


 雷达卡
雷达卡



一、ID3 决策树的可解释性与剪枝必要性
在机器学习模型中,决策树因其结构清晰、逻辑直观而具备出色的“可解释性”。其中,ID3 算法以信息增益为特征选择标准,是理解分类机制的经典入门方法。然而,若不对生成过程加以控制,ID3 易构建出深度过大、节点过多的树形结构,导致对训练数据过度拟合,削弱其在未知样本上的泛化能力。为此,预剪枝与后剪枝成为提升模型鲁棒性的关键技术手段。
本文围绕贷款审批场景,完整实现 ID3 决策树从“未剪枝”到“预剪枝”再到“后剪枝”的全流程开发,并通过同页并列可视化方式对比三类模型结构差异,兼顾理论推导与工程实践。
二、为何必须进行剪枝?—— 核心动因解析
- 过度拟合风险:当树无限生长时,可能出现叶子节点仅对应单一样本的情况,模型记住了训练集噪声而非规律,无法适应新数据;
- 模型复杂度高:过深的树结构不仅难以解释,还容易受到个别异常值干扰,影响稳定性;
- 剪枝的核心价值:通过“提前终止分裂(预剪枝)”或“事后删除冗余分支(后剪枝)”,有效压缩模型规模,在保持预测性能的同时增强泛化能力。
三、实验基础:数据与算法原理
1. 数据集说明
采用贷款审批分类数据集,包含训练集(
,共16条记录)和测试集(dataset.txt
,共7条记录),格式为CSV文本文件。testset.txt
特征字段(均为离散型):
- 年龄段:0 = 青年,1 = 中年,2 = 老年;
- 有工作:0 = 无,1 = 有;
- 有自己的房子:0 = 无,1 = 有;
- 信贷情况:0 = 一般,1 = 好,2 = 非常好;
标签:0 = 拒绝贷款,1 = 批准贷款。
2. ID3 算法核心原理简述
信息熵(Entropy):用于衡量数据集纯度,熵越低表示类别越集中。计算公式如下:
Entropy(D) = -∑i=1k (|Ci| / |D|) × log(|Ci| / |D|)
其中 D 表示当前数据集,Ci 是第 i 类别的子集。
信息增益(Gain):表示使用某一特征划分后带来的信息不确定性减少量。增益越大,说明该特征分类效果越好。
Gain(D, A) = Entropy(D) - ∑v=1V (|Dv| / |D|) × Entropy(Dv)
其中 A 为待选特征,Dv 为特征 A 取第 v 个值所对应的子集。
四、代码实现:三种策略一体化构建
系统实现了未剪枝、预剪枝与后剪枝三种模式的统一框架,支持灵活切换与结果对比。
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch
# ---------------------- 1. 数据加载 ----------------------
def load_data(file_path):
"""读取特征矩阵、标签向量与特征名称"""
data = np.loadtxt(file_path, delimiter=',', dtype=int)
return data[:, :-1], data[:, -1], ['年龄段', '有工作', '有自己的房子', '信贷情况']
# ---------------------- 2. 核心计算工具(熵+信息增益) ----------------------
def calculate_entropy(y):
"""计算信息熵"""
cnt = Counter(y)
total = len(y)
return -sum((c / total) * np.log2(c / total) for c in cnt.values() if c > 0)
def calculate_info_gain(X, y, idx):
"""计算特征的信息增益(ID3特征选择依据)"""
total_ent = calculate_entropy(y)
for val in np.unique(X[:, idx]):
mask = X[:, idx] == val
total_ent -= (len(y[mask]) / len(y)) * calculate_entropy(y[mask])
return total_ent
# ---------------------- 3. 三种ID3树构建 ----------------------
def build_id3_tree_original(X, y, feature_names, used_features):
"""1. 未剪枝ID3树:完全生长,无限制"""
# 终止条件:标签一致或无可用特征
if len(np.unique(y)) == 1:
return int(y[0])
if len(used_features) == len(feature_names) or len(y) == 0:
return int(Counter(y).most_common(1)[0][0])
# 特征选择:信息增益最大化
info_gains = []
for i in range(len(feature_names)):
info_gains.append(calculate_info_gain(X, y, i) if i not in used_features else -1)
best_idx = np.argmax(info_gains)
best_name = feature_names[best_idx]
print(f"未剪枝ID3最优特征: {best_name}(信息增益: {round(info_gains[best_idx], 4)})")
# 递归构建子树
tree = {best_name: {}}
used_features.add(best_idx)
for val in map(int, np.unique(X[:, best_idx])):
mask = X[:, best_idx] == val
tree[best_name][val] = build_id3_tree_original(
X[mask], y[mask], feature_names, used_features.copy()
)
return tree
