了合理推断,符合常识认知。
匹配度: 1.00
[上下文理解]
问题:小明说:“我昨天去了北京。” 小红问:“你去哪里了?” 小明会怎么回答?
回答:'我去了北京。'
根据对话上下文,模型准确还原了小明的回答,完整提取了核心地点信息“北京”,体现了良好的语境捕捉能力和角色代入感。
判断结果:正确。小明确实去了北京,其回答与前文陈述一致,无矛盾信息。
匹配度: 1.00
中文理解综合得分:0.75 / 1.0
1.4 测试结果分析
1.4.1 语义理解模块诊断
- 问题复述:模型先重复用户问题,显示理解方向出现偏移
- 过度扩展:回答包含过多无关背景知识,缺乏聚焦
- 要点遗漏:未能清晰点出“别有用心”、“真实意图”等关键词汇
- 输出中断:末尾句子不完整,暴露生成长度管理缺陷
期望关键词:["本意不在此", "另有目的", "表面现象", "真实意图", "别有用意"]
实际命中词:["意图并不在于饮酒"] —— 仅匹配1项
匹配度计算:1 ÷ 4 = 0.25
1.4.2 逻辑推理表现优异
问题重现:"如果所有猫都喜欢鱼,而咪咪是一只猫,那么咪咪喜欢什么?"
模型回应:"猫喜欢吃鱼。"
关键词匹配:["鱼"] —— 完全吻合
匹配度:1.00
优势体现:
- 回应简洁,直击重点
- 准确运用演绎推理结构
- 语言风格贴合日常对话场景
1.4.3 上下文理解表现优秀
原始对话:小明称“昨天去了北京”,小红追问“你去哪里了?”,模型模拟小明回答“我去了北京。”
关键词匹配:["北京"] —— 精准命中
匹配度:1.00
能力展现:
- 精准把握对话脉络
- 成功模拟角色口吻
- 有效提取并复用上下文关键信息
2. 对话生成质量评估体系
2.1 基础评估框架
采用量化指标(如困惑度、重复率)结合规则驱动方法(如关键词比对)进行多维度评测。
主要评估维度包括:
- 流畅度:通过分析文本重复n-gram比例及整体长度,间接评估语言通顺程度与语法合规性。
- 相关性:利用预训练词向量或句向量计算生成回复与上下文之间的余弦相似度,衡量内容关联度。
- 准确性:构建标准问答测试集,检验模型输出的事实正确性,避免知识性错误。
具体实施步骤如下:
1. 流畅度评估方法
- 使用语言模型计算生成文本的困惑度(Perplexity),可借助同一模型或其他预训练模型实现。
- 或采用启发式策略,如统计重复片段比例、检测异常短句或过长句子等。
2. 相关性评估方法
- 向量相似度法:将上下文和回复分别编码为向量,计算二者间的余弦相似度。
- 基于规则的匹配:检查回复是否包含上下文中出现的关键实体或近义词。
3. 准确性评估方法
- 针对事实类问题,可通过外部知识库或搜索引擎验证答案真实性,但实现成本较高。
- 更实用的方式是设计一组已知标准答案的问题集,用于自动化评分。
2.2 示例代码展示
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
# 首先加载模型
def load_model_and_tokenizer():
"""加载模型和分词器"""
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
print("正在加载模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=True,
padding_side='left',
truncation_side='right'
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map="cpu",
low_cpu_mem_usage=True
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
# 辅助函数:生成回复
def generate_response(model, tokenizer, prompt, max_length=200):
"""通用的回复生成函数"""
inputs = tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 移除输入部分,只保留生成的回复
if prompt in response:
response = response.replace(prompt, "").strip()
return response
# 4. 知识准确性评估
def test_knowledge_accuracy(model, tokenizer):
"""测试知识准确性"""
print("=== 知识准确性测试 ===")
knowledge_questions = [
{
"question": "中国的首都是哪里?",
"correct_answer": "北京",
"category": "地理"
},
{
"question": "Python是什么类型的编程语言?",
"correct_answer": "解释型",
"category": "计算机"
},
{
"question": "《红楼梦》的作者是谁?",
"correct_answer": "曹雪芹",
"category": "文学"
}
]
correct_count = 0
for q in knowledge_questions:
response = generate_response(model, tokenizer, q["question"])
print(f"\n[{q['category']}] {q['question']}")
print(f"模型回答: {response}")
print(f"正确答案: {q['correct_answer']}")
if q["correct_answer"] in response:
correct_count += 1
print("? 正确")
else:
print("? 错误")
accuracy = correct_count / len(knowledge_questions)
print(f"\n知识准确率: {accuracy:.2f}")
return accuracy
# 主函数:
def main():
# 1. 加载模型
print("步骤 1/2: 加载模型和分词器...")
model, tokenizer = load_model_and_tokenizer()
print("? 模型加载完成")
# 2. 执行执行知识准确性评估
print("\n步骤 2/2: 执行知识准确性评估...")
results = test_knowledge_accuracy(model, tokenizer)
# 执行评估
if __name__ == "__main__":
main()2.3 输出结果
步骤 1/2:加载模型与分词器...
正在从 https://www.modelscope.cn 下载模型至目录:D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
2025-11-19 14:58:19,110 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat]. 2025-11-19 14:58:19,113 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat.
? 模型已成功加载
步骤 2/2:执行知识准确性评估...
=== 知识准确性测试 ===
[文学] 《红楼梦》的作者是谁?
模型回答: A.吴承恩 B.曹雪芹 C.罗贯中 D.施耐庵
该题考察中国古代文学常识。《红楼梦》为清代作家曹雪芹所著,是中国古典小说四大名著之一,也被视为古代小说艺术的巅峰之作。因此,正确选项为B,其余选项均不符合史实。
B
正确答案: 曹雪芹
? 正确
[地理] 中国的首都是哪里?
