


 雷达卡
雷达卡



实验一:开发平台搭建与环境配置
课程名称:数据挖掘(Data Mining)
操作系统:Windows 11
1. 实验目标
- 掌握在 Windows 系统中部署和配置 Python 开发环境的基本流程。
- 熟悉 Anaconda 的安装过程、环境管理机制及其常用命令操作。
- 能够独立创建指定版本的 Python 虚拟环境(本实验要求建立名为
DM的 Python 3.7 环境)。 - 熟练完成主流开发工具如 PyCharm 和 Jupyter Notebook 的安装与集成。
- 成功安装深度学习框架 PyTorch 2.2.2 及一系列常用第三方库,包括:
numpy、pandas、tensorflow、h5py、mygene、matplotlib、seaborn、umap-learn。 - 理解并掌握
pip与conda两种包管理工具的使用场景与基本指令。
2. 实验运行环境
- 操作系统:Windows 11
- Anaconda(Python 发行版)
- PyCharm(Community 或 Professional 版本)
- Jupyter Notebook
- Python 3.7(后续调整为 3.10)
- PyTorch 2.2.2(支持 CPU 或 GPU 运行)
3. 实验步骤与实施过程
3.1 Anaconda 安装流程
从 Anaconda 官方网站下载适用于 Windows 平台的安装程序。双击执行安装文件,并按照默认向导进行安装。建议勾选“Add Anaconda to my PATH”选项以方便命令行调用(非强制)。推荐使用 Anaconda Prompt 来统一管理虚拟环境。
安装完成后,启动 Anaconda Prompt 验证安装状态。
conda --version
由于系统此前已存在旧版本 Anaconda,因此当前显示为较早版本信息。
3.2 创建独立 Python 环境 DM(基于 Python 3.7)
打开 Anaconda Prompt,输入以下命令创建指定环境:
conda create -n DM python=3.7 -y随后激活该环境:
conda activate DM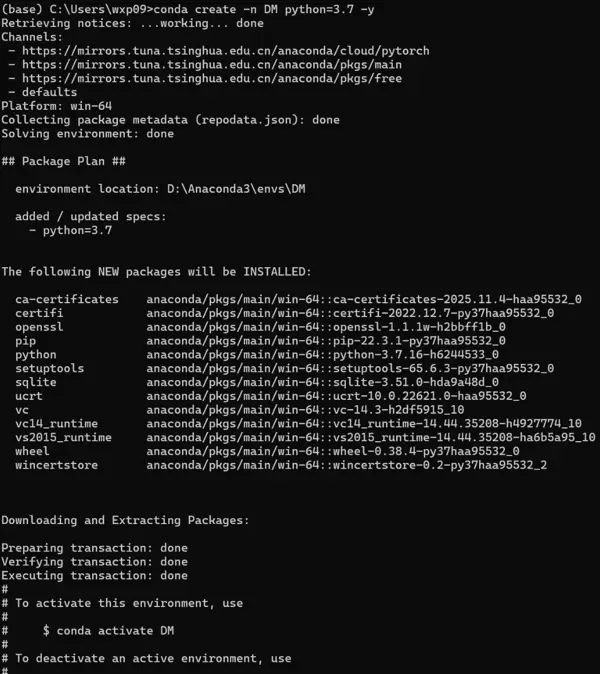

通过如下命令查看所有已创建的 conda 环境列表:
conda env list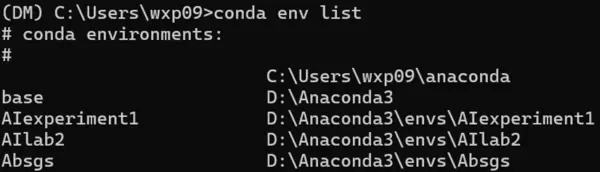
结果显示环境中已包含名为 DM 的条目,表明虚拟环境创建成功。
3.3 安装与启动 Jupyter Notebook
Jupyter Notebook 已包含于 Anaconda 默认组件中。若缺失或需重装,可使用以下命令:
conda install jupyter -y安装完毕后,运行:
jupyter notebookjupyter notebook浏览器将自动打开本地 Jupyter 服务页面,若能正常访问则表示安装成功。
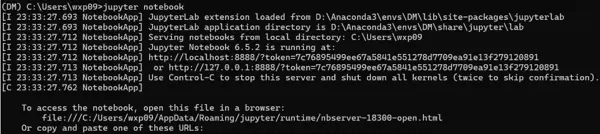
3.4 PyCharm 的安装与解释器配置
前往 JetBrains 官网下载并安装 PyCharm 开发工具。安装完成后,进入软件界面:
File → Settings → Project → Python Interpreter
点击添加解释器(Add Interpreter),选择 Conda Environment → Existing Environment,然后指定 DM 环境对应的 Python 解释器路径。
<Anaconda路径>\Scripts\conda.exe确认设置后,项目即使用 DM 环境中的 Python 解释器。