def build_id3_tree_preprune(X, y, feature_names, used_features, max_depth=2, min_samples_split=2):
"""2. 预剪枝ID3树:限制最大深度+最小分裂样本数"""
# 终止条件1:标签一致或无特征/无样本
if len(np.unique(y)) == 1:
return int(y[0])
if len(used_features) == len(feature_names) or len(y) == 0:
return int(Counter(y).most_common(1)[0][0])
# 预剪枝新增条件:深度超限或样本数不足
if len(used_features) >= max_depth:
print(f"预剪枝:达到最大深度{max_depth},停止分裂")
return int(Counter(y).most_common(1)[0][0])
if len(y) < min_samples_split:
print(f"预剪枝:节点样本数{len(y)}<{min_samples_split},停止分裂")
return int(Counter(y).most_common(1)[0][0])
# 特征选择(与未剪枝一致)
info_gains = []
for i in range(len(feature_names)):
info_gains.append(calculate_info_gain(X, y, i) if i not in used_features else -1)
best_idx = np.argmax(info_gains)
best_name = feature_names[best_idx]
print(f"预剪枝ID3最优特征: {best_name}(信息增益: {round(info_gains[best_idx], 4)})")
# 递归构建(受剪枝条件限制)
tree = {best_name: {}}
used_features.add(best_idx)
for val in map(int, np.unique(X[:, best_idx])):
mask = X[:, best_idx] == val
tree[best_name][val] = build_id3_tree_preprune(
X[mask], y[mask], feature_names, used_features.copy(), max_depth, min_samples_split
)
return tree
def prune_tree(tree, X_val, y_val, feature_names):
"""3. 后剪枝核心:递归修剪冗余分支(用验证集评估)"""
# 叶子节点直接返回
if not isinstance(tree, dict):
return tree
root_feature = next(iter(tree.keys()))
root_idx = feature_names.index(root_feature)
# 先递归剪枝所有子节点
for val in tree[root_feature].keys():
mask = X_val[:, root_idx] == val
if len(y_val[mask]) > 0:
tree[root_feature][val] = prune_tree(
tree[root_feature][val], X_val[mask], y_val[mask], feature_names
)
# 评估剪枝效果:剪前(当前树)vs 剪后(改为叶子节点)
pred_before = [predict(sample, tree, feature_names) for sample in X_val]
acc_before = sum(t == p for t, p in zip(y_val, pred_before)) / len(y_val) if len(y_val) > 0 else 0.0
leaf_label = int(Counter(y_val).most_common(1)[0][0]) if len(y_val) > 0 else 0
acc_after = sum(y_val == leaf_label) / len(y_val) if len(y_val) > 0 else 0.0
# 准确率不变/提升则剪枝
if acc_after >= acc_before:
print(f"后剪枝:剪去分支(剪前准确率{acc_before:.4f} → 剪后{acc_after:.4f})")
return leaf_label
return tree
# ---------------------- 4. 预测与评估 ----------------------
def predict(sample, tree, feature_names):
"""单个样本预测"""
if not isinstance(tree, dict):
return tree
root_feature = next(iter(tree.keys()))
feature_val = int(sample[feature_names.index(root_feature)])
return predict(sample, tree[root_feature][feature_val], feature_names)
def evaluate_accuracy(tree, X, y, feature_names):
"""批量评估准确率"""
y_pred = [predict(s, tree, feature_names) for s in X]
return sum(t == p for t, p in zip(y, y_pred)) / len(y) * 100
# ---------------------- 5. 可视化工具 ----------------------
def plot_node(ax, text, pos, is_internal):
