


 雷达卡
雷达卡



基于布谷鸟优化算法优化随机森林的分类预测模型(CSO-RF)
在机器学习与数据挖掘领域,分类任务是核心应用之一。随机森林(Random Forest, RF)因其出色的分类性能和鲁棒性被广泛使用。为进一步提升其预测精度并优化关键参数,本文引入布谷鸟搜索算法(Cuckoo Search Optimization, CSO),构建CSO-RF混合模型,并结合交叉验证策略有效抑制过拟合现象。以下将详细阐述该方法的原理及Matlab实现过程。
1. 随机森林算法概述
随机森林是一种集成学习方法,通过构建多个决策树并进行投票或平均来完成分类或回归任务。每棵树在训练过程中采用自助采样法(Bootstrap)选取样本子集,并在节点分裂时随机选择特征子集,从而增强模型多样性,降低方差,提高泛化能力。最终输出结果由所有树的集体决策决定。
2. 布谷鸟优化算法(CSO)原理
布谷鸟优化算法灵感来源于布谷鸟的寄生繁殖行为。该算法假设每只布谷鸟产下一枚卵(即一个潜在解),并将卵放入其他宿主鸟巢中。若宿主发现外来卵,则可能抛弃该巢或重新选址。在优化过程中,每个鸟巢代表一组待优化参数,算法通过莱维飞行机制生成新解,并依据适应度值保留优质解,淘汰劣质解,逐步逼近全局最优。
3. CSO与RF的融合机制
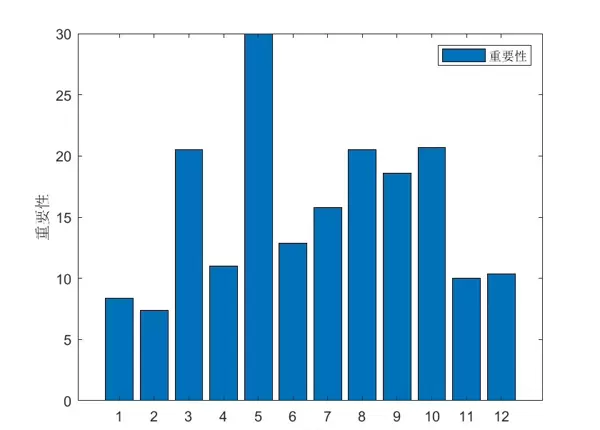
将CSO应用于随机森林的核心目标是优化其超参数配置,例如决策树数量、最小叶节点样本数等。CSO将这些参数编码为鸟巢中的位置向量,通过迭代更新寻找使分类误差最小的参数组合。该过程可显著提升RF在训练集上的表现,同时借助交叉验证确保模型具备良好的泛化性能,避免因过度拟合导致测试性能下降。
4. 交叉验证防止过拟合
为准确评估模型稳定性并减少过拟合风险,采用K折交叉验证策略。具体做法是将原始数据划分为K个互斥子集,依次取其中一子集作为验证集,其余K-1个用于训练模型,重复K次后取平均性能指标作为最终评价结果。此方法能更真实地反映模型在未知数据上的表现。
5. Matlab代码实现流程
本实现基于Matlab R2018b及以上版本,无需额外安装工具箱,仅需使用内置函数即可运行,适用于Windows 64位操作系统。
数据加载部分
data = load('your_data_file.mat');
X = data.features;
Y = data.labels;
从指定的.mat文件中读取特征矩阵X和标签向量Y,请根据实际路径替换'your_data_file.mat'。数据格式应为结构清晰的数值型矩阵。
XY参数初始化设置
numTrees = 100; minLeaf = 5;
设定随机森林初始参数:决策树数量为100棵,最小叶节点样本数为5。这些参数将在后续由CSO算法动态调整以寻找最优配置。
numTreesminLeaf布谷鸟优化算法执行步骤
鸟巢位置初始化
solutions = rand(nests, d + 1);
for i = 1:nests
solutions(i, end) = fitness(solutions(i, 1:d), X, Y, numTrees, minLeaf);
end
随机生成nests个初始解(即参数组合),每一行前d列为参数向量,最后一列存储对应适应度值。适应度函数通过构建当前参数下的随机森林模型,计算其在训练集上的分类错误率。
fitness主循环迭代过程
for gen = 1:maxgen
% 生成新解
new_solutions = zeros(nests, d + 1);
for i = 1:nests
new_solutions(i, 1:d) = solutions(i, 1:d) + 0.01 * randn(1, d);