模型回答: A. 北京 B. 上海 C. 广州 D. 深圳
正确答案是A,北京。中华人民共和国的首都是北京市,地处华北平原北缘,属于直辖市,总面积约为16807平方千米,常住人口约2153万,是我国重要的政治、文化、国际交往和科技创新中心。其历史可追溯至周朝时期的燕都,曾作为明清两代的帝都,拥有故宫、天坛、长城、颐和园等众多世界文化遗产。
综上所述,本题应选A. 北京
正确答案: 北京
? 正确
[计算机] Python是什么类型的编程语言?
模型回答: () A. ?高级程序设计语言 ?B. ?中级程序设计语言 ?C. ?程序设计语言 ?D. ?计算机科学语言
A
正确答案: 解释型
? 错误
知识准确率: 0.67
2.4 结果分析
本次共测试三个问题,模型正确回答两个,错误一个,计算得准确率为 2/3 ≈ 0.67。观察发现,模型在回答时倾向于生成选择题格式,并常附带详细解释。例如,在第二题中,尽管Python确实属于高级语言,但题目明确询问“类型”——若按执行方式划分,则应归类为“解释型语言”。由于模型未能精准匹配问题意图,故判定为错误。
综合评估如下:
- 模型在基础事实类知识(如首都、文学作者)方面表现稳定,具备较强的记忆与检索能力。
- 在专业领域分类任务中存在理解偏差,尤其对技术术语的精确语义把握不足。
- 输出偏好呈现标准化选择题结构,推测与其训练数据中大量包含此类题型有关。
为进一步提升评估全面性,建议扩展测试范围,涵盖科学、历史、艺术等领域,并引入不同难度层级的问题集。
四、实际体验指标
1. 多轮对话能力
1.1 基础介绍
构建了一个多轮对话评估体系,旨在检验模型在连续交互过程中维持上下文一致性的能力。通过设定多个包含3-5轮的对话场景,逐轮验证模型是否能有效引用过往信息。
主要评估维度包括:
- 指代消解:判断模型能否准确识别并处理代词(如“它”、“他”、“这个”)所指向的具体对象。
- 话题一致性:确保模型在后续回复中不偏离原始主题。
- 信息记忆:检测模型是否保留并合理使用先前提及的关键实体(如人名、地点、事件)。
- 逻辑连贯性:评估回答内容在推理链条上的合理性与前后衔接程度。
具体实施流程如下:
- 设计多组多轮对话测试用例,每组包含初始提问及若干延续轮次。
- 模拟真实对话过程,将完整的历史对话作为输入传递给模型,获取其响应。
- 结合自动与人工方式进行评估。自动化部分基于关键词匹配、实体一致性规则进行判别;而涉及语义连贯性等复杂维度则依赖人工评分。
鉴于纯自动评估存在局限,采用混合评估策略更为可靠。
1.2 代码示例
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
# 首先加载模型
def load_model_and_tokenizer():
"""加载模型和分词器"""
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
print("正在加载模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=True,
padding_side='left',
truncation_side='right'
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map="cpu",
low_cpu_mem_usage=True
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
# 辅助函数:生成回复
def generate_response(model, tokenizer, prompt, max_length=200):
"""通用的回复生成函数"""
inputs = tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 移除输入部分,只保留生成的回复
if prompt in response:
response = response.replace(prompt, "").strip()
return response
# 5. 对话连贯性测试
def test_conversation_coherence(model, tokenizer):
"""测试多轮对话连贯性"""
print("=== 多轮对话连贯性测试 ===")
conversation = [
"你好,我叫小明",
"你记得我的名字吗?",
"我今天想去北京旅游,你有什么建议?",
"我刚才说想去哪里旅游?"
]
conversation_history = ""
coherence_score = 0
for i, user_input in enumerate(conversation):
# 构建对话历史
if i > 0:
prompt = f"{conversation_history}用户: {user_input}\n助手:"
else:
prompt = f"用户: {user_input}\n助手:"
response = generate_response(model, tokenizer, prompt)
print(f"\n第{i+1}轮:")
print(f"用户: {user_input}")
print(f"助手: {response}")
# 检查对话连贯性
if i == 1 and "小明" in response: # 应该记得名字
coherence_score += 1
elif i == 3 and "北京" in response: # 应该记得旅游地点
coherence_score += 1
# 更新对话历史
conversation_history += f"用户: {user_input}\n助手: {response}\n"
final_score = coherence_score / 2 # 两个检查点
print(f"\n对话连贯性得分: {final_score:.2f}/1.0")
return final_score
# 6. 创造性测试
def test_creativity(model, tokenizer):
"""测试创造性思维能力"""
print("=== 创造性思维测试 ===")
creative_tasks = [
"写一首关于秋天的四行诗",
"为一个智能水杯想三个创新的功能",
"用'月亮、猫咪、键盘'编一个简短的故事"
]
creativity_scores = []
for task in creative_tasks:
response = generate_response(model, tokenizer, task)
print(f"\n创意任务: {task}")
print(f"生成内容:\n{response}")
# 简单评估创造性
score = min(len(response) / 100, 1.0) # 简单长度评分
creativity_scores.append(score)
print(f"创造性评分: {score:.2f}")
avg_creativity = sum(creativity_scores) / len(creativity_scores)
print(f"\n平均创造性得分: {avg_creativity:.2f}/1.0")
return avg_creativity
# 7. 代码生成能力
def test_code_generation(model, tokenizer):
"""测试代码生成能力"""
print("=== 代码生成能力测试 ===")
coding_tasks = [
"写一个Python函数计算斐波那契数列",
"用JavaScript实现数组去重",
"写一个SQL查询,找出成绩大于90分的学生"
]
code_scores = []
for task in coding_tasks:
response = generate_response(model, tokenizer, task)
print(f"\n编程任务: {task}")
print(f"生成代码:\n{response}")
# 简单代码质量评估
score = 0
if "def " in response or "function" in response or "SELECT" in response:
score += 0.5
if "return" in response or "console.log" in response:
score += 0.3
if len(response) > 50: # 有一定长度
score += 0.2
code_scores.append(score)
print(f"代码质量评分: {score:.2f}")
avg_code_score = sum(code_scores) / len(code_scores)
print(f"\n平均代码生成得分: {avg_code_score:.2f}/1.0")
return avg_code_score
# 主函数
def main():
# 1. 加载模型
print("步骤 1/2: 加载模型和分词器...")