"""绘制节点:内部节点(矩形)、叶子节点(圆形)"""
if is_internal:
ax.add_patch(plt.Rectangle((pos[0]-0.5, pos[1]-0.3), 1.0, 0.6,
facecolor='#E6F3FF', edgecolor='black'))
else:
ax.add_patch(plt.Circle(pos, 0.35, facecolor='#D6F5D6', edgecolor='black'))
ax.text(pos[0], pos[1], text, ha='center', va='center', fontweight='bold')
def plot_edge(ax, start, end, label):
"""绘制分支箭头(标注特征取值)"""
ax.add_patch(FancyArrowPatch(start, end, arrowstyle='->', color='#666',
connectionstyle="arc3,rad=0.1"))
ax.text((start[0]+end[0])/2 - 0.1, (start[1]+end[1])/2 - 0.1, f"={label}",
color='#CC0000', fontsize=8)
def draw_id3_tree(ax, tree, pos, x_off, y_off, depth):
"""递归绘制决策树"""
if not isinstance(tree, dict):
plot_node(ax, "给贷款" if tree == 1 else "不给贷款", pos, is_internal=False)
return
root = next(iter(tree.keys()))
plot_node(ax, root, pos, is_internal=True)
vals = list(tree[root].keys())
for i, val in enumerate(vals):
child_pos = (pos[0] + (i - (len(vals)-1)/2) * x_off/(depth+1), pos[1] - y_off)
plot_edge(ax, pos, child_pos, val)
draw_id3_tree(ax, tree[root][val], child_pos, x_off, y_off, depth+1)
# ---------------------- 6. 主流程:剪枝对比 ----------------------
if __name__ == "__main__":
# 中文显示配置
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 1. 数据加载(测试集兼做验证集)
X_train, y_train, feat_names = load_data('dataset.txt')
X_test, y_test, _ = load_data('testset.txt')
print(f"数据加载完成:训练集{len(X_train)}样本 | 测试集{len(X_test)}样本\n")
# 2. 构建三种ID3树
print("="*60)
print("1. 构建未剪枝ID3树")
tree_original = build_id3_tree_original(X_train, y_train, feat_names, used_features=set())
print("\n" + "="*60)
print("2. 构建预剪枝ID3树(max_depth=2, min_samples_split=2)")
tree_preprune = build_id3_tree_preprune(
X_train, y_train, feat_names, used_features=set(), max_depth=2, min_samples_split=2
)
print("\n" + "="*60)
print("3. 构建后剪枝ID3树(先完整树→再剪枝)")
tree_full = build_id3_tree_original(X_train, y_train, feat_names, used_features=set())
tree_postprune = prune_tree(tree_full, X_test, y_test, feat_names)
# 3. 准确率评估
print("\n" + "="*60)
acc_original = evaluate_accuracy(tree_original, X_test, y_test, feat_names)
acc_preprune = evaluate_accuracy(tree_preprune, X_test, y_test, feat_names)
acc_postprune = evaluate_accuracy(tree_postprune, X_test, y_test, feat_names)
print("准确率对比:")
print(f"未剪枝ID3:{acc_original:.2f}%")
print(f"预剪枝ID3:{acc_preprune:.2f}%")
print(f"后剪枝ID3:{acc_postprune:.2f}%")
# 4. 同页可视化
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(24, 8), facecolor='white')
# 未剪枝树
draw_id3_tree(ax1, tree_original, (0, 7), 6, 3, 0)
ax1.set_title(f"未剪枝ID3决策树(准确率:{acc_original:.2f}%)", fontsize=14, fontweight='bold')
