


 雷达卡
雷达卡



EverMemOS 的简介
EverMemOS 是一个开源、面向企业级应用的智能记忆系统,致力于打造具备长期记忆能力的 AI 代理。其核心目标是构建一个“永不遗忘”的认知体系,使每次对话都能基于历史交互进行深化理解与响应。
不同于传统仅用于信息回溯的记忆数据库,EverMemOS 具备更强的认知处理能力。它不仅能“记住”过往对话内容,更能通过语义分析和上下文关联,“理解”这些记忆背后的意义,并将其应用于当前决策中。该系统可为对话式 AI 提供持续的记忆支持,通过对交流内容的信息提取、结构化存储与高效检索,帮助 AI 维持连贯语境、回忆用户行为轨迹,并逐步构建动态用户画像,从而实现更自然、个性化且富有逻辑性的交互体验。
在 LoCoMo 基准测试中,采用 EverMemOS 构建的方法实现了 92.3% 的推理准确率(由 LLM-Judge 评估),表现优于同期参与评测的其他方案。相关技术论文正在撰写中。
1、主要特性
- 连贯叙事:突破碎片化记忆局限,系统能自动整合分散的对话片段,形成围绕主题的完整叙述流。例如,在处理多个并行会话时,能够清晰区分“项目A进度讨论”与“团队B策略会议”,并在各自语境下维持逻辑一致性。AI 不再只是回应单条语句,而是理解整个对话脉络。
- 有据感知:超越简单检索机制,具备情境感知(Contextual Awareness)能力。系统能主动识别记忆与当前任务之间的潜在联系。比如当用户请求美食推荐时,AI 可自动调取“用户两天前接受牙科手术”的记录,排除硬质或刺激性食物建议,体现深层次的理解与关怀。
- 鲜活画像:用户画像并非静态存档,而是随每一次互动实时演进。系统持续更新对用户的偏好、表达风格及兴趣点的认知,使得 AI 在长期交互中不断“学习你是谁”,而非仅仅“记得你说过什么”。
2、系统架构
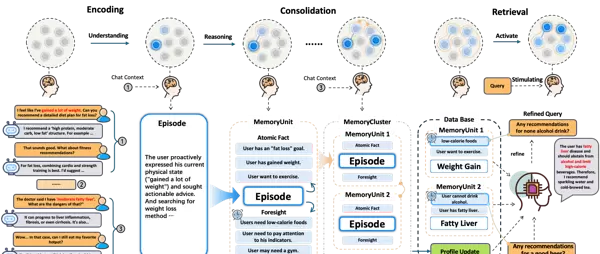
EverMemOS 的运行机制围绕两大核心模块展开:记忆构建(Memory Construction)与记忆感知(Memory Perception),共同构成一个从信息摄入到智能输出的认知闭环。
通过“结构化记忆 → 多策略召回 → 智能检索 → 情境推理”的流程链条,系统实现了真正意义上的“带记忆思考”。
记忆构建层(Memory Construction Layer)
核心组件:
- 原子记忆单元(MemCell):从原始对话中抽取的关键信息点,作为后续组织与引用的基本单位。
- 多层次记忆结构:将相关对话按主题和故事线聚合,形成可复用的层级记忆网络。
- 多类型记忆分类:涵盖情节、人物画像、个人偏好、关系图谱、语义知识、基础事实以及核心关键记忆等多种维度。
工作流程:
- MemCell 提取:识别对话中的重要事件、意图或状态变化,生成标准化的记忆单元。
- 记忆整合:依据话题归属和参与者身份,将 MemCell 聚合成更高层次的情节段落或用户画像条目。
- 存储与索引:完成数据持久化,并建立关键词索引与语义向量索引,确保后续快速检索。
记忆感知层(Memory Perception Layer)
智能检索机制:
- 混合检索(RRF Fusion):并行执行语义相似度匹配与关键词匹配,利用倒数排序融合(RRF)算法整合结果,提升覆盖广度与精度。
- 智能重排(Reranker):使用深度模型对候选记忆进行相关性打分与重新排序,优先呈现最相关的记忆内容。
Agentic 检索增强:
- LLM 引导的多轮回忆:当初始检索结果不足时,系统自动生成2-3个补充查询,发起并行检索并将结果融合,主动填补信息盲区。
- 多视角查询策略:针对复杂意图,分解为多个互补角度的查询请求,通过多路 RRF 融合提升对模糊或深层需求的响应能力。
轻量级快速模式:
专为低延迟场景设计,跳过 LLM 参与环节,直接启用基于 RRF 的混合检索路径,在响应速度与检索质量之间实现灵活权衡。
推理融合(Reasoning Fusion):
将召回的多层次记忆(如情节背景、用户画像、偏好设置等)与当前对话上下文拼接输入至模型,促使 AI 在明确证据基础上生成回应,有效抑制幻觉现象。
安装与使用指南
1、安装步骤
环境准备(Prerequisites)
- Python >= 3.9
- pip 包管理工具
- 可选:GPU 支持以加速嵌入与重排模型推理
- 基本依赖库:torch, transformers, faiss-cpu/gpu, sentence-transformers 等
安装流程(Installation)
- 克隆项目仓库:
git clone https://github.com/EverMind-AI/EverMemOS.git - 进入项目目录:
cd EverMemOS - 创建虚拟环境(推荐):
python -m venv venvsource venv/bin/activate # Linux/Macvenv\Scripts\activate # Windows - 安装依赖:
pip install -r requirements.txt - (可选)安装开发依赖:
pip install -r requirements-dev.txt
2、使用方式
T1、运行演示 Demo(推荐入门方式)
执行内置演示脚本,快速体验系统功能:
python demo.py该脚本将启动一个交互式对话界面,展示记忆提取、存储与检索全过程。
T2、执行评测流程(Evaluation)
运行基准测试脚本,验证系统性能:
python evaluate.py --benchmark locomo支持多种评估模式,可用于对比不同配置下的准确率与响应效率。
T3、调用 API 接口
系统提供 RESTful API 端点,支持外部系统集成。
存储单条消息记忆
发送 POST 请求至指定端点,录入单条对话记忆:
POST /api/v1/memory/single
Content-Type: application/json
{
"user_id": "user_123",
"message": "我最近在考虑去云南旅行。",
"timestamp": "2025-04-01T10:00:00Z"
}
批量存储群聊记忆
用于导入多用户、多轮次的群组对话数据:
POST /api/v1/memory/batch
Content-Type: application/json
{
"conversation_id": "group_trip_plan_01",
"messages": [
{
"user_id": "user_123",
"content": "我想五一去大理。",
"time": "2025-04-01T10:05:00Z"
},
{
"user_id": "user_456",
"content": "丽江也不错,我们可以顺路。",
"time": "2025-04-01T10:07:00Z"
}
]
}
应用场景实例
1、多线程对话管理
适用于客服系统或多任务助手场景。EverMemOS 能够准确区分不同话题线程,保持各线程内部记忆独立且连贯。即使用户在多个主题间频繁切换,AI 仍能精准还原每个话题的历史上下文,避免混淆。
2、个性化智能推荐
结合用户长期行为记忆(如饮食禁忌、消费偏好、过往选择),系统可在推荐过程中融入深层理解。例如,在推荐电影时不仅考虑类型喜好,还能结合近期情绪表达或生活事件调整建议方向。
3、动态用户画像构建
随着每次交互,系统自动更新用户画像维度,包括性格倾向、沟通风格、价值观偏好等。该画像可用于预测用户反应、优化语言风格匹配度,提升整体交互舒适感。
4、基准测试与学术研究
EverMemOS 已被用于 LoCoMo 等对话记忆基准测试,展现出卓越的记忆推理能力。其开放架构也适合作为学术研究平台,支持对长期记忆建模、检索增强生成(RAG)、认知架构设计等方向的探索。
系统要求 - Python 3.10 或更高版本 - uv(推荐使用的包管理工具) - Docker 20.10 及以上版本,Docker Compose 2.0+ - 至少 4GB 的可用内存(用于运行 Elasticsearch 和 Milvus 服务) 安装流程 1. 克隆项目仓库 执行以下命令将源码下载至本地: git clone https://github.com/EverMind-AI/EverMemOS.git cd EverMemOS 2. 启动依赖服务(基于 Docker) 使用 Docker Compose 一键部署所有必需的后端服务,包括 MongoDB、Elasticsearch、Milvus 和 Redis。 bash docker-compose up -d 各服务默认端口映射如下: - MongoDB: 27017 - Elasticsearch: 19200 - Milvus: 19530 - Redis: 63793. 安装 uv 包管理器 若尚未安装 uv,请通过官方脚本进行安装: bash curl -LsSf https://astral.sh/uv/install.sh | sh 4. 安装项目依赖项 使用 uv 安装全部 Python 依赖包: bash uv sync 5. 配置环境变量文件 复制模板生成本地配置文件,并根据需要填写 API 密钥等信息: bash cp env.template .env 请在 .env 文件中设置 LLM_API_KEY、DEEPINFRA_API_KEY 等关键参数。 使用方式说明 在开始使用前,请确保已成功启动 API 服务。 T1、运行演示示例(推荐入门方式) 基础功能演示 该模式适合快速体验核心记忆存储与检索能力。操作步骤如下: - 确保 API 服务正在运行(如上一步已完成)。 - 打开新终端窗口,执行简单测试脚本。# 在一个终端中启动并保持运行 uv run python src/bootstrap.py src/run.py --port 8001此过程会写入 4 条关于运动爱好的对话记录,等待约 10 秒以完成索引构建,随后发起三次不同类型的查询请求,系统将返回匹配的记忆内容并附带解释说明。 全功能聊天演示 可清空当前数据库,加载预设的中文对话数据(data/assistant_chat_zh.json),并通过 API 接口实现完整的记忆存取流程。uv run python src/bootstrap.py demo/simple_demo.py带记忆的交互式聊天程序 启动后支持自定义选项,包括语言选择、场景模式、对话组别及检索策略,用户可与具备长期记忆能力的 AI 进行自然对话。提取记忆:处理示例对话数据并构建记忆库。 # 在另一个终端中运行 uv run python src/bootstrap.py demo/extract_memory.pyT2、执行评测任务(Evaluation) 本框架内置对主流长时记忆数据集(如 LoCoMo)的支持,可用于评估不同系统的性能表现。