


 雷达卡
雷达卡



0 前言
近年来,随着毕业设计与答辩标准的不断提高,传统的课题逐渐暴露出创新不足、技术陈旧等问题,难以满足当前评审要求。不少学生反映其开发的系统在功能性、智能化程度方面无法达到预期水平,同时缺乏完整且高质量的学习参考资料。
为帮助大家高效完成毕业设计任务,减少不必要的重复劳动,本文介绍一个具有较高实用价值和研究深度的项目案例:
基于深度学习的Yolo11暴力行为识别系统(含源码与论文)
以下为该项目的综合评估(每项满分5分):
- 难度系数:3分
- 工作量:4分
- 创新点:5分
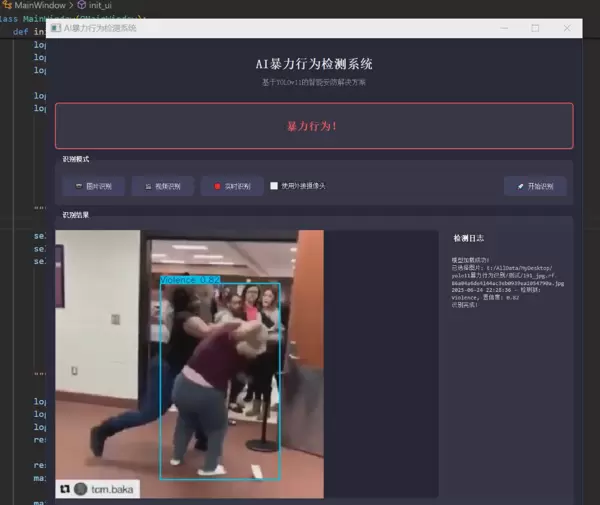
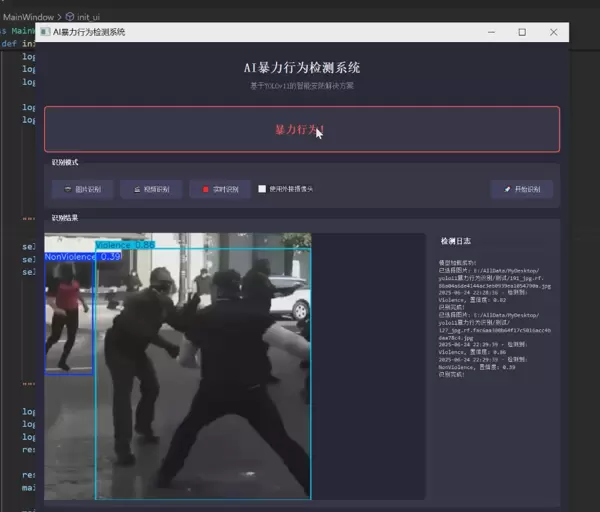
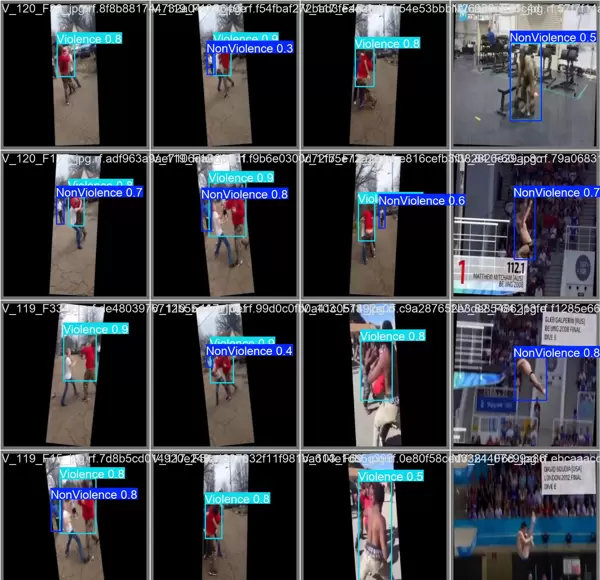
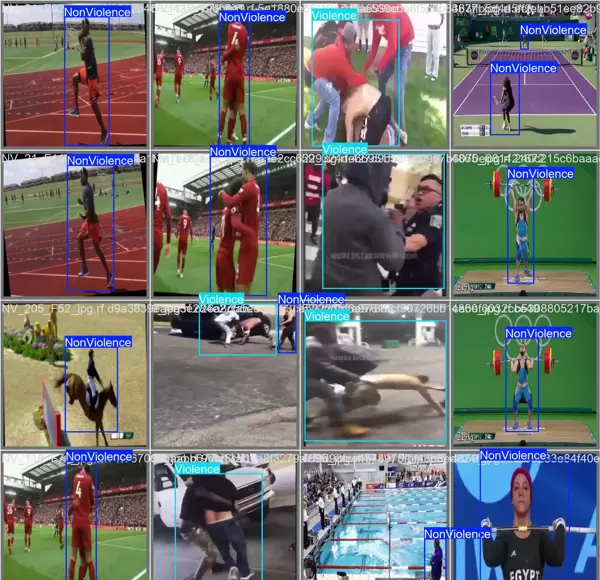
1 项目运行效果
本系统在多种真实场景下进行了测试,能够实时检测并标记视频流中的暴力行为,具备良好的鲁棒性与响应速度。
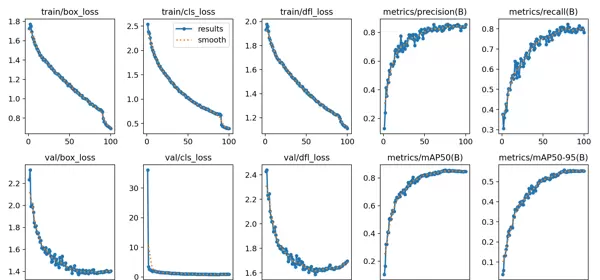
2 课题背景
2.1 社会安全现状与挑战
在全球城市化不断推进和社会结构日益复杂的背景下,公共安全管理面临巨大压力。据世界卫生组织(WHO)统计,每年因暴力事件导致的直接经济损失超过5000亿美元,间接影响更是难以量化。在中国,“平安城市”与“雪亮工程”等国家级安防战略持续推进,使得公共区域监控设备数量迅速增长。截至2023年底,全国部署的摄像头已突破4亿台,构建了全球规模最大的视频监控网络。
然而,尽管硬件设施高度普及,实际应用中仍存在显著问题:人工监控效率低下,研究表明,监控人员在持续观看视频20分钟后注意力明显下降,关键事件漏检率高达95%。尤其在地铁站、商场等人流密集区域,暴力行为突发性强、持续时间短,传统方式难以实现及时发现与干预,亟需引入智能技术提升响应能力。
2.2 传统监控系统的问题分析
现有视频监控体系主要存在以下几个方面的局限性:
- 被动响应机制:多数系统采用“事后回溯”的模式,仅能在事件发生后进行录像查阅,无法做到事前预警或事中干预。
- 过度依赖人力:监控值守完全依靠人工,易受疲劳、注意力分散等因素影响,难以保障全天候有效监控。
- 智能化水平低:缺乏对复杂行为的理解能力,特别是对于具有语义特征的暴力动作,传统算法难以准确识别。
- 数据处理效率差:面对海量视频数据,存储、检索及信息提取过程耗时长,难以满足实时分析需求。
2.3 计算机视觉技术的发展
近年来,计算机视觉领域取得显著进展,尤其是深度学习技术的广泛应用,使机器具备了接近人类的图像理解能力。卷积神经网络(CNN)在图像分类、目标检测等任务上表现出色,已成为该领域的核心技术支柱。
得益于OpenCV、TensorFlow、PyTorch等开源框架的成熟,以及GPU等硬件加速技术的发展,复杂模型的训练与实时推理成为可能,大幅降低了智能视觉系统的开发门槛,为新一代监控系统提供了坚实的技术支撑。
