


 雷达卡
雷达卡



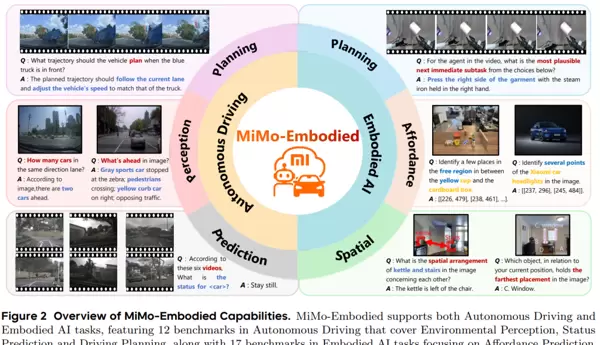
 这项研究的核心目标在于探索:同一个视觉语言模型能否在差异极大的任务场景中(如“抓取物体”与“驾驶车辆”)保持一致的理解方式与决策逻辑。这一问题长期以来制约着多场景智能体的发展,而MiMo-Embodied正是小米对此提出的系统性解决方案。
这项研究的核心目标在于探索:同一个视觉语言模型能否在差异极大的任务场景中(如“抓取物体”与“驾驶车辆”)保持一致的理解方式与决策逻辑。这一问题长期以来制约着多场景智能体的发展,而MiMo-Embodied正是小米对此提出的系统性解决方案。