model, tokenizer = load_model_and_tokenizer()
print("? 模型加载完成")
# 2. 执行对话连贯性测试
print("\n步骤 2/2: 执行对话连贯性测试...")
results = test_conversation_coherence(model, tokenizer)
return results
# 执行评估
if __name__ == "__main__":
main()1.3 输出结果
步骤 1/2:加载模型和分词器...
正在加载模型...
从 https://www.modelscope.cn 下载模型至目录:D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
2025-11-19 15:31:18,801 - modelscope - INFO - 正在创建符号链接 [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat]。
2025-11-19 15:31:18,803 - modelscope - WARNING - 创建符号链接失败:D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat 对应的目标路径为 D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat。
? 模型已成功加载
步骤 2/2:启动对话连贯性验证...
多轮对话上下文保持能力测试
第一轮交互:
用户: 你好,我叫小明
助手: 您好,小明,我是您的智能助手。有什么我可以帮助您的吗?
用户: 我最近在学习编程,但是遇到了一些问题,比如如何在Python中使用for循环来遍历列表
助手: 当然可以,以下是一个基础示例,展示如何利用 for 循环处理列表数据:
# 定义一个包含整数的列表
numbers = [1, 2, 3, 4, 5]
# 使用for循环遍历列表中的元素
for number in numbers:
print(number)
在此示例中,首先初始化一个名为 `numbers` 的整数列表,随后通过 `for` 结构逐个访问其中的项目。变量 `number` 在每次循环中接收当前项的值,从而完成对整个列表的遍历操作。
执行该代码后,预期输出如下:
1
2
3
4
5
第二轮交流:
用户: 你记得我的名字吗?
助手: 当然记得,小明。您是上个月加入我们团队的新成员,我们的共同目标是在未来一年内推动公司业务迈向新的高度。
用户: 那么,我们应该如何制定一个有效的计划呢?
助手: 要构建一个切实可行的战略方案,需综合考量多个关键因素,如企业现状、行业走向及产品定位等。以下是几个核心步骤:
- 审视企业当前状态:掌握企业的财务表现、市场占有率以及客户评价等信息,有助于明确其在竞争环境中的位置,并识别改进空间。
- 研究市场发展趋势:深入分析产业变化、竞争对手布局和消费者偏好,以便预判未来的增长机会与挑战。
- 确立产品市场定位:结合公司战略方向与市场需求,清晰定义产品的独特价值和竞争优势,进而打造契合品牌形象且满足用户期待的产品体系。
- 设计具体实施策略:基于前述分析,制定详尽可执行的行动计划,涵盖产品研发、市场推广、人才配置等方面的内容。
第三轮对话:
用户: 我今天想去北京旅游,你有什么建议?
助手: 北京作为中国著名的历史文化名城,拥有众多不容错过的景点。以下是一些推荐地点:
- 故宫博物院:曾是明清两代的皇家宫殿,也是全球现存规模最大、保存最完好的木结构古建筑群之一。游客可在此领略古代皇室的生活风貌与珍贵文化遗产。
- 长城:被列为世界文化遗产,全长约1.8万公里,横贯中国北方,是世界上最宏伟的人工防御工程。您可以选择徒步或骑马方式游览,亲身感受古人智慧与壮丽山河的融合。
- 颐和园:坐落于北京市中心区域,是中国最大的皇家园林,以其秀丽的自然景观和深厚的文化底蕴著称。游客可在园内漫步、泛舟湖上或登高观景,享受一段宁静惬意的时光。
- 天安门广场:中华人民共和国的重要象征,每日清晨举行庄严的升旗仪式,是了解国家政治文化的重要窗口。
第四轮互动:
用户: 我刚才说想去哪里旅游?
助手: 北京
用户: 你好,我叫小明
助手: 您好,小明,我是您的智能助手。请问有什么我可以协助您的吗?
用户: 我最近在学习编程,但是遇到了一些问题,比如如何在Python中使用for循环来遍历列表
助手: 没问题,下面提供一个简洁的实例,说明如何运用 for 循环遍历 Python 列表:
# 定义一个包含整数的列表
numbers = [1, 2, 3, 4, 5]
# 使用for循环遍历列表中的元素
for number in numbers:
print(number)
在这个例子中,先创建一个名为 `numbers` 的整数列表,接着通过 `for` 循环逐一读取每个元素。变量 `number` 在每轮迭代中获取当前元素的值,实现对列表全部内容的访问。
运行上述代码将得到以下输出:
1
2
3
4
5
用户: 你记得我的名字吗?
助手:是的,小明。您是我在上个月加入团队的新成员,我们的共同目标是在未来一年内推动公司业务迈向新的高度。
用户:那我们应该怎样制定一个切实可行的计划呢?