4 深度学习在安防领域的应用
深度学习已在多个安防场景中展现出强大潜力,典型应用包括:
- 人脸识别:用于重点人员布控与身份验证,识别准确率已超过99%。
- 行为分析:可识别跌倒、聚集、徘徊等异常行为,广泛应用于监狱、银行等敏感场所。
- 物品检测:自动识别刀具、枪支、易燃物等危险品,提升安检效率。
- 场景理解:对整体监控画面进行态势评估,判断潜在安全风险等级。
尽管如此,暴力行为检测作为一项高难度任务,仍面临诸多挑战。其表现形式多样、定义边界模糊、持续时间短暂,对算法的精确性与实时性提出了更高要求。
2.5 YOLO算法的优势与演进
YOLO(You Only Look Once)系列是目标检测领域的重要成果之一,自2016年提出以来经历了多次迭代优化。相较于R-CNN等两阶段检测方法,YOLO将检测任务转化为单次回归问题,实现了速度与精度的良好平衡。
YOLOv11作为最新版本,在保持高帧率处理能力的基础上,通过结构优化与训练策略改进,进一步提升了小目标检测能力和复杂场景适应性,特别适用于需要快速响应的安全监控场景。
2.6 暴力行为检测的特殊需求
暴力行为通常表现为肢体冲突、推搡、击打等动态动作,具有突发性强、动作幅度大但持续时间短的特点。此外,这类行为常发生在人群密集或遮挡严重的环境中,增加了检测难度。因此,系统不仅需要具备高精度的动作识别能力,还需支持实时处理、低延迟反馈,以确保及时报警与干预。
2.7 课题研究意义
本课题聚焦于利用先进深度学习模型实现自动化暴力行为识别,旨在弥补传统监控系统的功能短板。研究成果有助于推动智能安防系统的升级,提升公共场所的安全管理水平,具有重要的社会价值与应用前景。
3 设计框架
3.1 系统架构概述
3.1.1 整体架构图
系统由前端采集模块、核心处理单元与用户交互界面三大部分构成,形成闭环式智能分析流程。视频输入经预处理后送入YOLOv11模型进行行为识别,结果通过可视化界面实时展示,并支持告警提示与日志记录。
3.1.2 技术选型
关键技术栈包括:Python作为主开发语言,PyTorch用于模型训练与推理,OpenCV实现视频处理,Qt或Web前端构建交互界面,结合多线程机制保障系统流畅运行。
3.2 核心模块设计
3.2.1 YOLOv11模型训练模块
该模块负责数据集准备、标注清洗、模型训练与参数调优。采用迁移学习策略,在大规模行为数据集基础上进行微调,提升模型对暴力动作的敏感度与泛化能力。
3.2.2 交互系统模块
提供友好的操作界面,支持视频文件导入、实时摄像头接入、检测结果显示、报警提示等功能,便于用户监控与管理。
3.3 关键技术实现
3.3.1 多线程处理架构
为避免UI卡顿与数据积压,系统采用多线程设计,分离视频读取、模型推理与界面更新任务,确保各环节并行高效执行。
3.3.2 模型推理优化
通过模型剪枝、量化及TensorRT加速等方式,降低推理延迟,提升单位时间内处理帧数,满足实时性需求。
3.3.3 界面更新机制
使用信号-槽机制或异步回调方式同步检测结果至前端界面,保证显示内容与实际分析进度一致,增强用户体验。
3.4 系统工作流程