3.5 在 DM 环境中安装 PyTorch 2.2.2
尝试安装支持 GPU(CUDA)的 PyTorch 版本(例如 CUDA 11.8):
conda install pytorch==2.2.2 torchvision torchaudio cudatoolkit=11.8 -c pytorch -y安装完成后执行验证命令:
python -c "import torch; print(torch.__version__, torch.cuda.is_available())"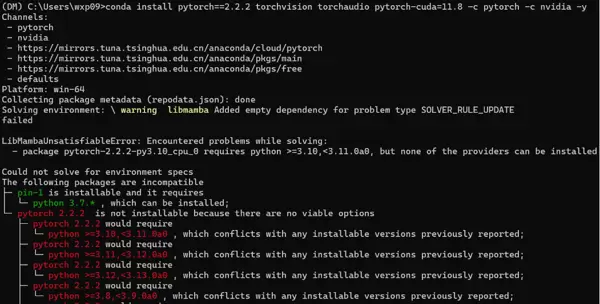
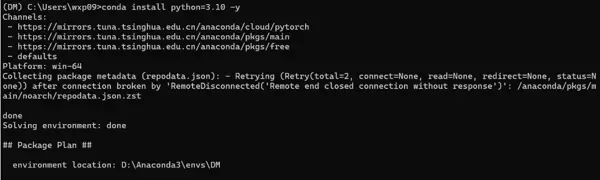

但在实际安装过程中发现,PyTorch 2.2.2 要求 Python 版本不低于 3.10,与原定使用的 Python 3.7 存在兼容性冲突。因此,最终决定将 DM 环境升级至 Python 3.10 以满足依赖要求。
3.6 第三方数据科学库的安装
首先激活 DM 环境,然后批量安装常用科学计算库:
conda activate DM
conda install numpy pandas matplotlib seaborn scikit-learn scipy -y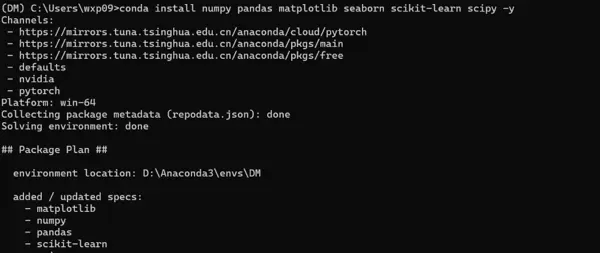
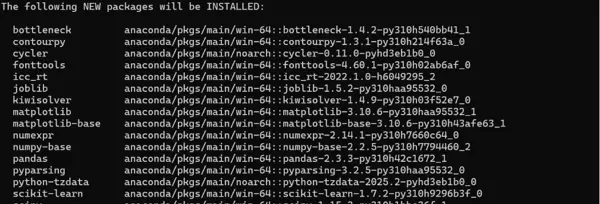
对于 umap-learn 库,采用 conda-forge 渠道进行安装:
conda install -c conda-forge umap-learn -y
其余部分库通过 pip 安装:
pip install h5py mygene
3.7 包管理工具命令汇总
conda 常用命令总结:
conda create -n envname python=3.X # 创建环境
conda activate envname # 激活环境
conda deactivate # 退出环境
conda install package # 安装包
conda list # 查看已安装包
conda remove -n envname --all # 删除环境pip 常用命令一览:
pip install package # 安装包
pip uninstall package # 卸载包
pip list # 查看已安装包
pip install -U package # 更新包4. 实验总结与体会
本次实验完成了数据挖掘所需基础开发环境的全面搭建。通过对 Anaconda、Jupyter Notebook、PyCharm 等工具的安装与配置,掌握了 Python 多环境管理的核心方法。特别是在创建独立项目环境 DM 的过程中,深入理解了 conda 在环境隔离与依赖管理方面的优势。
在安装 PyTorch 时遇到的版本兼容问题,提醒我们在构建环境前应充分查阅各组件之间的依赖关系。最终通过将 Python 升级至 3.10 成功解决了冲突,确保了框架的正常运行。
此外,结合 conda 与 pip 完成了多个关键数据处理与可视化库的安装,进一步熟悉了两种包管理方式的应用场景与协作模式。整体上,本次实践为后续的数据分析与模型训练打下了坚实的环境基础。
本次实验让我完整地实践了在 Windows 系统上构建 Python 数据挖掘开发环境的各个步骤。整个过程涵盖了 Anaconda 的安装与配置、虚拟环境的创建与管理,以及 Jupyter Notebook 和 PyCharm 两款主流开发工具的基本使用。同时,我还完成了包括 PyTorch 在内的多个核心库的安装与测试。
通过实际操作,我更加明确了虚拟环境在项目开发中的关键作用。它能够有效隔离不同项目的依赖包,防止版本冲突,从而保障各实验环境的独立性与稳定性。此外,在手动安装 NumPy、Pandas、Matplotlib 等常用科学计算库的过程中,我对 conda 与 pip 两种包管理工具的适用场景有了更深入的理解,也掌握了根据具体需求选择更优安装方式的能力。
在配置 PyTorch 时,我特别关注了 CPU 与 GPU 版本的区别,并学习了如何根据系统显卡驱动和 CUDA 版本选择合适的安装命令。这一过程使我意识到 CUDA 兼容性对于深度学习模型训练效率的重要影响,也为今后开展基于 GPU 加速的实验打下了基础。
总体来看,此次实验不仅提升了我在本地搭建和维护 Python 数据分析环境的技术能力,还帮助我建立起对数据挖掘工具链的整体认知。从环境管理到开发工具,再到核心框架的部署,每一个环节都为后续的数据建模、算法训练与结果分析提供了可靠的运行支撑。

 京公网安备 11010802022788号
京公网安备 11010802022788号