 论文由小米智驾团队的郝孝帅担任核心第一作者,项目负责人则为小米智驾团队首席科学家陈龙博士。这也是陈龙团队加入小米后的首个重大研究成果。模型基于罗福莉团队此前发布的MiMo-VL进行继续训练(continue-train),因此作者列表中包含“罗福莉”。此前有媒体误读为罗福莉主导的项目,当事人已通过社交平台澄清事实。
论文由小米智驾团队的郝孝帅担任核心第一作者,项目负责人则为小米智驾团队首席科学家陈龙博士。这也是陈龙团队加入小米后的首个重大研究成果。模型基于罗福莉团队此前发布的MiMo-VL进行继续训练(continue-train),因此作者列表中包含“罗福莉”。此前有媒体误读为罗福莉主导的项目,当事人已通过社交平台澄清事实。
01 多任务全面领先
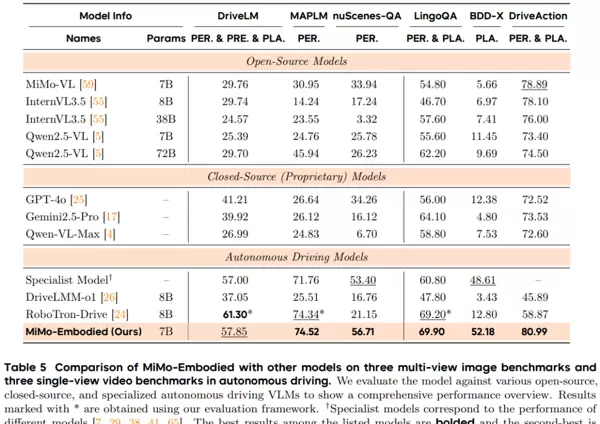
研究围绕两大方向展开系统性实验:具身智能与自动驾驶。整体结果显示,MiMo-Embodied在17个具身智能任务与12个自动驾驶任务中均取得最优或领先性能,在多数关键基准上位居榜首。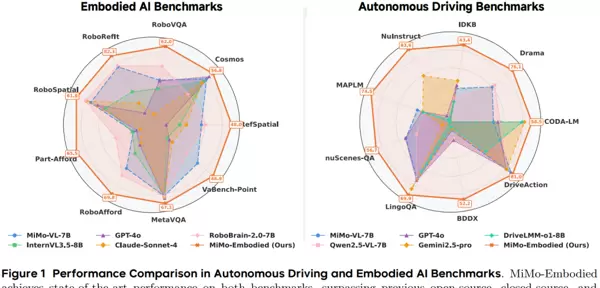 具身智能方面,评估涵盖三大能力维度:可供性推断、任务规划与空间理解。
- 可供性推断测试模型对物体使用方式的理解能力,例如识别可操作部位、判断物品放置区域、从相似物体中选出匹配描述的目标等。在RoboRefIt中,模型能精准定位高度相似物体中的目标;在Part-Afford中准确识别功能部件;在VABench-Point中根据文本描述输出精确坐标,五项主流基准均达到当前最佳水平。
具身智能方面,评估涵盖三大能力维度:可供性推断、任务规划与空间理解。
- 可供性推断测试模型对物体使用方式的理解能力,例如识别可操作部位、判断物品放置区域、从相似物体中选出匹配描述的目标等。在RoboRefIt中,模型能精准定位高度相似物体中的目标;在Part-Afford中准确识别功能部件;在VABench-Point中根据文本描述输出精确坐标,五项主流基准均达到当前最佳水平。
 - 任务规划关注模型在特定情境下的行动推理能力,包括预测任务下一步、选择正确操作动作或推断事件发展序列。在RoboVQA、Cosmos-Reason1和EgoPlan2等多个评测中,MiMo-Embodied均处于领先地位,展现出强大的任务结构理解和动态推理能力。
- 任务规划关注模型在特定情境下的行动推理能力,包括预测任务下一步、选择正确操作动作或推断事件发展序列。在RoboVQA、Cosmos-Reason1和EgoPlan2等多个评测中,MiMo-Embodied均处于领先地位,展现出强大的任务结构理解和动态推理能力。
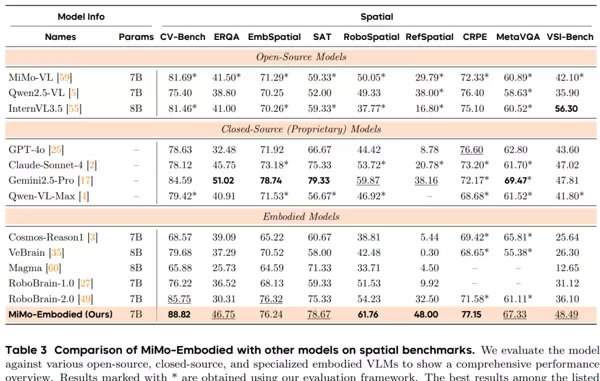
