


 雷达卡
雷达卡



从Naive RAG到Graph RAG:技术演进的必然路径
随着人工智能技术不断进步,检索增强生成(RAG)已成为连接大语言模型与专业领域知识的关键手段。然而,在面对复杂结构化数据和多维度查询需求时,传统的Naive RAG逐渐暴露出其局限性。尤其在膳食规划这类需要理解多重约束条件的应用场景中,其缺陷尤为突出。
传统RAG依赖非结构化文本进行信息检索,无法清晰表达实体之间的关系。例如,当用户提出“推荐适合素食者的早餐食谱,且热量低于1000卡路里”这样的复合查询时,系统难以准确解析其中涉及的饮食偏好、用餐时段与营养限制等多重条件。此外,其推理过程局限于单一层级,不具备执行多跳推理的能力——即无法像人类一样逐步推导:先筛选素食选项,再限定为早餐类目,最后按热量过滤。更关键的是,基于文本相似度的检索机制导致结果缺乏可解释性,用户无法追溯答案的生成逻辑。
而Graph RAG正是为解决上述问题应运而生。该框架依托图结构组织知识,具备三大核心优势:
- 显式建模实体关系:将食谱、食材、饮食需求等作为节点,通过“包含”“适合”等语义关系连接,构建出高度结构化的知识网络。
- 支持多跳推理:能够分步执行复杂查询,如依次判断是否符合素食标准、是否属于早餐类别、是否满足热量要求,实现类人思维的渐进式推理。
- 推理路径可追溯:每一步结论均可通过图中节点间的连接关系进行回溯,极大提升了系统的透明度与可信度。
项目概览:智能膳食助手的核心功能
本系统基于LangGraph构建了一个多智能体驱动的GraphRAG架构,以膳食规划为落地场景,展示了下一代增强生成技术的发展方向。尽管应用聚焦于食品营养领域,但其整体设计具有高度通用性,可迁移至医疗、金融、供应链等需复杂关系推理的行业。
系统主要解决三类典型任务:
- 根据用户的饮食限制(如素食、无麸质)推荐合适的食谱;
- 针对特定食谱自动生成精准的购物清单;
- 结合超市布局信息,帮助用户定位商品的具体货架位置。
为了应对多样化查询,系统融合了语义搜索与精确图查询两种模式:前者处理模糊匹配请求(如“甜一点的蛋糕”),后者则利用Cypher语言在Neo4j图数据库中执行结构化检索,确保响应既灵活又准确。
系统工作流程详解
整个处理流程分为四个阶段,形成闭环的认知-执行-反馈机制。
1. 查询分析与路由
这是交互的起点。系统首先对用户输入进行意图识别,判断其属于哪一类请求:是需要生成研究计划、补充信息,还是直接回答。例如,当用户仅说“推荐甜的食谱”时,系统会检测到缺失关键参数(如饮食类型、用餐时间),主动发起追问以完善上下文。
2. 研究计划生成
针对复杂的多条件查询,系统会制定分步执行的研究计划。例如,对于“热量低于1000卡路里的素食早餐”,系统将分解任务为:
- 通过语义搜索定位与“素食”相关的饮食节点;
- 查找标记为“早餐”的时间段节点;
- 执行联合查询,筛选同时满足以上条件且热量达标的食谱。
3. 图谱研究执行
此阶段由专用子智能体负责执行计划中的每一步。系统能自动生成对应的Cypher查询语句,在Neo4j知识图谱中检索目标节点及其关联路径。同时,结合语义向量搜索处理模糊表达,保证覆盖全面且精准的结果集。
4. 答案生成与呈现
最终,系统将获取的图谱数据整合,并交由大语言模型转化为自然语言输出。不仅返回推荐结果,还清晰展示推理链条,例如:“该食谱被推荐是因为它属于早餐类别,符合素食标准,且经计算总热量为850卡路里。”
知识图谱构建:从非结构化文本到结构化关系
高质量的知识图谱是系统运行的基础。为此,我们需将原始文本中的食谱、食材、营养信息等内容转化为图中的节点与边。借助大语言模型的强大理解能力,这一过程得以高效自动化完成。
选型方面,采用GPT-4o作为底层模型,因其在实体识别与关系抽取任务上表现优异。通过LangChain提供的LLMGraphTransformer工具,可定义允许提取的节点类型(如Recipe、Foodproduct)和关系类型(如CONTAINS),引导模型按规范格式输出结构化数据。
举例来说,给定一段描述:“素食巧克力蛋糕食谱包含无麸质面粉混合物、可可粉等食材……”,模型能自动识别出:
- 节点“Vegan Chocolate Cake Recipe”(类型:Recipe);
- 节点“无麸质面粉混合物”“可可粉”(类型:Foodproduct);
- 建立二者与食谱之间的“CONTAINS”关系。
具体代码实现如下:
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
# 初始化模型和转换器
llm = ChatOpenAI(temperature=0, model_name="gpt-4o")