new_solutions(i, end) = fitness(new_solutions(i, 1:d), X, Y, numTrees, minLeaf);
end
% 比较新旧解并更新最优位置
[~, best_index] = min([solutions(:, end); new_solutions(:, end)]);
if best_index <= nests
best_solution = solutions(best_index, :);
else
best_solution = new_solutions(best_index - nests, :);
end
% 模拟“发现外来蛋”机制,以概率pa替换最差解
for i = 1:nests
if rand < pa
worst_index = find(solutions(:, end) == max(solutions(:, end)), 1);
solutions(worst_index, 1:d) = rand(1, d);
solutions(worst_index, end) = fitness(solutions(worst_index, 1:d), X, Y, numTrees, minLeaf);
end
end
end
在每次迭代中,利用高斯扰动生成新解,并比较其适应度以更新种群。同时按照预设概率pa替换最差个体,模拟自然淘汰机制,推动种群向更优方向进化。
% 加载数据
data = load('your_data_file.mat'); % 替换为你的数据文件名
X = data.features; % 特征数据
Y = data.labels; % 标签数据
% 设置随机森林参数
numTrees = 100; % 决策树数量,可通过CSO优化
minLeaf = 5; % 最小叶子节点样本数
% 布谷鸟优化算法相关参数
n = size(X, 1); % 样本数量
d = size(X, 2); % 特征数量
pa = 0.25; % 发现外来蛋的概率
nests = 20; % 鸟巢数量
maxgen = 50; % 最大迭代次数
% 初始化鸟巢位置(随机森林参数组合)
solutions = rand(nests, d + 1);
for i = 1:nests
solutions(i, end) = fitness(solutions(i, 1:d), X, Y, numTrees, minLeaf);
end
% 布谷鸟优化算法主循环
for gen = 1:maxgen
% 生成新的鸟巢位置
new_solutions = zeros(nests, d + 1);
for i = 1:nests
new_solutions(i, 1:d) = solutions(i, 1:d) + 0.01 * randn(1, d);
new_solutions(i, end) = fitness(new_solutions(i, 1:d), X, Y, numTrees, minLeaf);
end
% 比较并更新鸟巢位置
[~, best_index] = min([solutions(:, end); new_solutions(:, end)]);
if best_index <= nests
best_solution = solutions(best_index, :);
else
best_solution = new_solutions(best_index - nests, :);
end
% 发现外来蛋并随机替换
for i = 1:nests
if rand < pa
worst_index = find([solutions(:, end)] == max([solutions(:, end)]), 1);