 - 空间理解要求模型准确把握场景内物体间的空间关系,如相对方位判断、图像对象定位、坐标输出及空间类文字问答。在九项代表性测试中,模型于CV-Bench、RoboSpatial、RefSpatial和CRPE-relation等核心基准获得最高分,在EmbSpatial与SAT任务中也位列第一梯队,体现出稳健的空间推理能力。
- 空间理解要求模型准确把握场景内物体间的空间关系,如相对方位判断、图像对象定位、坐标输出及空间类文字问答。在九项代表性测试中,模型于CV-Bench、RoboSpatial、RefSpatial和CRPE-relation等核心基准获得最高分,在EmbSpatial与SAT任务中也位列第一梯队,体现出稳健的空间推理能力。
 自动驾驶方面,实验覆盖三大核心模块:场景感知、行为预测与驾驶规划。
- 场景感知要求模型识别道路上的车辆、行人、交通标志,描述场景内容,发现潜在风险,并精确定位关键目标。在CODA-LM这类复杂环境理解任务中,其表现媲美甚至优于专用模型;在DRAMA中实现了最高的关键物体定位精度;在OmniDrive与MME-RealWorld中同样保持领先。
自动驾驶方面,实验覆盖三大核心模块:场景感知、行为预测与驾驶规划。
- 场景感知要求模型识别道路上的车辆、行人、交通标志,描述场景内容,发现潜在风险,并精确定位关键目标。在CODA-LM这类复杂环境理解任务中,其表现媲美甚至优于专用模型;在DRAMA中实现了最高的关键物体定位精度;在OmniDrive与MME-RealWorld中同样保持领先。
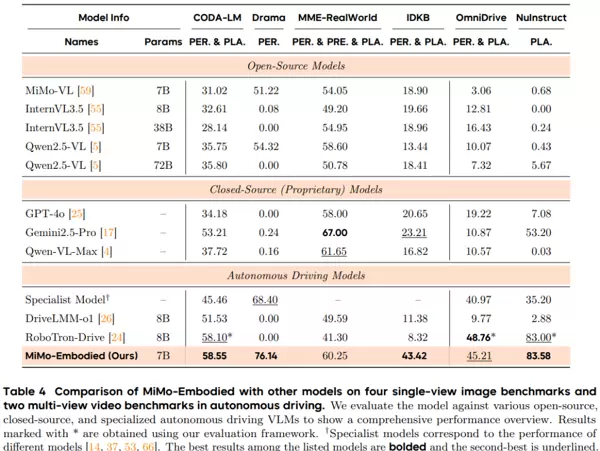 - 行为预测旨在评估模型对其他交通参与者未来行为的预判能力,如变道意图、让行判断或多视角下的交通流趋势分析。MiMo-Embodied在MME-RealWorld与DriveLM等基准中表现稳定且领先,显示出对动态交通环境的深刻理解。
- 驾驶规划则进一步要求模型生成合理的驾驶动作并解释决策依据,同时确保合规性和安全性。在多个权威基准中,模型均取得优异成绩:LingoQA中能准确解释驾驶行为;DriveLM中基于多视角输入做出合理路径规划;MAPLM中结合道路结构参与决策;BDD-X中清晰阐述驾驶理由。整体表现甚至超越部分专为自动驾驶设计的模型。
- 行为预测旨在评估模型对其他交通参与者未来行为的预判能力,如变道意图、让行判断或多视角下的交通流趋势分析。MiMo-Embodied在MME-RealWorld与DriveLM等基准中表现稳定且领先,显示出对动态交通环境的深刻理解。
- 驾驶规划则进一步要求模型生成合理的驾驶动作并解释决策依据,同时确保合规性和安全性。在多个权威基准中,模型均取得优异成绩:LingoQA中能准确解释驾驶行为;DriveLM中基于多视角输入做出合理路径规划;MAPLM中结合道路结构参与决策;BDD-X中清晰阐述驾驶理由。整体表现甚至超越部分专为自动驾驶设计的模型。

