


 雷达卡
雷达卡



深入理解计算机视觉的三大核心任务:分类、检测与分割
作为深度学习中最具代表性的应用方向之一,计算机视觉技术近年来发展迅速。初学者在进入该领域时,应首先掌握三项基础性任务——图像分类、目标检测和图像分割。这些任务不仅是各类高级视觉系统的基石,也为后续研究提供了必要的理论与实践支持。
1. 图像分类(Image Classification)
核心目标:为输入图像分配一个或多个语义标签,从而识别其主要内容。
- 单标签分类:每张图像仅归属于一个特定类别,如“猫”或“汽车”。
- 多标签分类:允许一张图像同时属于多个类别,例如一张图片可能同时包含“狗”、“草地”和“户外”等标签。
典型应用场景:谷歌相册中的智能搜索功能即采用了涵盖超过20,000个类别的多标签分类模型,用户可通过关键词快速检索照片内容。
2. 目标检测(Object Detection)
核心目标:在图像中标注出感兴趣对象的位置,并给出每个对象的类别信息。通常通过绘制边界框(Bounding Box)来实现定位。
实际用途举例:自动驾驶系统利用目标检测技术识别道路上的车辆、行人以及交通标志,以保障行驶安全。
3. 图像分割(Image Segmentation)
核心目标:将图像划分为若干区域,每个区域对应不同的语义类别或独立实例。
根据任务粒度的不同,图像分割可分为以下两种类型:
- 语义分割:对每一个像素进行分类,标记其所属的语义类别(如“天空”、“道路”),但不区分同一类中的不同个体。
- 实例分割:不仅完成像素级别的分类,还能区分同类中的不同对象个体,例如区分画面中的三只猫各自的身体范围。
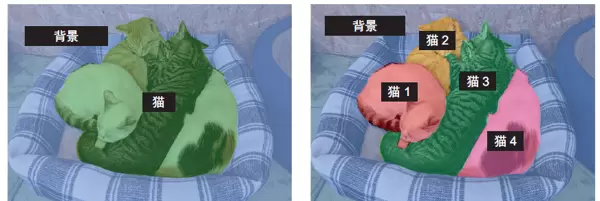
常见应用领域:视频会议中的虚拟背景替换、医学影像分析、无人驾驶中的道路区域识别等都依赖于高精度的图像分割技术。
实战案例:基于深度学习的宠物图像语义分割
接下来我们通过一个具体项目,了解如何使用神经网络实现语义分割功能。
数据集说明与准备
本例采用 Oxford-IIIT 宠物数据集,共包含 7,390 张猫狗图像及其对应的分割掩码文件。以下是路径配置代码:
import os
input_dir = "images/"
target_dir = "annotations/trimaps/"
input_img_paths = sorted([
os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")
])
target_paths = sorted([
os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")
])
分割掩码解析
在语义分割任务中,标签以“分割掩码”形式存在,它是一幅与原图尺寸相同的单通道图像,像素值含义如下:
- 1:表示前景对象(如宠物主体)
- 2:表示背景区域
- 3:表示轮廓边缘部分
模型结构设计
典型的图像分割模型采用编码器-解码器架构,先提取高层特征再逐步恢复空间分辨率。以下是一个简化的实现示例:
from tensorflow import keras
from tensorflow.keras import layers
def get_model(img_size, num_classes):
# 编码器部分(下采样)
inputs = keras.Input(shape=img_size + (3,))
x = layers.Conv2D(32, 3, strides=2, activation="relu", padding="same")(inputs)
x = layers.Conv2D(64, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, strides=2, activation="relu", padding="same")(x)
# 解码器部分(上采样)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", padding="same")(x)
# 输出层
outputs = layers.Conv2D(num_classes, 3, activation="softmax", padding="same")(x)
return keras.Model(inputs, outputs)
model = get_model(img_size=(200, 200), num_classes=3)
关键设计思想
- 使用步幅卷积代替最大池化:有助于保留更多位置信息,这对像素级预测至关重要。
- 编码器-解码器框架:编码器压缩图像并提取抽象特征;解码器则通过上采样逐步还原细节与分辨率。
- 转置卷积层(Conv2DTranspose):用于学习可训练的上采样过程,使输出能够匹配原始图像的空间维度。
模型训练与评估流程
配置优化器与损失函数后即可开始训练:
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.keras",
save_best_only=True)
]
import os
import numpy as np
import matplotlib
matplotlib.use('Agg') # 使用非交互式后端
import matplotlib.pyplot as plt
import sys
# 设置TensorFlow日志级别
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
print("开始执行图像分割程序...")