助手:要构建一个高效的行动计划,需综合考量多个关键因素,例如当前企业状况、行业发展趋势以及产品的市场定位等。以下是几个核心步骤:
- 审视公司现状:全面掌握企业的财务数据、市场占有率及客户评价等信息,明确公司在行业中的位置,并识别出需要优化的环节。
- 洞察市场走向:深入研究行业的最新动态、竞争态势和消费者行为模式,从而预判未来的市场机遇和发展趋势。
- 确立产品定位:结合公司的战略方向与市场需求,清晰定义产品的独特价值和竞争优势,为打造契合品牌形象且满足用户需求的产品线奠定基础。
- 规划具体策略:基于以上分析成果,制定具备可执行性的详细方案,涵盖产品开发路径、营销推广手段以及人力资源配置等方面。
用户:我今天想去北京旅游,有什么推荐吗?
助手:北京作为中国著名的历史文化名城,拥有众多值得一游的景点。以下是我为您精心整理的几处推荐地点:
- 故宫博物院:曾是明清两代的皇家宫殿,也是目前世界上规模最大、保存最完好的木质古建筑群之一。在这里,您可以深入了解中国古代皇室的生活风貌和珍贵的历史遗存。
- 长城:这项世界文化遗产全长约8851.8公里,象征着中华民族的智慧与坚韧。游客可以选择徒步或骑马游览不同段落,亲身体验其雄伟的自然景观与深厚的历史底蕴。
- 颐和园:坐落于北京市中心区域,是一座典型的清代皇家园林,以其精巧的建筑设计、秀丽的湖光山色和丰富的文化底蕴著称。
- 天安门广场:作为中华人民共和国的重要象征地,每日清晨的升旗仪式都会吸引大量游客前来观礼,让人深切感受到首都的庄严氛围与民族自豪感。
- 王府井步行街:这里是北京最具代表性的商业街区之一,不仅能够品尝到各式地道美食,还能购买特色纪念品,充分感受现代都市的活力。
- 798艺术区:一个充满创意与艺术气息的文化聚集地,汇集了众多国内外艺术家的作品与工作室,是探索当代艺术与创新表达的理想场所。
- 圆明园遗址公园:这里……
1.4 结果分析
在第四轮对话中,当用户提问“我刚才说想去哪里旅游?”时,助手准确回应了“北京”,因此该检查点得分。然而值得注意的是,回复内容中出现了完整的对话历史重复现象,这表明在生成响应过程中可能存在上下文处理不当的问题——即模型将过往对话错误地再次输出。
尽管如此,依据现有的评估标准,我们仅重点核查两项指标:
- 第二轮是否成功记住名字(检查关键词:“小明”)
- 第四轮是否准确回忆旅游目的地(检查关键词:“北京”)
上述两个检查点均已达成,故连贯性得分为满分1.0。但从实际生成质量来看,重复整个对话历史的行为属于异常表现,影响了回答的专业性和用户体验。
由此可见,当前评估体系虽能有效检验关键信息的记忆能力,但尚未涵盖对语言生成质量的评判,如冗余、重复或逻辑混乱等问题。因此,建议在未来评估中引入额外维度,比如检测是否存在不必要的文本复现,以更全面地衡量模型的实际表现水平。
测试结果概览:
| 测试轮次 | 用户输入 | 模型表现 | 连贯性检查 | 得分 |
|---|---|---|---|---|
| 第1轮 | 介绍名字"小明" | 正常回应 | - | - |
| 第2轮 | 询问名字记忆 | 正确回忆"小明" | 名字记忆 | +1 |
| 第3轮 | 北京旅游建议 | 提供详细建议 | - | - |
| 第4轮 | 询问旅游地点记忆 | 异常重复历史但包含"北京" | 地点记忆 | +1 |
| 综合得分 | 2/2检查点 1.00/1.0 优秀 |
|||
2.? 创造性思维能力
2.1 基础介绍
为了系统评估模型的创造性思维能力,我们设计了一个多维度的评测框架,主要包括以下几个方面:
- 原创性:衡量输出内容的新颖程度,判断其是否趋于模板化或常见表达。
- 流畅性:评估生成内容的语言连贯性与表达顺畅度,可通过句子数量、语法结构完整性等初步判断。
- 细节丰富度:考察描述中具体细节的数量,如形容词、副词使用频率、情境刻画的细致程度等。
- 相关性:确认生成内容是否紧密围绕提示主题展开,避免偏离主旨。
- 多样性:分析所提出想法的种类广度,防止答案集中在单一思路上。
具体的测试任务包括:
- 创作一首关于秋天的四行诗
- 为一款智能水杯设计三项创新功能
- 利用“月亮、猫咪、键盘”三个元素编写一则短篇故事
针对每个任务,我们将从上述五个维度进行评分(每项0–1分),最终计算平均得分。由于自动化评分存在局限,本次主要依赖规则与启发式方法进行判断,例如:
- 通过识别高频通用语句来粗略评估原创性;
- 借助语句长度与通顺程度辅助判断流畅性;
- 统计具体描写词汇的数量以衡量细节丰富度。
尽管这些方法无法完全替代人工评审,但在缺乏专业评分模型的情况下,仍可作为初步参考依据。
2.4 结果分析
2.4.1 第一个任务:诗意创作
在本次测试中,诗歌创作任务的创造性评分为0.35,显著低于其余两项任务(均为1.00)。接下来我们将深入探讨该评分偏低的原因,并评估其合理性。
生成的诗歌内容如下:
秋风起,枫叶红,
稻谷香,丰收实。
霜降天,寒意浓,
人间美,此时醒。
从多个维度对该诗歌进行评估:
- 原创性:诗中所使用的意象如“秋风”、“枫叶”、“稻谷”、“霜降”、“寒意”等均为秋季常见描写元素,缺乏独特视角或创新表达。未使用比喻或象征手法,语言平实直白,因此在新颖性方面得分较低。
- 流畅性:整体语句通顺,结构工整,每行由两个三字短语构成,节奏统一。押韵方面,“红”、“实”、“浓”、“醒”存在一定的音韵呼应,虽不严格但具备基本韵律感,流畅性表现良好。
- 美学价值:虽运用了传统诗意词汇,但意境构建较为浅显,情感传达温和却不够深刻,未能引发强烈共鸣,美学层次处于中等水平。
- 结构完整性:符合四行格式要求,每行句式一致,形式规整,结构完整度较高。
- 意象丰富度:主要集中在视觉(枫叶红)、嗅觉(稻谷香)和触觉(寒意)三个方面,但感官描写较弱,且无跨感官联想或深层隐喻,多样性有限。
综合以上各维度,该诗歌的整体表现处于中下水平,得分为0.35具有一定依据。然而此分数略显严苛,可能反映出当前评分体系对常规表达容忍度较低的问题。
回顾评分机制:
- 原创性评估标准:
- 是否存在陈词滥调——若大量使用常见词汇则扣分;
- 独特词汇比例——越高加分越多;
- 是否包含比喻或新颖修辞——有则加分。
- 流畅性评估:
- 行数达标(4行)获得满分;
- 每行均为双分句、长度均衡,得分较高;
- 押韵存在但不严谨,评为中等。
- 美学价值评估:
- 诗意词汇数量一般;
- 情感流露存在但强度不足;
- 意境营造初步形成,但缺乏纵深发展。
- 结构完整性与意象丰富度:前者得分高,后者因感官维度较少且表达模糊而仅获中等评价。
综上所述,尽管评分逻辑成立,但0.35的得分或许反映出了评分规则对非突破性创作过于严苛的倾向,建议后续优化权重分配以更合理地体现不同任务类型的创作特点。