# 在另一个终端中运行 uv run python src/bootstrap.py demo/chat_with_memory.py测试结果将自动保存至 evaluation/results/{dataset}-{system}/ 目录下,便于后续分析和对比。 T3、直接调用 API 接口 单条消息记忆存储 可通过 API 提交单条用户消息,系统将其编码并持久化存储。快速测试 (Smoke Test): uv run python -m evaluation.cli --dataset locomo --system evermemos --smoke 完整评测: uv run python -m evaluation.cli --dataset locomo --system evermemos记忆检索机制 - 轻量级检索(Lightweight Retrieval):融合向量搜索、关键词匹配与 RRF 加权策略,响应速度快,适用于实时场景。curl -X POST http://localhost:8001/api/v3/agentic/memorize \ -H "Content-Type: application/json" \ -d '{ "message_id": "msg_001", "create_time": "2025-02-01T10:00:00+08:00", "sender": "user_103", "sender_name": "Chen", "content": "我们需要在本周完成产品设计", "group_id": "group_001", "group_name": "项目讨论组", "scene": "group_chat" }'- Agentic 检索(Agentic Retrieval):由大语言模型驱动的智能检索,能生成更精准的查询表达,虽然延迟较高,但召回质量更优。curl -X POST http://localhost:8001/api/v3/agentic/retrieve_lightweight \ -H "Content-Type: application/json" \ -d '{ "query": "用户喜欢什么运动?", "user_id": "user_001", "data_source": "episode", "memory_scope": "personal", "retrieval_mode": "rrf" }'批量导入群聊记忆数据 提供专用脚本支持标准格式的群组聊天记录批量导入,适用于大规模训练或迁移场景。curl -X POST http://localhost:8001/api/v3/agentic/retrieve_agentic \ -H "Content-Type: application/json" \ -d '{ "query": "用户可能喜欢吃什么?", "user_id": "user_001", "group_id": "chat_group_001", "top_k": 20, "llm_config": { "model": "gpt-4o-mini", "api_key": "your_api_key" } }'实际应用案例 以下是 EverMemOS 在多个典型场景中的落地实践,体现其在真实环境下的技术价值。 1. 多线程对话上下文管理 应用场景: 在 Slack、Teams 等协作平台中,同一频道内常存在多个并行话题,例如“项目A进度汇报”与“团队B下周团建安排”。 解决方案: EverMemOS 能够自动识别并分离不同主题的讨论流,为每个话题维护独立的记忆上下文。当 AI 回应某个具体问题时,仅关联对应语境的信息,避免跨主题干扰,保障对话逻辑清晰连贯。 2. 基于记忆感知的个性化推荐 应用场景: 用户向智能助手提问:“有什么好吃的推荐吗?” 解决方案: AI 不仅基于通用偏好提供建议,还会激活历史记忆模块,回忆起“用户两天前刚接受牙科手术”这一事实,主动排除坚硬或刺激性食物,转而推荐粥类、果泥等温和软食。这种“有据可依”的推理体现了系统的情境理解与人文关怀能力。 3. 动态演进的用户画像构建 应用场景: 用户长期与 AI 助手互动,交流内容涵盖兴趣、习惯、情绪等多个维度。 解决方案: 系统持续积累和更新用户特征,例如记住其为某足球俱乐部忠实粉丝、倾向于简短回答风格、常在晚间咨询健康建议等。这些细节构成一个“活的”用户画像,使 AI 的回应逐渐贴近个体特质,从标准化服务进化为高度个性化的陪伴型智能体。 4. 学术研究与基准测试支持 应用场景: 研究人员需在统一标准下比较不同长时记忆架构的表现。 解决方案: 项目集成完整的评测套件,兼容 LoCoMo、LongMemEval、PersonaMem 等公开学术数据集。开发者可利用该框架开展算法实验、性能调优与成果验证,推动相关领域的技术创新与发展。 综上所述,EverMemOS 成功实现了将碎片化对话转化为结构化、可检索、可推理的智能记忆体系,在企业协作、个人助理、学术研究等多种高价值场景中展现出卓越潜力。# 存储中文群聊数据 uv run python src/bootstrap.py src/run_memorize.py \ --input data/group_chat_zh.json \ --api-url http://localhost:8001/api/v3/agentic/memorize \ --scene group_chat

 京公网安备 11010802022788号
京公网安备 11010802022788号







