


 雷达卡
雷达卡



生成式 AI 正在经历一场静悄悄的形态革命。Google Research 团队最新发布的生成式 UI(Generative UI)研究,揭示了一种全新的交互范式——AI 不再只是信息的传递者,而是直接成为应用的创造者。
这并非简单的界面美化或格式升级,而是一次交互逻辑的根本性重构。过去,用户向 AI 提问,得到的是文本回复;如今,同样的需求会被转化为一个量身定制、具备动态交互能力的应用程序。这一转变彻底打破了长期以来以 Markdown 文本为核心的对话模式。

Google Research 团队通过实验证明,现代大语言模型在配备合适的工具链与系统指令后,已能从单一的内容生成角色,进化为一支完整的虚拟全栈开发团队。面对任意用户请求,系统可在约一分钟内实时构建出包含富媒体内容、地图服务、音频组件甚至小游戏的完整网页应用。
这种能力的背后,是精密的技术架构与先进模型能力的协同涌现。传统 AI 交互依赖于静态的 Markdown 输出,形式虽优于纯文本,但仍如同一份无法操作的打印文档。而生成式 UI 的目标,正是让 AI 能“动手做”而不仅仅是“动口说”。
研究人员提出的核心问题是:如果 AI 不再把答案写在纸上,而是直接做成一个可点击、可滑动、能实时反馈的应用,用户体验将发生怎样的质变?实验结果表明,这种变化是颠覆性的。
该系统的实现依托于三个关键模块的紧密协作:服务器端工具集、深度编排的系统指令,以及严格的后处理机制。
其中,服务器端提供了多个 API 接口,赋予模型“手”和“眼”的能力。图像生成与搜索工具尤为关键。搜索不仅用于获取信息,更承担着确保内容真实性的职责——当涉及现实世界实体时,系统强制要求模型通过 Google Search 验证数据,从而保证界面上展示的每一个数字、每一段描述都准确无误。
图像生成工具则根据上下文自动生成主题匹配的视觉素材,或调用外部真实图片资源。这些资产既可用于优化后续生成过程,也可直接推送至浏览器渲染,极大提升了响应效率。
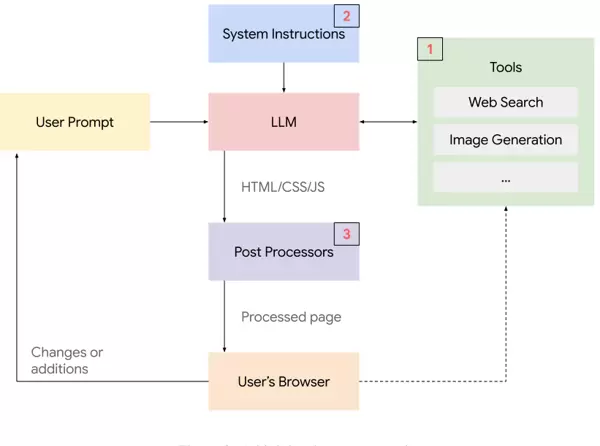
然而,整个系统真正的核心在于那份长达 3000 词的系统指令。它不是普通 Prompt,而是一份详尽的“AI 员工手册”,确立了“优先构建交互式应用”的设计哲学。
手册中明确规定:禁止返回纯文本输出。例如,当用户询问“特拉维夫现在几点”,模型不能仅回答时间,而必须生成一个动态运行的时钟应用;若提问“如何做仰卧起坐”,则需提供带有倒计时和动作图解的健身辅助工具。
为保障输出质量,系统强制执行七步思维链(Chain of Thought)流程:
- 解析用户意图
- 判断是否需要强制搜索
- 构思应用概念与交互逻辑
- 规划内容结构与叙事线索
- 识别所需数据与图像资源,制定搜索策略
- 执行内部搜索并获取事实依据
- 头脑风暴可用 UI 组件,并最终整合过滤功能特性
这一机制有效抑制了模型幻觉,确保最终产物不仅是外观精美,更是逻辑清晰、数据可靠的实用软件。
系统还实行严格的“零占位符政策”:严禁使用 Lorem Ipsum 等虚假填充文本,也不允许出现不可点击的“假按钮”。若某项功能缺乏真实数据支持,相关元素必须被移除,而非以虚构内容蒙混过关。这倒逼模型在初期就必须确认数据可得性,推动其进行更精准的规划与检索。