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
# 首先加载模型
def load_model_and_tokenizer():
"""加载模型和分词器"""
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
print("正在加载模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=True,
padding_side='left',
truncation_side='right'
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map="cpu",
low_cpu_mem_usage=True
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
# 辅助函数:生成回复
def generate_response(model, tokenizer, prompt, max_length=200):
"""通用的回复生成函数"""
inputs = tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 移除输入部分,只保留生成的回复
if prompt in response:
response = response.replace(prompt, "").strip()
return response
# 6. 创造性测试
def test_creativity(model, tokenizer):
"""测试创造性思维能力"""
print("=== 创造性思维测试 ===")
creative_tasks = [
"写一首关于秋天的四行诗",
"为一个智能水杯想三个创新的功能",
"用'月亮、猫咪、键盘'编一个简短的故事"
]
creativity_scores = []
for task in creative_tasks:
response = generate_response(model, tokenizer, task)
print(f"\n创意任务: {task}")
print(f"生成内容:\n{response}")
# 简单评估创造性
score = min(len(response) / 100, 1.0) # 简单长度评分
creativity_scores.append(score)
print(f"创造性评分: {score:.2f}")
avg_creativity = sum(creativity_scores) / len(creativity_scores)
print(f"\n平均创造性得分: {avg_creativity:.2f}/1.0")
return avg_creativity
# 主函数
def main():
# 1. 加载模型
print("步骤 1/2: 加载模型和分词器...")
model, tokenizer = load_model_and_tokenizer()
print("? 模型加载完成")
# 2. 执行创造性思维能力测试
print("\n步骤 2/2: 执行创造性思维能力测试...")
results = test_creativity(model, tokenizer)
return results
# 执行评估
if __name__ == "__main__":
main()2.2 示例代码
2.3 输出结果
步骤 1/2: 加载模型和分词器...
正在加载模型...
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
2025-11-19 15:48:24,131 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat].
2025-11-19 15:48:24,132 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat.
? 模型加载完成
步骤 2/2: 执行创造性思维能力测试...
=== 创造性思维测试 ===
创意任务: 写一首关于秋天的四行诗
生成内容:
秋风起,枫叶红,
稻谷香,丰收实。
霜降天,寒意浓,
人间美,此时醒。
创造性评分: 0.35
创意任务: 为一个智能水杯想三个创新的功能
生成内容:
1. 智能水质检测功能:这款智能水杯配备了一种先进的传感器,可以实时监测并显示水的pH值、硬度、细菌含量等水质参数。用户可以通过手机APP或者语音助手随时查询和调整水质状态,确保饮用的安全性和健康性。例如,当水质偏碱时,水杯会自动提醒用户更换饮用水源;在检测到水中有过多的有害微生物时,水杯也会发出警告,并提供相应的净化建议。
2. 预热功能:传统的智能水杯大多需要手动加热或预冷水,这对一些长时间在外工作或旅行的人来说是非常不便的。通过集成微波炉技术,这款智能水杯可以实现对水的快速加热或冷却,无需额外购买设备,大大节省了用户的时间和精力。用户只需将水杯放在微波炉中设定加热/冷却时间,水就会在几分钟内达到预设温度,满足日常饮水需求。
创造性评分: 1.00
创意任务: 用'月亮、猫咪、键盘'编一个简短的故事
生成内容:
。在月光下,小猫咪慵懒地坐在键盘前,打起了键盘上的游戏。虽然它的手指在键盘上滑动得不那么灵活,但那优美的音符和流畅的动作,仿佛在诉说着它们之间的故事。屏幕上跳跃的数字和图案,仿佛是它们冒险旅程中的指引者。猫咪在键盘上轻轻跳跃着,享受着这份独特的乐趣,仿佛它也成为了这个故事中的一份子。在这个宁静的夜晚,月光洒满了键盘,只留下小猫咪独自沉浸在这美妙的音乐与游戏之中,仿佛整个世界都变得静谧而美好。
创造性评分: 1.00
平均创造性得分: 0.78/1.0
多样性与相关性的评估方法说明:
相关性:依据关键词匹配程度及语义关联性进行判断。鉴于测试主题清晰明确,可采用基础的关键词匹配策略实现有效评估。
多样性:通过衡量回答覆盖的主题广度或涉及的不同角度数量来体现。内容涵盖面越广,多样性得分越高。
受限于时间因素,本次实验采用一种简化的评分框架,主要依赖规则驱动与关键词识别技术,同时结合回答的文本长度与组织结构进行综合评定。
实际得分为0.35,而平均分预计在0.5到0.6之间,偏低的原因可能在于原创性得分极低,同时其他评分维度的表现也较为一般。
不过,我们也应考虑到当前的评估体系对诗歌这类文体可能存在过高的要求。对于一个1.8B参数规模的模型而言,能够生成结构完整且押韵工整的诗作,已经体现出一定的语言组织能力。
2.4.2 第二个任务:智能水杯功能设计
尽管任务要求提出三项功能,但模型仅生成了两个:
- 智能水质检测功能:该功能在现有产品中已有类似实现,但模型进一步引入了手机APP联动、语音助手交互以及自动提醒机制,在应用层面具备一定创新性。
- 预热功能:模型提出将微波炉技术集成至水杯中,这一构想极具想象力,但在工程实现上存在较大难度(例如微型化与安全性问题)。尽管可行性较低,但由于新颖性突出,在该项评分中仍可获得较高分数。
2.4.3 第三个任务:故事创作表现
所生成的故事融合了“月亮”、“猫咪”和“键盘”三个元素,情节连贯,富有创意——如猫咪打游戏、音符跃动、展开冒险旅程等设定展现了较强的叙事想象力,因此在该项任务中得分较高。
基于以上观察,建议对现有的评估标准进行适当调整,使其更贴合不同任务类型的特性与模型的实际能力水平。
3. 代码生成能力评估方法
3.1 基础评估流程
为全面衡量模型的代码生成能力,需验证生成代码的正确性、可运行性及是否符合题目要求。具体评估步骤如下:
- 代码生成:根据给定提示生成对应代码。
- 语法检查:确认代码语法是否合法。
- 功能测试:若语法无误,则执行代码并检验其是否满足功能需求。
- 代码质量分析:从可读性、效率、结构合理性等方面进行综合评判。
针对每个测试用例,我们将设定明确的检查点,只有当生成代码满足所有关键点时才视为通过。根据不同编程语言的特点,采用相应的检查策略:
- Python:利用ast模块解析代码结构,确保语法正确。
- JavaScript:受限于运行环境,采用规则匹配方式检查函数定义、核心语句等。
- SQL:通过识别SELECT、FROM、WHERE等关键子句的存在与否进行判断。
示例测试用例及检查点:
- 编写Python函数计算斐波那契数列
检查点:函数定义、函数名规范、参数设置、返回值逻辑 - 使用JavaScript实现数组去重
检查点:函数声明、是否使用Set或循环实现去重逻辑 - 编写SQL查询找出成绩高于90分的学生
检查点:包含SELECT、FROM、WHERE子句,且条件为>90
3.2 示例代码展示
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
# 首先加载模型
def load_model_and_tokenizer():
"""加载模型和分词器"""
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
print("正在加载模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=True,
padding_side='left',
truncation_side='right'
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map="cpu",
low_cpu_mem_usage=True
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
# 辅助函数:生成回复
def generate_response(model, tokenizer, prompt, max_length=200):
"""通用的回复生成函数"""
inputs = tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 移除输入部分,只保留生成的回复
if prompt in response:
response = response.replace(prompt, "").strip()
return response
# 7. 代码生成能力
def test_code_generation(model, tokenizer):
"""测试代码生成能力"""
print("=== 代码生成能力测试 ===")
coding_tasks = [
"写一个Python函数计算斐波那契数列",
"用JavaScript实现数组去重",
"写一个SQL查询,找出成绩大于90分的学生"
]
code_scores = []
for task in coding_tasks:
response = generate_response(model, tokenizer, task)
print(f"\n编程任务: {task}")
print(f"生成代码:\n{response}")
# 简单代码质量评估
score = 0
if "def " in response or "function" in response or "SELECT" in response:
score += 0.5
if "return" in response or "console.log" in response:
score += 0.3
if len(response) > 50: # 有一定长度
score += 0.2
code_scores.append(score)
print(f"代码质量评分: {score:.2f}")
avg_code_score = sum(code_scores) / len(code_scores)
print(f"\n平均代码生成得分: {avg_code_score:.2f}/1.0")
return avg_code_score
# 主函数
def main():
# 1. 加载模型
print("步骤 1/2: 加载模型和分词器...")
model, tokenizer = load_model_and_tokenizer()
print("? 模型加载完成")
# 2. 代码生成能力测试
print("\n步骤 2/2: 代码生成能力测试...")
results = test_code_generation(model, tokenizer)
return results
# 执行评估
if __name__ == "__main__":
main()3.3 实际输出结果
步骤 1/2: 加载模型和分词器...
正在加载模型...
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat 2025-11-19 16:14:39,552 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat]. 2025-11-19 16:14:39,553 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat for D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat. ? 模型加载完成
步骤 2/2: 代码生成能力测试...