llm_transformer_filtered = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Recipe", "Foodproduct"],
allowed_relationships=["CONTAINS"],
)
# 处理文本并提取图谱数据
text = "素食巧克力蛋糕食谱包含无麸质面粉混合物、可可粉等食材..."
documents = [Document(page_content=text)]
graph_documents_filtered = await llm_transformer_filtered.aconvert_to_graph_documents(documents)
通过上述代码处理后,提取出的图谱数据可利用 Neo4jGraph 的 add_graph_documents 方法写入数据库,从而构建初步的知识图谱结构。随后,可在 Neo4j 控制台中使用 Cypher 查询语句进行验证。例如,通过以下查询语句:
MATCH p=(r:Recipe)-[:CONTAINS]->(fp:Foodproduct) RETURN p LIMIT 25可以查看食谱与食材之间的关联关系。
为了实现更高效的语义搜索能力,还需为图谱中的节点添加嵌入向量(embedding)。以“食谱”节点为例,我们采用 OpenAI 提供的嵌入模型对食谱名称进行向量化表示,并将生成的向量存储至 Neo4j 数据库中,同时建立相应的向量索引以支持快速检索:
import openai
from neo4j import GraphDatabase
# 初始化数据库连接
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
# 生成指定食谱名称的嵌入向量
recipe_id = "Vegan Chocolate Cake Recipe"
recipe_embedding = openai.embeddings.create(
model="text-embedding-3-small",
input=recipe_id
).data[0].embedding
# 将嵌入向量写入对应节点
with driver.session() as session:
session.run(
"MATCH (r:Recipe {id: $recipe_id}) SET r.embedding = $embedding",
recipe_id=recipe_id,
embedding=recipe_embedding
)
# 创建向量索引(若不存在)
session.run(
"CREATE VECTOR INDEX recipe_index IF NOT EXISTS FOR (r:Recipe) ON (r.embedding) "
"OPTIONS {indexConfig: {`vector.dimensions`: 1536, `vector.similarity_function`: 'cosine'}}"
)
完成向量化后,当用户输入如“素食巧克力蛋糕食谱”这类查询时,系统会自动将其转换为语义向量,并借助向量索引匹配最相近的食谱节点。这种方式使得即使查询关键词与原始名称不完全一致,也能实现精准检索。
构建多智能体工作流:基于 LangGraph 的状态管理与节点协同
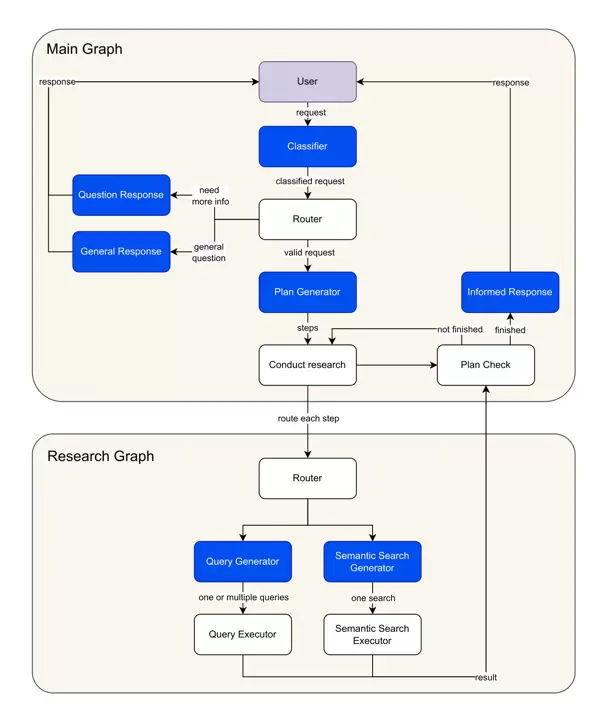
LangGraph 是实现该多智能体系统的核心框架,其设计思想是通过定义明确的状态在各个处理节点之间传递和共享信息,从而协调复杂的任务流程。整个架构由两个主要图构成:负责具体检索任务的“研究子图”,以及统筹整体执行逻辑的“主图”。
状态定义:驱动数据流动的关键结构
状态(State)作为系统的“记忆中枢”,决定了各节点间信息传递的格式与内容。首先定义 Router 类用于保存查询分类的结果,包含推理依据和分类类型——其中类型包括:"more-info"(需补充信息)、"valid"(有效查询)和 "general"(通用问题):
from typing import Literal
from pydantic import BaseModel
class Router(BaseModel):
logic: str
type: Literal["more-info", "valid", "general"]
接着定义输入状态类 InputState,用于维护用户与智能体之间的消息历史记录。而 AgentState 则继承自 InputState,并扩展了路由决策、研究步骤列表及累积知识等字段:
from dataclasses import dataclass, field