3.4.1 主流程图
系统启动后初始化资源,加载预训练模型,随后进入循环检测状态。根据输入源类型(本地视频或实时流),持续获取帧数据,执行行为分析,并将结果输出至界面或触发告警。
3.4.2 状态转换图
系统包含待机、检测中、报警、暂停等多个状态,依据用户操作与检测结果动态切换,逻辑清晰,易于控制。
3.5 伪代码示例
3.5.1 模型训练流程
初始化数据集
加载YOLOv11基础模型
设置超参数(学习率、批次大小等)
循环训练:
前向传播
计算损失
反向传播
参数更新
验证集评估
保存最优模型
3.5.2 界面交互逻辑
启动GUI 绑定按钮事件(开始/停止/加载视频) 开启后台检测线程 监听检测结果队列 更新UI显示框与状态栏
3.5.3 数据可视化流程
接收原始帧与检测结果 绘制边界框与标签 添加时间戳与置信度信息 合成输出视频流 实时渲染至窗口
3.6 设计要点说明
系统设计注重实用性与可扩展性,强调模型轻量化、处理实时性与界面友好性。通过模块化架构便于后续功能拓展,如增加多类别行为识别、远程推送告警等功能。
4 最后
本文围绕基于YOLOv11的暴力行为识别系统展开详细阐述,从社会需求出发,结合深度学习与计算机视觉技术,构建了一套可行的智能监控解决方案。该系统不仅具备较强的学术研究价值,也拥有广阔的落地应用场景。
3 设计框架
3.1 系统架构概述
3.1.1 整体架构图
┌───────────────────────┐ ┌───────────────────────┐ ┌───────────────────────┐
│ 数据采集模块 │ → │ YOLOv11检测引擎 │ → │ 可视化交互系统 │
└───────────┬───────────┘ └───────────┬───────────┘ └───────────┬───────────┘
│ │ │
↓ ↓ ↓
┌───────────────────────┐ ┌───────────────────────┐ ┌───────────────────────┐
│ 暴力行为数据集 │ │ 模型训练与优化 │ │ 检测结果可视化 │
└───────────────────────┘ └───────────────────────┘ └───────────────────────┘3.1.2 技术选型
- 目标检测:采用YOLOv11算法,兼顾检测精度与推理速度。
- 界面开发:基于PyQt5框架构建用户交互界面。
- 图像处理:利用OpenCV库完成视频帧读取、预处理与结果显示。
- 多线程支持:通过Python的QThread实现检测与界面更新的并发执行。
- 模型训练:使用Ultralytics提供的训练框架进行模型优化。
- 数据标注:借助LabelImg工具对暴力行为样本进行精确标注。
3.2 核心模块设计
- YOLOv11模型训练模块:负责数据集准备、模型训练及参数调优。
- 交互系统模块:集成输入控制、实时显示、日志记录和报警提示功能。
3.3 关键技术实现
3.3.1 多线程处理架构