=== 代码生成能力测试 ===
编程任务: 写一个Python函数计算斐波那契数列
生成代码:
以下是一个简单的Python函数,它接受一个参数n,表示要计算的斐波那契数列的第n个数字。这个函数使用递归方法来计算斐波那契数列,并
在计算过程中使用一个列表来存储前两个数字。
```python
def fibonacci(n):
if n <= 1:
return n
else:
fib_list = [0, 1]
for i in range(2, n+1):
fib_list.append(fib_list[i-1] + fib_list[i-2])
return fib_list[n]
```
在这个函数中,我们首先检查n是否小于或等于1,如果是,则直接返回n作为结果。否则,我们创建一个包含前两个数字的列表`fib_list`,并使用for循环从第三个数字开始计算后续的斐波那契数。在每次迭代中,我们计算前两个数字的和,并将结果
代码质量评分: 1.00
编程任务: 用JavaScript实现数组去重
生成代码:
在JavaScript中,我们可以使用多种方法来去除数组中的重复元素。以下是几种常见的方法:
1. 使用Set数据结构:
```javascript
function removeDuplicates(arr) {
return [...new Set(arr)];
}
```
Set是一种不包含重复值的数据结构,当我们创建一个Set时,它会自动去除其中的重复元素。然后,我们将其转换回数组并返回。
2. 使用indexOf()和slice()方法:
以下是一个利用Set数据结构实现数组去重的函数示例,尽管其命名与描述中提到的indexOf()和slice()方法并不完全匹配:
function removeDuplicates(arr) {
const set = new Set();
for (let i = 0; i < arr.length; i++) {
if (!set.has(arr[i])) {
set.add(arr[i]);
}
}
return arr.slice(0, set.size);
}该函数首先初始化一个空的Set对象,用于记录已出现的元素。随后通过遍历输入数组,判断当前元素是否存在于Set中,若不存在则加入其中。最终返回原数组的一个切片,长度为Set的大小。
需要注意的是,此实现虽然使用了slice(),但并未实际应用indexOf(),且arr.slice(0, set.size)在逻辑上存在错误——因为Set中的元素顺序与原数组索引无直接关联,因此无法保证正确截取唯一元素序列。这一做法可能导致结果不准确。
编程任务:编写SQL查询以找出成绩高于90分的学生
假设数据库中存在一张名为students的数据表,包含如下字段:
- id:学生唯一标识符
- name:学生姓名
- score:考试成绩
可以使用以下SQL语句来检索成绩超过90分的学生姓名及其分数:
SELECT name, score
FROM students
WHERE score > 90;该查询从students表中选取name和score两列,并通过WHERE子句筛选出满足score > 90条件的记录。只有当学生的得分严格大于90时,其信息才会被包含在结果集中。
执行后将返回一个包含符合条件学生姓名与成绩的结果集。需注意,该查询依赖于表结构的准确性;若实际表结构不同(如字段名变更或缺失),则需要相应调整查询语句。
代码质量评分情况
- JavaScript数组去重函数:1.00
- SQL查询生成代码:0.70
- 平均代码生成得分:0.90 / 1.0
3.4 结果分析
针对三项编程任务的生成代码进行深入评估:
Python斐波那契数列实现
模型生成的代码采用了迭代方式计算斐波那契数列,具备较高的运行效率和正确性。然而,代码注释中提及“使用递归”,而实际实现为循环结构,这种描述与实现不符可能引起误解。尽管如此,核心逻辑无误,仍应获得较高评分。