from typing import Annotated
from langchain_core.messages import AnyMessage
from langgraph.graph import add_messages
@dataclass(kw_only=True)
class InputState:
messages: Annotated[list[AnyMessage], add_messages]
@dataclass(kw_only=True)
class AgentState(InputState):
router: Router = field(default_factory=lambda: Router(type="general", logic=""))
steps: list[dict] = field(default_factory=list)
knowledge: list[dict] = field(default_factory=list)
这些状态类确保了在整个工作流中,所有中间结果和上下文信息能够被有序地传递、更新和累积。每个节点在完成处理后,都会将输出整合进当前状态,并交由下一个节点继续处理。
主图工作流:实现从用户提问到最终回答的端到端控制
主图负责调度整个对话流程,从接收原始查询开始,经过分类、信息获取、知识整合,最终生成自然语言回答。它依托于 AgentState 中定义的结构化字段,协调不同功能节点之间的协作,保障系统具备良好的可追踪性和可扩展性。
主图用于统筹整个工作流程,涵盖六个核心节点,各节点之间通过 edges 与 conditional edges 相互连接,构成一个完整且连贯的执行链路。
分析与路由查询(analyze_and_route_query)作为流程的起始点,负责接收用户输入的消息,并利用大语言模型对查询内容进行分类处理,生成对应的 Router 对象以更新当前状态。例如,当接收到类似“慕尼黑的天气如何?”这样的请求时,系统会将其归类为“general”,因为该问题不涉及食谱、购物清单或超市位置等特定主题。
async def analyze_and_route_query(state: AgentState, config: RunnableConfig) -> dict[str, Router]:
model = init_chat_model(name="analyze_and_route_query", **app_config["inference_model_params"])
messages = [{"role": "system", "content": ROUTER_SYSTEM_PROMPT}] + state.messages
response = await model.with_structured_output(Router).ainvoke(messages)
return {"router": response}
路由决策(route_query)根据上一步的分类结果决定后续操作路径:若分类为“valid”,则进入创建研究计划阶段;若为“more-info”,则触发信息补充流程;若为“general”,则转入通用回复处理流程。
在需要进一步信息的情况下,ask_for_more_info 节点将生成友好提示,主动向用户询问缺失的关键细节。例如,当用户仅提出“推荐甜的食谱”时,系统会追问饮食偏好、用餐时间等相关条件,以便精准响应。
而对于不属于支持范围的请求,则由 respond_to_general_query 节点处理,返回礼貌性回应,引导用户聚焦于相关领域的提问。
对于被判定为有效的查询,流程将进入 create_research_plan 阶段。此节点负责生成初步的研究计划,并对其进行精简和审查,确保每一步都具备可执行性和逻辑合理性。例如,面对“素食早餐,热量低于1000卡路里”的需求,系统可能规划出如下步骤:首先语义搜索与“素食”和“早餐”相关的知识节点,再通过属性筛选机制找出符合热量限制的具体食谱。
async def create_research_plan(state: AgentState, config: RunnableConfig) -> dict:
# 生成初始计划
model = init_chat_model(name="create_research_plan",** app_config["inference_model_params"])
system_prompt = RESEARCH_PLAN_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_structured_schema,