02 四阶段跨域训练框架
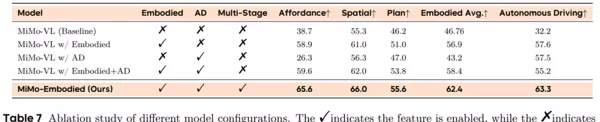
为了实现从单域到跨域的能力迁移,MiMo-Embodied采用了分阶段渐进式训练策略,构建了一个支持多场景共享感知与推理能力的统一架构。该框架成功验证了核心智能能力可在不同物理场景间有效复用,标志着小米在通用具身智能方向迈出实质性一步。

在实验成果的基础上,研究团队设计了一套包含四个阶段的系统性训练流程。该流程从基础的具身理解出发,逐步延伸至自动驾驶决策能力,并进一步发展出可解释的推理机制与更高的输出准确性。
整个训练体系依托于 Xiaomi LLM-Core(大语言核心团队)研发的统一视觉-语言基础模型 MiMo-VL 展开。罗福莉所在的团队正是这一模型的推出者。训练过程采用能力逐级递进的设计思路,每一阶段都为后续阶段奠定关键能力基础,从而构建出一条连贯且具备扩展潜力的模型演化路径。

第一阶段:具身智能的基础学习
此阶段聚焦于具身智能相关任务的监督训练,涵盖可供性推断、任务规划与空间理解等多个方向。通过这类数据的学习,模型逐步掌握物体结构识别、可操作区域判断、场景中空间关系的理解,并能够对任务流程进行合理的下一步预测。
经过本阶段训练后,模型获得了基本的空间推理能力、初步的任务规划技能,以及对环境可供性的感知和表达能力,为后续跨领域能力的发展打下根基。
第二阶段:自动驾驶领域的专项提升
进入第二阶段,模型开始接受自动驾驶领域的监督训练。训练内容包括多视角摄像头图像、驾驶视频片段、自动驾驶问答数据、关键目标坐标标注以及道路结构知识等。
在此过程中,模型逐渐学会解析复杂交通环境,识别各类交通元素,预测行人与其他车辆的行为趋势,并生成符合交通规则的驾驶策略。该阶段使其掌握了动态场景分析、意图识别与驾驶决策等核心能力。
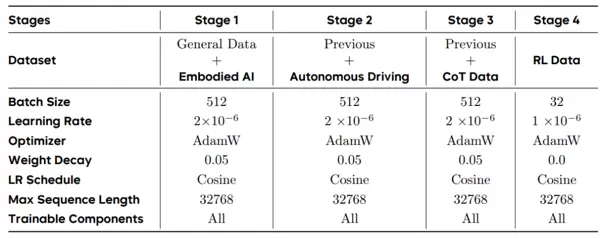
第三阶段:链式思维引导下的推理训练
第三阶段引入了“思维链”训练方法,旨在让模型学会显式地表达其推理过程。训练样本中包含了清晰的推理步骤,模型被引导按照“观察场景→分析要素→提出候选方案→给出理由→得出结论”的逻辑顺序组织输出。
结果表明,模型能够在具身任务与驾驶任务中均展现出连贯、透明的推理链条,显著提升了回答的一致性与可解释性。
第四阶段:强化学习驱动的精细优化
最后阶段采用强化学习进行微调,重点在于提升模型在细节层面的表现精度。例如,在多选题任务中根据答案正确与否提供奖励信号;在定位任务中依据预测区域与真实区域之间的 IoU 值给予精细化反馈;对于推理类输出,则通过预设格式模板严格约束响应形式。
借助这些结构化的奖励机制,模型在坐标定位准确率、推理质量及细粒度判断能力上均有明显进步,最终成长为一个能在多种任务场景下稳定运行的统一具身智能模型。

连接两个智能世界的起点
这项研究的意义不仅体现在性能指标上的领先,更在于它成功破解了一个长期困扰行业的难题:将原本彼此隔离的机器人操作与自动驾驶系统整合到同一个智能框架之中。
传统模型通常局限于单一领域——要么专注于室内具身任务,要么专攻自动驾驶。两者在场景设置、感知方式和动作执行上差异巨大,几乎无法共享任何通用能力。
然而,MiMo-Embodied 的实验结果表明,诸如空间理解、因果推理和动态场景分析等底层智能能力,实际上具备跨域迁移的潜力。机器人理解桌面物品的方式可以迁移到汽车对路口状况的认知中,而自动驾驶中处理交通流的经验也能反哺机器人任务规划的优化。
这意味着,“智能体”的能力边界首次实现了真正意义上的打通。
为了验证这种跨场景融合的有效性,团队还构建了一套前所未有的综合性评测体系,涵盖 17 个具身智能基准和 12 个自动驾驶基准,全面评估模型在可供性判断、任务规划、空间认知、环境感知、行为预测及驾驶决策等方面的能力。
模型在如此广泛而复杂的测试集上依然保持领先表现,说明其优势并非来自短板补偿,而是源于真正的跨领域泛化能力。这不仅验证了模型本身的价值,也为行业树立了“跨域评测”的新标杆。
更重要的是,MiMo-Embodied 提出了一条可复现的技术路径:先学习具身任务,再融入自动驾驶知识,接着加入链式推理训练,最后通过强化学习精调细节。这条四阶段训练路线,实质上是一条通往“通用具身智能体”的可行课程体系。
它向业界传递了一个明确信号:智能体的各项能力不必分散于多个专用模型中,而是可以通过分层积累的方式,在一个统一架构内实现多场景下的稳定输出。
从产业应用角度看,这一成果如同一次“解锁”行动。小米将这套跨域智能方案开放给开源社区,意味着即使是资源有限的小型团队,也能在其基础上进行二次开发,打造出既能操控机械臂又能驾驶车辆的多功能智能体。
如今,电动车正日益演变为“带轮子的智能体”,机器人则趋向于“带四肢的智能体”。MiMo-Embodied 的出现,使这两条原本平行发展的技术路线首次有了交汇的可能。
尤为难得的是,该模型并非仅停留在概念验证层面,而是在 17 项具身测试与 12 项自动驾驶测试中均表现出强劲竞争力,甚至超越了不少闭源私有模型。
这项工作所展示的,已不止是一种新型模型架构,更是向整个行业证明:自动驾驶与具身智能可以在同一系统中完成训练、评估与部署。这种统一范式为未来智能体的发展开辟了全新方向,或将重塑多场景智能系统的整体格局。