为了保证界面响应流畅并实现持续检测,系统采用独立线程运行检测任务。
# 伪代码示例
class DetectionThread(QThread):
def run(self):
while running:
frame = get_frame()
results = model(frame)
emit results_signal
class MainWindow:
def start_detection(self):
thread = DetectionThread()
thread.results_signal.connect(update_ui)
thread.start()
3.3.2 模型推理优化
在推理阶段引入非极大值抑制(NMS)策略,并设置IOU阈值为0.45,提升检测结果的准确性。同时对输出类别进行筛选,判断是否存在“violence”标签以触发预警机制。
# 伪代码示例
def process_frame(frame):
# 使用NMS处理结果
results = model(frame, iou=0.45)
# 过滤暴力行为
violence = any("violence" in cls for cls in results.classes)
return results, violence
3.3.3 界面更新机制
UI组件通过信号槽机制异步更新,避免阻塞主线程。
# 伪代码示例
def update_image(frame):
convert frame to QImage
scale to display size
update QLabel
def update_log(message):
append message to QTextEdit
auto-scroll to bottom
3.4 系统工作流程
- 3.4.1 主流程图
- 3.4.2 状态转换图
3.5 伪代码示例
3.5.1 模型训练流程
该流程涵盖从加载预训练模型到最终导出ONNX格式的全过程。
# 伪代码示例
def train_model():
# 加载预训练模型
model = YOLO('yolov11s.pt')
# 训练配置
cfg = {
'data': 'violence.yaml',
'epochs': 100,
'imgsz': 640,
'batch': 16
}
# 开始训练
results = model.train(**cfg)
# 导出模型
model.export(format='onnx')
3.5.2 界面交互逻辑
定义主窗口类,初始化界面元素并绑定事件响应函数。
# 伪代码示例
class MainWindow:
def init_ui(self):
# 创建控件
create_buttons()
create_image_label()
create_log_panel()
# 连接信号
buttons.clicked.connect(handle_input)
def handle_input(self):
if image_mode:
5 模型性能优化方向