# 检查数据目录
print("检查数据目录...")
current_dir = os.getcwd()
print(f"当前工作目录: {current_dir}")
# 确定脚本所在路径及项目根目录,提升路径解析可靠性
script_dir = os.path.dirname(os.path.abspath(__file__))
project_root = os.path.dirname(script_dir)
print(f"脚本目录: {script_dir}")
print(f"项目根目录: {project_root}")
# 构建输入与目标数据的路径
input_dir = os.path.join(project_root, "images")
target_dir = os.path.join(project_root, "annotations", "trimaps")
print(f"输入图像目录: {input_dir}")
print(f"目标掩码目录: {target_dir}")
# 验证关键目录是否存在
if not os.path.exists(input_dir):
print(f"错误: 输入目录 {input_dir} 不存在")
print("请确保已下载并解压 Oxford-IIIT Pet Dataset 数据集")
print("数据集下载命令:")
print("wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz")
print("wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz")
print("tar -xf images.tar.gz")
print("tar -xf annotations.tar.gz")
sys.exit(1)
if not os.path.exists(target_dir):
print(f"错误: 目标目录 {target_dir} 不存在")
sys.exit(1)
# 扫描并排序图像和标注文件
try:
input_img_paths = sorted([
os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")
])
target_paths = sorted([
os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")
])
print(f"找到 {len(input_img_paths)} 张输入图像")
print(f"找到 {len(target_paths)} 个目标掩码")
if len(input_img_paths) == 0 or len(target_paths) == 0:
print("错误: 没有找到图像文件")
sys.exit(1)
except Exception as e:
print(f"获取文件列表时出错: {e}")
sys.exit(1)
结果展示
模型训练结束后,具备了精准识别前景(宠物)与背景的能力:

任务对比总结
- 图像分类:判断图像整体内容,回答“这是什么?”
- 图像分割:实现像素级别的分类,解决“每个像素属于哪个类别?”的问题。
- 目标检测:同时完成物体定位与识别,明确“物体在什么位置?它是什么?”
掌握上述三项核心视觉任务,意味着你已经拥有了应对大多数计算机视觉挑战的基础能力。其中,图像分割技术在医学影像分析、自动驾驶感知系统以及智能图像编辑等场景中具有广泛应用,是现代计算机视觉工程师必须掌握的关键技能之一。
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.keras",
save_best_only=True)
]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks,
validation_data=(val_input_imgs, val_targets))
为降低内存消耗,对处理的图像数量进行限制:
max_samples = min(500, len(input_img_paths))
input_img_paths = input_img_paths[:max_samples]
target_paths = target_paths[:max_samples]
print(f"限制处理图像数量为 {max_samples} 张以减少内存使用")跳过图像可视化步骤,直接进入数据预处理流程:
print("跳过图像显示,直接进入数据处理...")为避免潜在的模块冲突,延迟导入 TensorFlow 相关组件:
try:
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.utils import load_img
print("TensorFlow模块导入成功")
except ImportError as e:
print(f"导入TensorFlow模块时出错: {e}")
sys.exit(1)定义一个简化的图像加载函数,用于高效读取输入图像与对应标签掩码:
def load_images_simple(input_img_paths, target_paths, size=(128, 128)):
print(f"开始加载 {len(input_img_paths)} 张图像...")
input_imgs = []
targets = []
for i in range(len(input_img_paths)):
if i % 50 == 0:
print(f"已加载 {i}/{len(input_img_paths)} 张图像")
try:
# 加载并归一化输入图像
img = load_img(input_img_paths[i], target_size=size)
img_array = np.array(img, dtype="float32") / 255.0
# 加载目标分割掩码(灰度模式)
mask = load_img(target_paths[i], target_size=size, color_mode="grayscale")
mask_array = np.array(mask, dtype="uint8")
# 调整标签值至正确范围
# Oxford-IIIT Pet 数据集中原始标签为 1, 2, 3,需转换为 0, 1, 2
mask_array = mask_array - 1
mask_array[mask_array == 255] = 2 # 将边界像素归为类别2
mask_array = np.expand_dims(mask_array, 2)
input_imgs.append(img_array)
targets.append(mask_array)
except Exception as e:
print(f"跳过图像 {input_img_paths[i]}: {e}")
continue
print(f"成功加载 {len(input_imgs)} 张图像")
return np.array(input_imgs), np.array(targets)调用简化函数加载全部可用图像数据:
try:
input_imgs, targets = load_images_simple(input_img_paths, target_paths, size=(128, 128))
if len(input_imgs) == 0:
print("错误: 没有成功加载任何图像")
sys.exit(1)
except Exception as e:
print(f"加载图像时出错: {e}")
sys.exit(1)将数据划分为训练集和验证集,确保验证样本数合理且不超过总量的五分之一:
num_val_samples = min(100, len(input_imgs) // 5)
train_input_imgs = input_imgs[:-num_val_samples]
train_targets = targets[:-num_val_samples]
val_input_imgs = input_imgs[-num_val_samples:]
val_targets = targets[-num_val_samples:]
print(f"训练集大小: {len(train_input_imgs)}")
print(f"验证集大小: {len(val_input_imgs)}")构建轻量级语义分割模型结构:
def get_simple_model(img_size, num_classes):
print("正在构建简化模型...")