首篇论文背后的科研力量
这是小米具身智能团队发布的首篇学术论文,由小米智驾团队的郝孝帅担任第一作者,项目总体负责人是小米智驾团队首席科学家陈龙。

郝孝帅于今年8月正式加入小米汽车自动驾驶团队,现任自动驾驶与具身智能算法专家,专注于自动驾驶感知技术及具身智能基座大模型的研究。他博士毕业于中国科学院大学信息工程研究所,在学术与工业界均拥有深厚积累。
在攻读博士学位期间,他曾赴亚马逊实习,师从知名学者李沐,并在北京人工智能研究院担任研究员,深度参与Robobrain 1.0与Robobrain 2.0等关键项目。自加入小米以来,他作为第一核心成员主导推出了MiMo-Embodied——这是首个实现自动驾驶与具身智能统一的基座大模型,标志着其在该领域的重要突破。
此外,郝孝帅已在Information Fusion、NeurIPS、ICLR、CVPR、ECCV、AAAI、ICRA等国际顶级期刊和会议上发表论文五十余篇,并多次在CVPR、ICCV等国际竞赛中斩获前三名,展现出扎实的科研实力与持续创新能力。

项目另一位核心人物陈龙博士也于今年加盟小米,出任小米汽车Principal Scientist,负责自动驾驶与机器人部门的视觉语言行为(VLA)方向。他此前在英国端到端自动驾驶领军企业Wayve担任Staff Scientist,带领团队成功研发并部署全球首个上车级视觉语言自动驾驶系统Lingo,成果受到《财富》、《金融时报》、MIT Technology Review等多家国际权威媒体广泛报道。
更早之前,他在Lyft自动驾驶部门主导基于众包数据的深度学习规划模型研发工作。凭借在辅助驾驶中引入VLA模型的开创性贡献,陈龙入选《麻省理工科技评论》2025年度亚太区“35岁以下科技创新35人”榜单。
加入小米后,陈龙牵头组建并领导VLA团队,致力于推进端到端自动驾驶大模型的技术演进,重点提升模型在复杂交通环境下的泛化能力、推理效率与可解释性。他与叶航军、陈光、王乃岩共同构成小米智驾团队的核心技术骨干,成为当前小米智能驾驶体系架构的关键支撑力量。

作者主页:
https://haoxiaoshuai.github.io/homepage/
https://www.linkedin.com/in/long-chen-in/
论文链接:
https://arxiv.org/abs/2511.16518
本文仅做学术分享,如有侵权,请联系删文。





 京公网安备 11010802022788号
京公网安备 11010802022788号