- 5.1 网络结构优化:选用高效backbone与neck结构,在降低计算开销的同时保障特征提取能力。
- 5.2 训练策略改进:融合先进损失函数与多样化数据增强手段,增强模型泛化性能。
- 5.3 多尺度检测:借助特征金字塔结构强化小尺寸目标的识别效果。
- 5.4 硬件适配优化:兼容多种硬件加速方案,提升实际部署灵活性。
2.6 暴力行为检测的特殊需求
相较于常规异常行为识别,暴力行为检测面临更多挑战,主要体现在以下几个方面:- 6.1 语义复杂性:暴力行为的界定受文化背景和具体情境影响较大,主观性强,缺乏统一标准。
- 6.2 动作多样性:涵盖肢体冲突、持械攻击等多种形式,动作模式差异显著,难以用单一特征建模。
- 6.3 时间短暂性:事件突发且持续时间短,系统需具备毫秒级响应能力。
- 6.4 场景干扰多:真实监控环境常存在遮挡、光照变化、视角变换等问题,增加检测难度。
2.7 课题研究意义
7.1 理论价值
- 拓展深度学习在复杂动态行为识别中的应用边界;
- 探索视频序列中时序信息与空间特征的有效融合方法;
- 研发适用于边缘设备部署的轻量化神经网络模型。
7.2 实践意义
- 增强公共区域的安全防控水平,有效减少暴力事件带来的危害;
- 降低安保人员人工巡检压力,提高监控系统的自动化效率;
- 为智慧城市的建设提供关键技术支持;
- 推动人工智能技术在安防产业中的落地与规模化应用。
3.5.3 数据可视化流程
# 伪代码示例
def visualize_results(results):
# 绘制检测框
frame = results.plot()
# 添加置信度信息
for box in results.boxes:
draw_text(frame, f"{box.cls}:{box.conf:.2f}")
# 更新界面
update_image(frame)
update_log(f"检测到{len(results.boxes)}个目标")
3.6 设计要点说明
性能考虑:
采用多线程机制,防止界面出现卡顿现象;
在图像处理过程中保持原始宽高比进行缩放,避免形变;
日志信息通过异步方式写入,提升系统响应效率。
界面设计原则:
采用响应式布局,适配不同屏幕分辨率;
使用深色主题,减少长时间观看带来的视觉疲劳;
提供清晰及时的状态反馈,增强用户交互体验。
模型训练优化:
应用迁移学习策略,加快模型收敛速度;
引入数据增强技术,提高模型泛化能力;
调整anchor box参数,使其更贴合暴力行为的特征分布。
扩展性设计:
代码结构采用模块化设计,便于功能拓展与维护;
通过配置文件驱动参数设置,实现灵活调整;
支持多种输入方式,包括图像、视频及实时摄像头接入。

项目包含内容

论文摘要
elif video_mode:
file = select_video()
detect_video(file)
else:
start_camera()
file = select_image()
detect_image(file)

 京公网安备 11010802022788号
京公网安备 11010802022788号