在技术规范方面,系统要求输出纯净的 HTML 代码,样式采用 Tailwind CSS 实现,交互逻辑完全由原生 JavaScript 控制。通过微调系统指令中的风格描述,模型能够自适应地生成不同视觉风格的界面——无论是现代简约风,还是充满奇幻感的巫师绿主题,均可实现图像、图标、配色与布局的整体统一。
最后,后处理模块作为系统的质检环节,负责对模型输出进行最终校验。尽管当前模型能力已十分强大,但仍可能存在细微错误。后处理系统会自动检测语法问题、结构异常或潜在安全隐患,确保交付给用户的界面既美观又稳定可靠。
后处理组件在系统中扮演着关键角色,负责注入真实的 API 密钥(例如 Google Maps 的 Key),检测客户端运行时的错误,并修复因模型解析不准确而引发的语法问题。同时,它确保所有 HTML 属性都被正确转义,有效防范潜在的安全风险。
正是这“最后一公里”的精细化处理,保障了最终交付给用户的成果是一个功能完整、无运行报错、可直接使用的应用成品。
生成式 UI 的跨领域构建能力
为验证该系统的实际表现,Google Research 团队展示了多个真实生成案例。这些案例并非经过筛选的理想化样本,而是反映了系统在应对复杂、抽象乃至教育类需求时的真实水平。
以数学可视化为例:
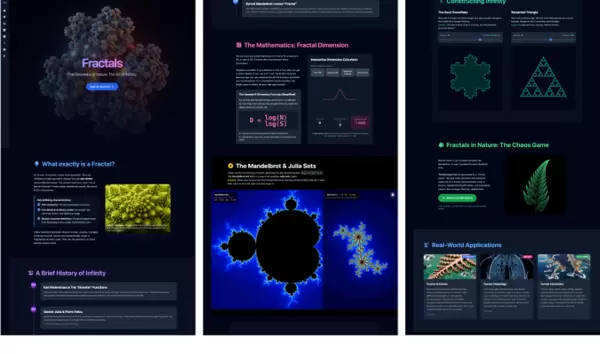
当用户输入“详细解释分形,我想深入了解所有细节”时,系统并未返回一篇冗长的学术文章,而是生成了一个名为“分形探索者”(Fractal Explorer)的沉浸式网页。这个页面不仅展示图像,更像一个动态的数学实验平台。
其中集成了维度计算器,直观呈现豪斯多夫维数的计算过程;设计了双画布浏览器——当鼠标在曼德博集合上移动时,另一侧实时渲染出对应的朱利亚集合。这要求模型不仅要理解分形理论,还需具备编写复杂 JavaScript 算法的能力,以支持几何图形的实时演算。
此外,页面还包含多个交互元素:通过滑块逐步迭代生成科赫雪花与谢尔宾斯三角形,并内置混沌游戏模拟器,利用随机机制“生长”出巴恩斯利蕨类图案。这种将抽象数学概念转化为可操作、可探索代码逻辑的能力,已远超传统图文内容生成的范畴。
另一个引人注目的案例是关于计时设备发展史的呈现:
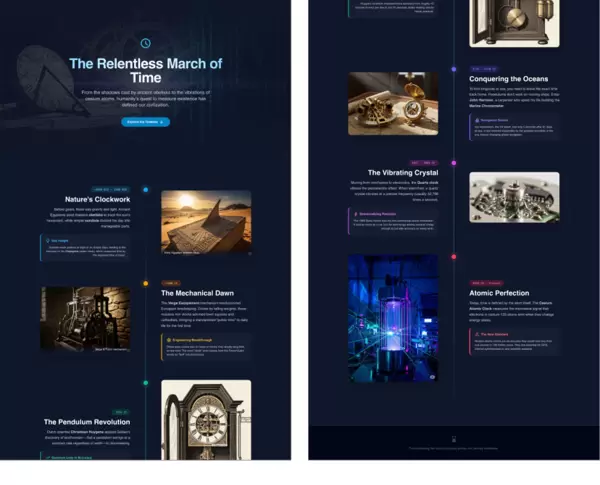
面对简单的查询“计时器的历史”,系统生成了一个名为 Chronos 的暗色主题网页。它没有采用平铺直叙的时间线罗列方式,而是构建了一条垂直滚动动画驱动的时间轴。
从古埃及的方尖碑和水钟,到惠更斯发明摆钟的重大突破,再到现代原子钟的极致精密,每个历史节点都配有符合时代氛围的生成图像。系统还能智能提取关键技术革新点,并以信息框形式突出展示。
整体布局采用响应式网格结构,文本与图像交错排列,配合滚动过程中的淡入淡出动画,营造出类似博物馆导览的叙事体验。这表明模型不仅掌握知识,更展现出策展级别的审美判断与故事构建能力。
生成式 UI 在教育场景中的创新应用
教育是生成式 UI 发挥优势的重要领域之一。以下案例充分体现了其个性化定制潜力:
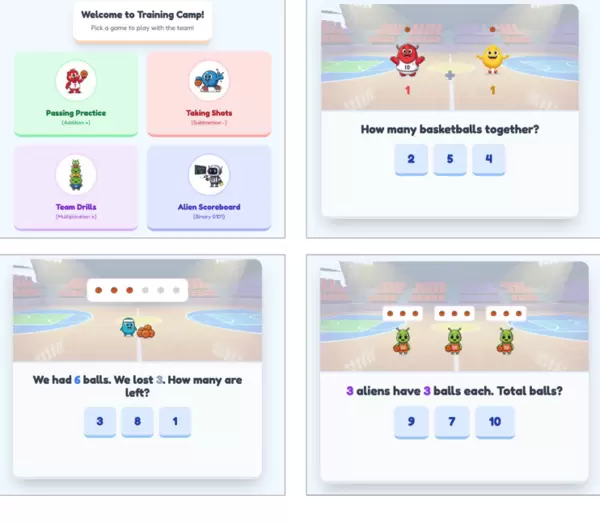
针对“用打篮球的可爱生物教我 5 岁儿子加减乘除和二进制”这一具体且富有童趣的需求,系统构建出“小球手数学学院”(Little Ballers Math Academy)这一完全可交互的应用。
该应用包含四种游戏模式:加法对应传球练习,减法模拟投篮动作,乘法体现为团队协作训练,而二进制则通过一个外星风格的记分牌进行教学。在二进制模块中,系统设置了可点击的开关来表示 0 和 1,并结合实时计分与五彩纸屑特效,给予儿童即时正向反馈。
所有视觉元素——包括篮球、卡通怪物、机器人角色等——均根据原始提示实时生成。这种基于特定用户画像(如年幼儿童)和兴趣偏好(如篮球)快速构建互动教育工具的能力,展现了生成式 UI 在个性化学习路径设计方面的巨大前景。
人机协同评估:客观衡量 AI 当前能力
为了科学评估生成式 UI 的质量,研究团队引入了量化指标,而非依赖主观感受。
由于缺乏现成的高质量对比数据集,团队创建了 PAGEN 数据集——一组由人类专家手工打造的高水准网页集合。他们在 Upwork 平台上招募资深 Web 开发者,针对随机抽取的查询任务,花费平均 3–5 小时制作具备高度交互性的单页应用,确保作品达到专业标准。
PAGEN 的建立为性能评估提供了可靠的基准参照。研究采用成对偏好测试方法,让评分人员在忽略生成速度的前提下,对比生成式 UI 与人类专家作品、Google 搜索首条结果、纯文本输出以及 Markdown 格式内容的表现。
测试结果具有重要启示意义:
在 LMArena 数据集上的评测显示,生成式 UI 的 Elo 得分为 1710.7,虽略低于人类专家的 1756.0,但差距极小。更重要的是,它显著优于标准 Markdown 输出(1459.6)和常规搜索结果网页(1355.1)。
在直接对比中,生成式 UI 对 Markdown 的胜率达到 82.8%,对纯文本更是高达 97.0%。这意味着大多数用户在体验过后,会明确倾向于选择交互式应用而非传统对话界面。
尤为值得注意的是与人类专家的比较:尽管整体仍稍逊一筹,但在 44% 的测试案例中,生成式 UI 被评价为优于或等同于人类开发者的作品。这一数字意味着,在近一半的情境下,AI 在一分钟内生成的应用已能达到专业开发者数小时工作的效果。
在信息寻求类(Info-Seeking)任务中,生成式 UI 的表现尤为突出,其优势更加明显,胜率显著提升。
研究进一步揭示了一个关键发现:生成式 UI 实质上是一种涌现能力(Emergent Capability)。这种能力并非所有模型都能具备,而是与模型的智力水平密切相关。只有当模型达到一定复杂度和推理深度时,才能真正展现出这一特性。
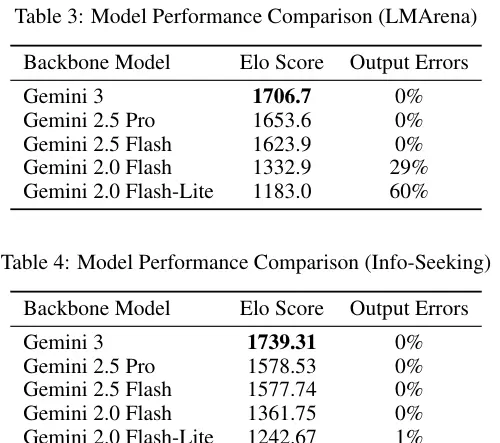
数据对比清晰地反映了这一点。使用 Gemini 2.0 Flash 模型时,生成结果的 Elo 分数仅为 1332.9,并伴随高达 29% 的输出错误率,包括 HTML 标签未闭合、JS 语法错误等结构性问题。