# 定义输入层
inputs = keras.Input(shape=img_size + (3,))
# 构建编码器部分
x = layers.Conv2D(64, 3, activation='relu', padding='same')(inputs)
x = layers.MaxPooling2D(2)(x)
x = layers.Conv2D(32, 3, activation='relu', padding='same')(x)
x = layers.MaxPooling2D(2)(x)
# 构建解码器部分
x = layers.Conv2DTranspose(32, 3, activation='relu', padding='same')(x)
x = layers.UpSampling2D(2)(x)
x = layers.Conv2DTranspose(64, 3, activation='relu', padding='same')(x)
x = layers.UpSampling2D(2)(x)
# 添加输出层
outputs = layers.Conv2D(num_classes, 1, activation='softmax')(x)
model = keras.Model(inputs, outputs)
print("简化模型构建完成")
return model
# 初始化简化模型
model = get_simple_model(img_size=(128, 128), num_classes=3)
model.summary()
# 模型编译配置
print("正在编译模型...")
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=['accuracy']
)
# 数据类型转换确保一致性
train_targets = train_targets.astype(np.int32)
val_targets = val_targets.astype(np.int32)
# 设定训练回调机制
callbacks = [
keras.callbacks.EarlyStopping(patience=3),
keras.callbacks.ModelCheckpoint(
"simple_oxford_segmentation.keras",
save_best_only=True
)
]
# 开始模型训练流程
print("开始训练模型...")
try:
history = model.fit(
train_input_imgs, train_targets,
epochs=5,
batch_size=8,
callbacks=callbacks,
validation_data=(val_input_imgs, val_targets),
verbose=1
)
print("模型训练完成")
# 可视化训练过程中的损失变化
if len(history.history["loss"]) > 0:
epochs = range(1, len(history.history["loss"]) + 1)
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.figure()
plt.plot(epochs, loss, "bo-", label="Training loss")
plt.plot(epochs, val_loss, "ro-", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.savefig('simple_training_loss.png', dpi=150, bbox_inches='tight')
plt.close()
print("训练损失图表已保存为 simple_training_loss.png")
# 执行模型预测阶段
print("进行预测...")
if os.path.exists("simple_oxford_segmentation.keras"):
model = keras.models.load_model("simple_oxford_segmentation.keras")
# 使用验证集中指定样本进行测试
test_idx = min(5, len(val_input_imgs) - 1)
test_image = val_input_imgs[test_idx]
mask_pred = model.predict(np.expand_dims(test_image, 0), verbose=0)[0]
predicted_mask = np.argmax(mask_pred, axis=-1)
# 构建可视化结果图
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# 显示原始测试图像
axes[0].imshow(test_image)
axes[0].set_title("Test Image")
axes[0].axis('off')
# 展示模型生成的预测掩码
axes[1].imshow(predicted_mask, cmap='viridis')
axes[1].set_title("Predicted Mask")
axes[1].axis('off')
# 对比真实标签掩码(Ground Truth)
axes[2].imshow(val_targets[test_idx][:, :, 0], cmap='viridis')
axes[2].set_title("Ground Truth")
axes[2].axis('off')
plt.tight_layout()
plt.savefig('simple_prediction_result.png', dpi=150, bbox_inches='tight')
plt.close()
print("预测结果图表已保存为 simple_prediction_result.png")
print("程序执行成功完成!")
except Exception as e:
print(f"训练过程中发生错误: {e}")
import traceback
traceback.print_exc()
print("程序执行遇到问题,但已尽力完成")

 京公网安备 11010802022788号
京公网安备 11010802022788号