solutions(worst_index, 1:d) = rand(1, d);
solutions(worst_index, end) = fitness(solutions(worst_index, 1:d), X, Y, numTrees, minLeaf);
end
end
% 更新全局最优解
[~, best_index] = min([solutions(:, end); new_solutions(:, end)]);
if best_index <= nests
best_solution = solutions(best_index, :);
else
best_solution = new_solutions(best_index - nests, :);
end
% 记录每次迭代的最优适应度
fitness_trace(gen) = best_solution(end);
end
% 使用最优参数构建随机森林模型
optimal_numTrees = round(best_solution(1));
optimal_minLeaf = round(best_solution(2));
rfModel = TreeBagger(optimal_numTrees, X, Y, 'MinLeafSize', optimal_minLeaf);
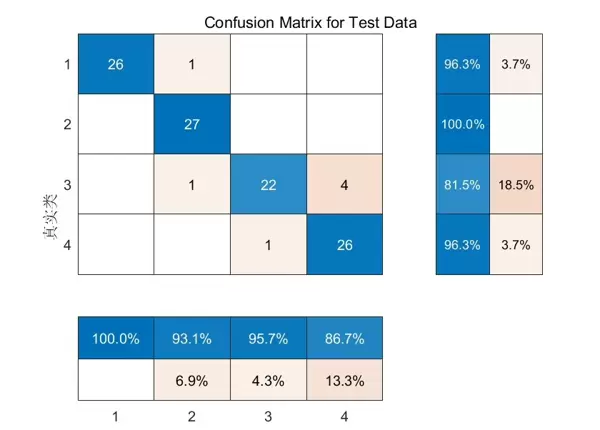
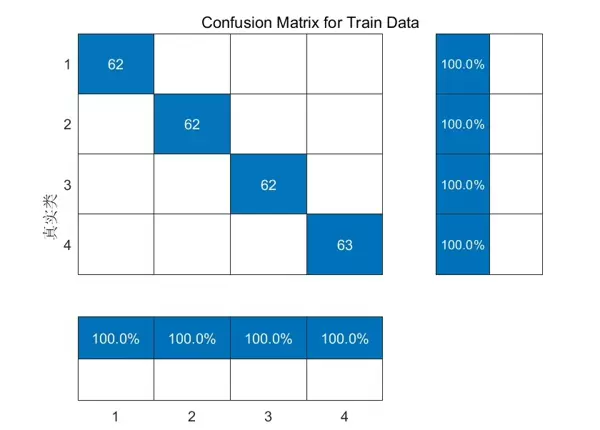
% 交叉验证
cv = cvpartition(Y, 'KFold', 5); % 5折交叉验证
accuracy = zeros(cv.NumTestSets, 1);
for i = 1:cv.NumTestSets
testIdx = cv.test(i);
trainIdx = ~testIdx;
XTrain = X(trainIdx, :);
YTrain = Y(trainIdx);
XTest = X(testIdx, :);
YTest = Y(testIdx);
local_rfModel = TreeBagger(optimal_numTrees, XTrain, YTrain, 'MinLeafSize', optimal_minLeaf);
YPred = predict(local_rfModel, XTest);
accuracy(i) = sum(YPred == YTest) / numel(YTest);
end
mean_accuracy = mean(accuracy);
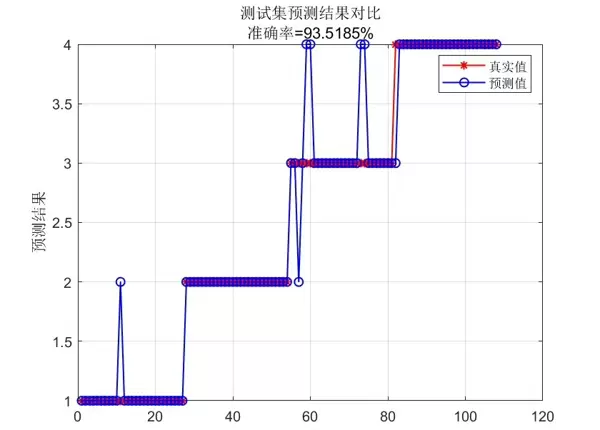
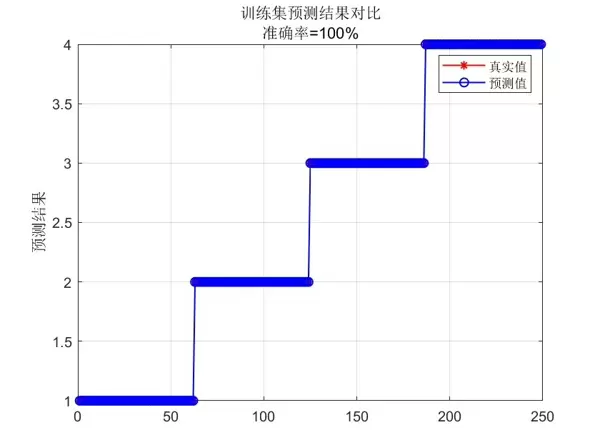
fprintf('平均分类准确率: %.2f%%\n', mean_accuracy * 100);
% 定义适应度函数
function fit = fitness(params, X, Y, numTrees, minLeaf)
numTrees = round(params(1));
minLeaf = round(params(2));
rfModel = TreeBagger(numTrees, X, Y, 'MinLeafSize', minLeaf);
YPred = predict(rfModel, X);
fit = sum(YPred ~= Y) / numel(Y);
endpaoptimalminLeafrfModel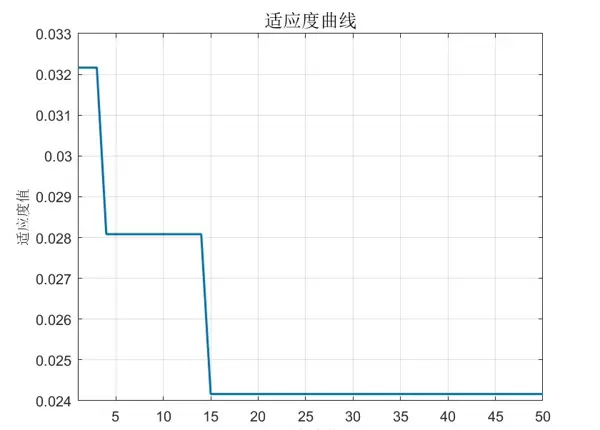

 京公网安备 11010802022788号
京公网安备 11010802022788号