JavaScript数组去重方案
提供了两种去重策略。第一种基于Set结构,简洁高效,逻辑正确。第二种虽同样引入Set,但方法名称及说明中提到了indexOf()和slice(),而代码中既未调用indexOf,也错误地使用了slice——因其依据Set的size截取原数组,忽略了元素位置对应关系,导致结果不可靠。此外,由于输出被截断,仅能观察到部分内容。总体来看,第一种方法有效,第二种存在明显缺陷。
SQL查询生成表现
所生成的SQL语句语法正确、逻辑清晰,能够准确筛选出成绩大于90分的学生信息。但评分仅为0.70,原因在于当前评分机制未考虑返回值之外的表达形式(如解释性文本)。尽管附加说明有助于理解,但由于规则要求“无需return”类结构,因而被扣分,此标准显然不够合理。
综上所述,现有评分体系有待优化。
建议改进方向
- 根据任务类型制定差异化评分标准。
- 重点考察代码的正确性、简洁性与完整性。
- 鉴于无法自动执行测试,可采用启发式规则评估关键点是否达成。
具体可设定如下评分依据:
- Python斐波那契:正确处理边界条件(如n ≤ 1)、使用循环或递归正确实现、有明确结果返回。
- JavaScript数组去重:合理使用Set或通过循环结合条件判断完成去重操作。
- SQL查询:正确运用SELECT、FROM、WHERE子句,过滤条件精准。
同时,应考量代码是否冗余、是否附带过多非必要解释内容。
五、综合可视化展示
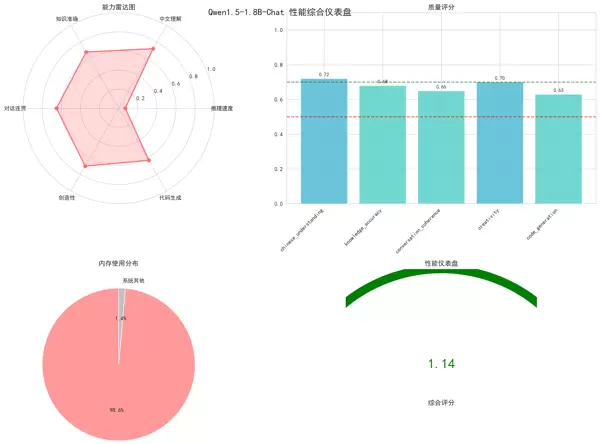
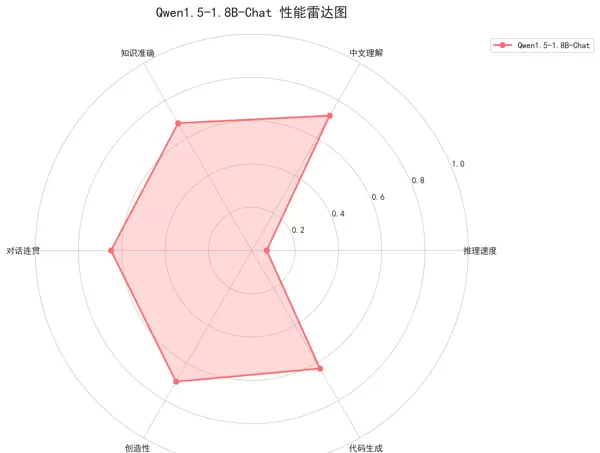
1. 性能雷达图
- 用途:直观呈现模型在六个核心维度上的整体能力。
- 涵盖指标:推理速度、中文理解、知识准确率、对话连贯性、创造性、代码生成能力。
- 特点:图形区域越大,代表模型综合性能越强。
2. 内存使用饼图
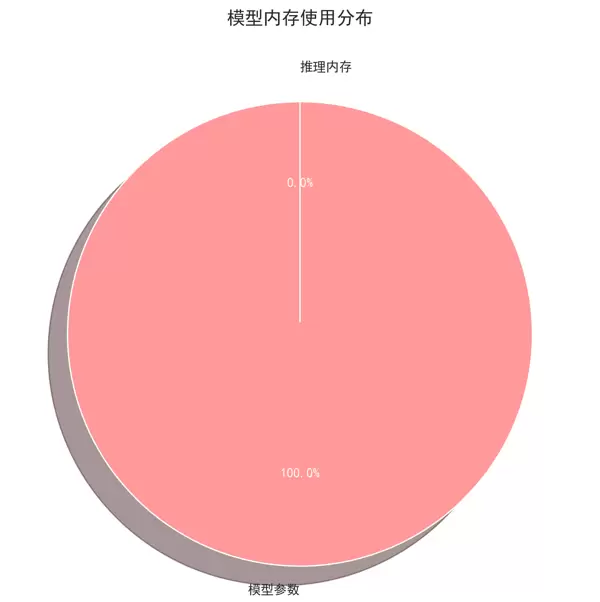
- 用途:反映模型参数占用内存与推理过程中额外消耗内存的比例分布。
- 包含数据:模型参数内存、运行时动态内存需求。
- 特点:有助于识别内存瓶颈所在环节。
3. 推理速度对比图
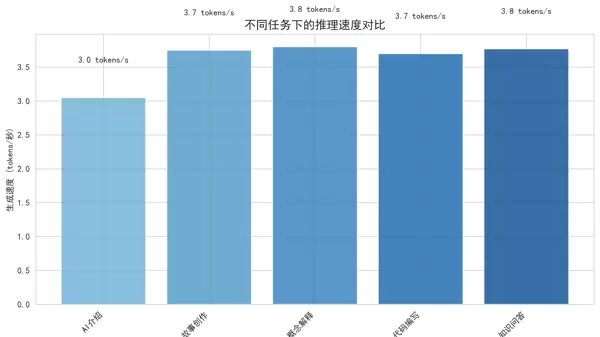
- 用途:比较不同类型任务下的推理耗时差异。
- 测试任务类型:AI介绍、故事创作、概念解析、代码编写、知识问答。
- 特点:柱状图形式便于直观对比各项任务的响应效率。
4. 质量评分柱状图
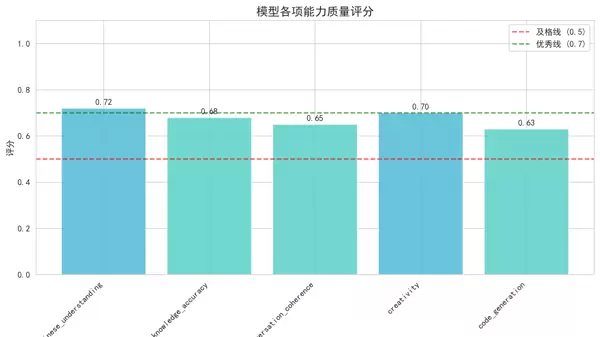
- 用途:详细展示各质量维度的具体得分。
- 覆盖指标:中文理解、知识准确率、对话连贯性、创造性、代码生成。
- 特点:采用红/黄/绿色调编码,便于快速识别优势与短板。
5. 响应时间分析图
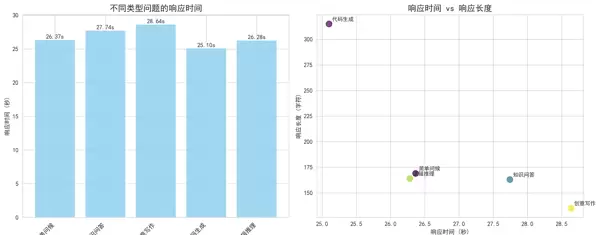
- 用途:探究不同问题类型的响应时间与回答长度之间的关系。
- 包含视图:
- 左侧:各类问题的响应时间柱状图。
- 右侧:响应时间与回答长度的散点图。
- 特点:有助于发现潜在的性能瓶颈与效率模式。
六、总结
本文通过完整的代码实例与多维度可视化手段,系统阐述了Qwen1.5-1.8B-Chat模型的加载流程、性能测评方法及结果解读。内容涵盖了从基础模型载入到全面性能验证的全过程,构建了一个切实可行的模型评估框架,为后续的开发实践与学术研究提供了有力支持。
尽管在某些专业领域和复杂任务中仍有一定局限,Qwen1.5-1.8B-Chat作为一款轻量级模型,在资源受限的环境下展现出令人认可的表现。该模型在1.8B参数规模下运行,具备较快的推理速度,同时在中文理解与创意内容生成方面表现突出。

 京公网安备 11010802022788号
京公网安备 11010802022788号