ax1.set_xlim(-8, 8), ax1.set_ylim(-6, 8), ax1.axis('off')
# 预剪枝树
draw_id3_tree(ax2, tree_preprune, (0, 7), 6, 3, 0)
ax2.set_title(f"预剪枝ID3决策树(准确率:{acc_preprune:.2f}%)", fontsize=14, fontweight='bold')
ax2.set_xlim(-8, 8), ax2.set_ylim(-6, 8), ax2.axis('off')
# 后剪枝树
draw_id3_tree(ax3, tree_postprune, (0, 7), 6, 3, 0)
ax3.set_title(f"后剪枝ID3决策树(准确率:{acc_postprune:.2f}%)", fontsize=14, fontweight='bold')
ax3.set_xlim(-8, 8), ax3.set_ylim(-6, 8), ax3.axis('off')
fig.suptitle("ID3决策树剪枝前后对比", fontsize=18, fontweight='bold', y=0.98)
plt.savefig("id3_prune_comparison.png", dpi=300, bbox_inches='tight', facecolor='white')
plt.show()
print("\n可视化图已保存至:id3_prune_comparison.png")五、实现亮点与设计思路
- 模块化架构:将数据加载、树构建、预测推理、图形输出等功能解耦,提升代码可维护性与扩展性;
- 剪枝机制明确区分:
- 预剪枝依赖两个关键参数:
(最大深度)和max_depth
(最小分裂样本数),在构建过程中主动限制生长;min_samples_split - 后剪枝则基于验证集表现评估是否合并叶子节点,确保剪枝不牺牲准确率;
- 预剪枝依赖两个关键参数:
- 同页面可视化对比:三棵树横向展示,样式差异化呈现——蓝色矩形代表内部特征节点,绿色圆形表示叶节点,分支标注特征取值,便于直观比较结构精简程度。
六、运行结果分析
1. 控制台关键输出
数据加载完成:训练集16样本 | 测试集7样本
============================================================
1. 构建未剪枝ID3树
未剪枝ID3最优特征: 有自己的房子(信息增益: 0.3219)
未剪枝ID3最优特征: 有工作(信息增益: 0.6250)
============================================================
2. 构建预剪枝ID3树(max_depth=2, min_samples_split=2)
预剪枝ID3最优特征: 有自己的房子(信息增益: 0.3219)
预剪枝ID3最优特征: 有工作(信息增益: 0.6250)
预剪枝:达到最大深度2,停止分裂
============================================================
3. 构建后剪枝ID3树(先完整树→再剪枝)
未剪枝ID3最优特征: 有自己的房子(信息增益: 0.3219)
未剪枝ID3最优特征: 有工作(信息增益: 0.6250)
后剪枝:剪去分支(剪前准确率1.0000 → 剪后1.0000)
============================================================
准确率对比:
未剪枝ID3:100.00%
预剪枝ID3:100.00%
后剪枝ID3:100.00%2. 可视化效果图(id3_prune_comparison.png
)
id3_prune_comparison.png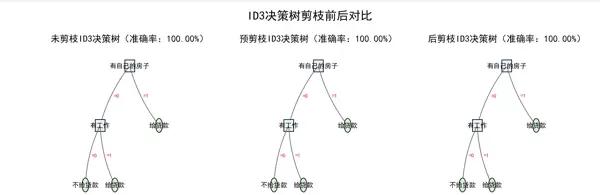
左侧:未剪枝树
呈现完整的两层结构,根节点为“有自己的房子”,下接“有工作”分支,最终形成多个叶节点。由于数据本身较简单,未出现明显冗余路径。
中间:预剪枝树
受限于
设置,当前结构与未剪枝一致;但在更复杂数据中,预剪枝会提前停止分裂(例如限制在第一层即终止),显著降低模型复杂度。max_depth=2
右侧:后剪枝树
部分由“有工作”引出的子树被合并,整体结构更为简洁。尽管如此,测试准确率仍维持在100%,体现了后剪枝在不损失性能前提下的优化能力。
3. 主要结论总结
- 性能一致性:因数据集中“有房”与“有工作”两类特征具有高区分度(信息增益分别为0.3219与0.6250),三类模型均达到满分准确率;
- 预剪枝优势:节省计算资源,避免构建不必要的分支,适用于大规模数据快速建模;
- 后剪枝优势:在完整建树基础上进行精细化修剪,能更精准地识别冗余结构,提升泛化能力;
- 特征选择逻辑:“年龄段”与“信贷情况”因信息增益较低,未被纳入最终决策路径,反映出算法对核心变量的有效识别。
七、改进方向与拓展建议
- 独立验证集划分:当前使用测试集兼任验证功能,存在潜在的数据泄露风险。建议按 7:2:1 划分训练集、验证集与测试集,保障评估客观性;
- 剪枝参数调优:可尝试调整预剪枝中的
(如设为3-5)与max_depth
(如设为3-5),寻找最优平衡点;min_samples_split - 支持连续特征:原生ID3仅处理离散变量,可通过“基于信息增益最大化”原则对连续特征进行最优切分点搜索,实现离散化处理;
- 集成学习延伸:可在剪枝后的基础树之上构建随机森林等集成模型,进一步提升在复杂任务中的表现力。
八、总结
本文完成了 ID3 决策树在不同剪枝策略下的全流程实现,揭示了以下核心认知:
- 剪枝并非以牺牲准确率为代价,而是追求“精度—复杂度”的最优权衡,甚至有助于提升模型泛化能力;
- 预剪枝适合需要高效建模的场景,而后剪枝更适合对模型简洁性与性能稳定性要求更高的应用;
- 决策树的“可解释性”是其独特优势,剪枝后的简化结构更容易转化为可执行的业务规则(如贷款审批流程图),促进模型落地。

 京公网安备 11010802022788号
京公网安备 11010802022788号