context="\n".join([item["content"] for item in state.knowledge])
)
messages = [{"role": "system", "content": system_prompt}] + state.messages
plan = await model.with_structured_output(Plan).ainvoke(messages)
# 精简和审查计划
reduced_plan = await reduce_research_plan(plan)
reviewed_plan = await review_research_plan(reduced_plan)
return {"steps": reviewed_plan["steps"], "knowledge": []}
MATCH p=(r:Recipe)-[:CONTAINS]->(fp:Foodproduct) RETURN p LIMIT 25conduct_research 节点负责逐项执行研究计划中的各个步骤。它调用研究子图来处理每一个任务单元,在执行过程中持续收集相关信息,并动态更新剩余待办步骤。通过内置的 check_finished 函数判断是否所有步骤均已执行完毕,若未完成则形成循环机制,直至全部任务结束,最终流转至 respond 节点,生成最终答复内容。
研究子图:实现精准检索的核心模块
研究子图是完成具体检索任务的关键组件,包含两条主要路径——语义搜索与查询生成执行,系统将依据步骤类型自动选择合适的处理路径。
语义搜索(semantic_search)适用于模糊匹配场景,如根据关键词“素食”查找对应的饮食类别节点。该过程首先借助大语言模型确定搜索参数,包括目标节点类型、属性字段及查询文本;随后使用 OpenAI 的嵌入模型生成查询向量,并在 Neo4j 的向量索引中检索最相似的节点记录。
def execute_semantic_search(node_label: str, attribute_name: str, query: str):
MATCH (r:Recipe {name: 'Classic Carbonara'})-[:CONTAINS]->(fp:FoodProduct)<-[:IS_INSTANCE_OF]-(sp:StoreProduct)
RETURN sp.name, sp.brand, sp.price, sp.quantity, sp.quantity_unit
LIMIT 50
index_name = f"{node_label.lower()}_{attribute_name}_index"
query_embedding = openai.embeddings.create(
model=app_config["embedding_model"],
input=query
).data[0].embedding
response = neo4j_graph.query(f"""
CALL db.index.vector.queryNodes('{index_name}', 1, {query_embedding})
YIELD node, score
RETURN node.name as name
ORDER BY score DESC
""")
return response
生成查询(generate_queries)
该模块负责结构化检索的处理,依据研究步骤动态构建Cypher查询语句。为确保语法与逻辑的准确性,系统引入双重校正机制:基于大语言模型(LLM)的模式感知校正和基于解析器的结构校正。
例如,在查找同时满足“素食”与“早餐”条件的食谱并计算其总热量时,系统将自动生成符合图数据库模式的查询指令。
async def generate_queries(state: ResearcherState, config: RunnableConfig) -> dict[str, list[str]]:
model = init_chat_model(name="generate_queries", **app_config["inference_model_params"])
system_prompt = GENERATE_QUERIES_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_schema,
context="\n".join([item["content"] for item in state.knowledge])
)