而当升级至更先进的 Gemini 3 模型后,Elo 分数跃升至 1706.7,致命性输出错误率则完全降至 0%。这表明,构建架构完整且复杂的用户界面、编写逻辑严密无误的代码、准确遵循多层级系统指令,是只有 SOTA(State-of-the-Art)级别模型才可胜任的任务。
模型的推理能力越强,其所生成的 UI 在稳定性与智能化方面表现就越出色。同时,提示工程(Prompt Engineering)的精细程度也起着决定性作用。
通过消融实验可以观察到,尽管极简的 Prompt 能让模型产出基本可用的界面,但若引入核心设计哲学、详细的思维链引导以及丰富的示例支持,最终输出的用户满意度将大幅提升。
这一现象再次验证了在 AI 交互过程中,“怎么问”与“问谁”具有同等重要性。
然而,尽管前景广阔,生成式 UI 当前仍面临三大现实挑战:生成延迟、错误控制与算力成本。
首先是响应速度的问题。目前,生成一个包含完整逻辑、样式资源及交互功能的网页通常需要一到两分钟时间。在用户早已习惯毫秒级响应的互联网环境中,这样的等待显得尤为漫长。
虽然流式传输(Streaming)技术允许页面在渲染过程中即开放部分交互功能,从而在感知上将延迟缩短约一半,但这仍不足以满足实时应用的需求。未来,推测性解码(Speculative Decoding)等前沿方法可能有助于缓解该问题,但在现阶段,延迟仍是制约大规模落地的主要瓶颈之一。
其次,尽管如 Gemini 3 已实现 0% 的致命结构错误,但在处理复杂业务逻辑时,JavaScript 运行时异常或特定分辨率下 CSS 样式错乱等问题仍偶有发生。
当前系统依赖后处理模块进行修复,但要达到商业级软件所要求的高稳健性,模型自身对代码逻辑的理解深度及其自我纠错能力仍有待加强。
最后是算力消耗带来的成本压力。相较于生成普通文本,生成式 UI 需要输出数百行高质量代码,并频繁调用图像生成、网络搜索等外部 API,导致推理资源消耗成倍增长。
这种高负载在商业化部署中会直接转化为高昂的运营成本,成为推广过程中的重要考量因素。
尽管存在上述挑战,整体趋势依然令人振奋。Google 的这项研究为我们描绘了一个正在到来的新时代图景:软件不再是以固定形态发布的静态产品,而是一种根据需求即时生成的动态服务。
设想一下,当你计划一次复杂的家庭旅行时,无需在地图、票务平台和攻略网站之间反复切换,只需向 AI 表达你的需求,它便能在 60 秒内为你定制一个集成交互式地图、动态行程安排、实时天气预警和预订入口于一体的专属应用。
又或者,当你试图理解量子力学时,不再局限于阅读抽象的教科书,而是获得一个可手动调节参数、直观观察波函数坍缩过程的可视化模拟器。
生成式 UI 正在将大语言模型的角色从“知识查询员”转变为“随叫随到的开发工程师”。它不只是回答问题,更是主动解决问题。
在这个新范式下,用户不再是被动的内容接收者,而是拥有了一个随时响应需求的虚拟开发团队。
PAGEN 数据集的开源,为全球研究者提供了一个开放的基准平台,激励更多团队参与竞争,推动技术不断逼近甚至超越人类专家水平。
我们正处在一个全新的人机交互时代的门槛之上。屏幕背后的智能体,终于学会了用最自然的方式——界面与交互——来回应我们的意图。

 京公网安备 11010802022788号
京公网安备 11010802022788号