messages = [{"role": "system", "content": system_prompt}] + [{"role": "human", "content": state.step["question"]}]
response = await model.with_structured_output({"queries": list[str]}).ainvoke(messages)
# 应用LLM进行查询语句校正
response["queries"] = [await correct_query_by_llm(q) for q in response["queries"]]
# 使用解析器进行结构层面的修正
response["queries"] = [correct_query_by_parser(q) for q in response["queries"]]
return {"queries": response["queries"]}
execute_query 功能说明
此节点用于执行经过校正的Cypher查询语句,从Neo4j图数据库中提取所需数据,并将原始结果转换为标准化的知识条目格式,供后续流程调用与整合。
通过上述各节点的协同运作,研究子图实现了从模糊语义理解到精确结构化查询的完整闭环,融合向量检索与图遍历能力,显著提升了复杂多跳查询的准确性和效率。
实战案例:端到端查询处理流程
以用户输入“给我‘pasta alla carbonara’食谱的购物清单”为例,展示系统如何逐步解析并返回高质量结果。
初始阶段,该请求被传入主图的 analyze_and_route_query 节点进行意图识别。经分析后,系统判定其为有效的购物清单类查询,并将其路由至 create_research_plan 节点。
在研究计划构建阶段,系统制定出两个关键步骤:
- 利用语义搜索在Recipe节点中匹配与“pasta alla carbonara”最相近的食谱名称;
- 基于查找到的食谱,进一步检索其所关联的食材及对应商店产品信息,生成完整的购物清单。
随后,流程进入 conduct_research 阶段。第一步启动语义搜索,确定检索参数包括节点标签“Recipe”、属性“name”以及查询文本“pasta alla carbonara”。系统生成对应的嵌入向量,并在向量索引中进行近似最近邻查找,最终定位到最相似的食谱节点:“Classic Carbonara”。
第二步由 generate_queries 节点生成相应的Cypher查询语句,用于获取该食谱所需的全部商品详情。
MATCH (r:Recipe {name: 'Classic Carbonara'})-[:CONTAINS]->(fp:FoodProduct)<-[:IS_INSTANCE_OF]-(sp:StoreProduct)
RETURN sp.name, sp.brand, sp.price, sp.quantity, sp.quantity_unit
LIMIT 50查询成功执行后,系统返回相关商店产品信息,涵盖意大利面、培根、帕玛森芝士等核心食材,并包含每项产品的品牌、价格和推荐数量。
所有研究步骤完成后,控制流转入 respond 节点。系统将收集到的数据整合成自然语言形式的回答,输出一份结构清晰、内容详尽的购物清单,包含食材名称、建议品牌、单价及购买数量,便于用户直接参考使用。
本案例充分体现了系统将自然语言转化为多阶段精准检索的能力。通过结合语义理解与结构化图查询技术,系统能够高效应对复杂需求,实现从模糊输入到实用输出的无缝转化。
尽管Graph RAG在应对复杂查询任务中展现出卓越的能力,其实际应用过程中依然存在若干亟待解决的挑战。其中,系统延迟尤为突出。由于涉及多智能体之间的协同交互以及多步骤推理流程,整体架构的复杂度显著上升,进而导致响应速度下降。因此,如何在保障推理准确性的同时提升处理效率,成为技术优化的核心议题。
此外,评估机制与系统的可观察性也面临严峻考验。随着系统结构日益复杂,传统评估方法已难以全面反映Graph RAG的真实性能表现。为此,亟需构建一套更为科学、系统的评估框架。同时,增强系统的可观察性有助于追踪内部推理路径,及时识别异常环节并进行针对性优化,从而提升整体稳定性与透明度。
然而,Graph RAG所具备的优势不容忽视。它代表了人工智能在知识理解与处理层面的一次重要突破。通过融合大语言模型的强大语义理解能力与图结构在关系建模上的优势,该技术为复杂知识的组织与推理提供了全新的解决方案。未来,在医疗诊断、金融分析、智能教育等对深度知识推理有高需求的领域,Graph RAG有望实现广泛应用,助力人工智能向更高层次的智能化与可靠性迈进。

 京公网安备 11010802022788号
京公网安备 11010802022788号







