


 雷达卡
雷达卡



导入导出工具场景与使用方法说明
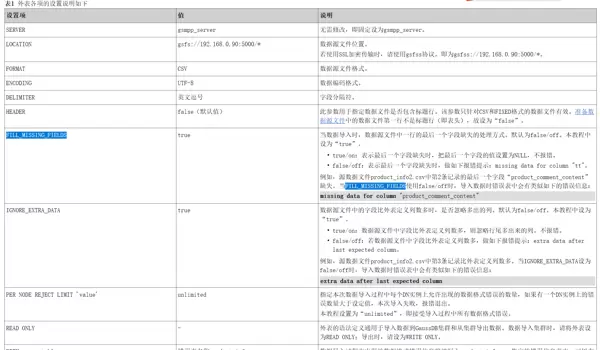
| 工具名称 | 适用架构 | 典型应用场景 | Oracle对应工具 |
|---|---|---|---|
| gsql | 集中式、分布式 | SQL脚本文件的小数据量导入导出 | sqlplus |
| copy to/from | 集中式、分布式 | 查询结果或表数据的在线文本格式导入导出(小数据量) | copy to/from |
| gs_dump/gs_restore | 集中式、分布式 | 数据库批量数据及对象定义的在线导入导出 | expdp/impdp |
| gs_loader | 仅支持集中式 | 兼容Oracle sqlloader 的在线导入场景 | sqlloader |
| GDS | 分布式 | 大规模离线数据的导入导出 | -- |

gsql 工具使用说明
适用范围:适用于集中式和分布式环境下,对小规模 SQL 文本进行导入或导出操作。
使用方式:
-
通过命令行参数执行导入
示例:执行指定路径下的 SQL 脚本文件
gsql -d postgres -p 8000 -Uroot -Whuawei@123Pwd -f /data/table.sql
参数解释:
-d:目标数据库名称-p:连接端口(集中式为 DN 端口,分布式为 CN 端口)-U:数据库登录用户名-W:用户密码-f:待执行 SQL 文件的绝对路径
-
通过元命令实现导入导出
首先使用 gsql 登录数据库:
gsql -d postgres -ra -p 8000
导入 SQL 文件:
\i [导入SQL文件的绝对路径]
导出查询结果到文件:
\o [导出结果存放的绝对路径]

copy to/from 使用方法
适用场景:适用于在集中式和分布式环境中,以文本格式处理小量数据的导入导出。
操作方式:
-
元命令方式(仅限服务端执行)
从文本文件导入数据至表 t1,字段分隔符为逗号:
\copy t1 from '/home/Ruby/test.txt' delimiter ',';
将表 t1 数据导出至文本文件:
\copy t1 to '/home/Ruby/test.txt' delimiter ',';
导出特定查询结果集:
\copy (select * from t2 where a2=1) to '/home/Ruby/test.txt' delimiter ',';
-
标准 COPY 命令(支持客户端和服务端执行)
导入文本数据:
copy t1 from '/home/Ruby/test.txt' delimiter ',';
导出表数据:
copy t1 to '/home/Ruby/test.txt' delimiter ',';
导出 SQL 查询结果:
copy (select * from t2 where a2=1) to '/home/Ruby/test.txt' delimiter ',';

gs_dump 与 gs_restore 使用指南
适用环境:可用于集中式和分布式系统中,完成数据库对象定义及数据的整体或部分导入导出。
导入示例:
gs_restore 支持从自定义归档格式(c)、目录归档(d)、tar 归档(t)等导出文件中恢复数据。
- 普通模式导入
gs_restore /home/Ruby/test.tar -d postgres -U root -W huawei@123Pwd -h 192.168.157.1 -p 8000
- 导入指定 schema
gs_restore /home/Ruby/test.tar -d postgres -U root -W huawei@123Pwd -h 192.168.157.1 -p 8000 -n PUBLIC
- 导入某 schema 下的特定表
gs_restore /home/Ruby/test.tar -d postgres -U root -W huawei@123Pwd -h 192.168.157.1 -p 8000 -n PUBLIC -t test
- 仅导入数据(不包含结构定义)
gs_restore /home/Ruby/test.tar -d postgres -U root -W huawei@123Pwd -h 192.168.157.1 -p 8000 -n PUBLIC -t test -a
- 仅导入对象定义(不含数据)
gs_restore /home/Ruby/test.tar -d postgres -U root -W huawei@123Pwd -h 192.168.157.1 -p 8000 -n PUBLIC -t test -s
常用参数说明:
-d:目标数据库名-U:执行导入操作的数据库用户-W:该用户的登录密码

gs_loader 是一款适用于集中式场景的数据导入工具,语法兼容 Oracle 的 sqlldr 工具。当用户在 Oracle 环境中使用过 sqlldr 进行数据加载,在迁移到 GaussDB 后可继续沿用 gs_loader 实现类似功能。该工具基于 \copy 命令实现。
常用参数说明(导出)
- dbname:指定要导出的数据库名称
- -U:执行导出操作所使用的用户名
- -W:对应用户的登录密码
- -h:设置导出目标数据库所在的主机IP地址
- -p:指定数据库监听端口号
- -n:用于限定需要导出的 schema,注意不会包含触发器信息,约束较多时建议查阅产品文档
- -t:指定具体要导出的表名
- -a:仅导出表中的数据内容
- -s:仅导出对象定义(如建表语句等结构信息)
- -N:排除指定的 schema 不进行导出
- -T:排除指定的表不参与导出
- -O:导出时不生成设置对象归属权的相关命令,便于与原始数据库保持一致
常用参数说明(导入)
- -h:指定目标数据库所在主机的IP地址
- -p:设定数据库服务监听的端口
- -n:指定需导入的目标 schema
- -t:指定要导入的具体数据表,此操作不涉及触发器信息,且存在较多约束,请参考官方文档说明
- -a:仅执行数据部分的导入
- -s:仅导入对象定义信息
- -O:将导入表的所有者设为当前用户
gs_dump 导出示例
gs_dump 支持多种文件输出格式,包括:纯文本格式 p(.sql)、自定义归档格式 c(.dmp)、目录归档格式 d(dir)以及 tar 归档模式 t(.tar)。
-
普通导出
- 导出为纯文本格式:
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.sql -F p
- 导出为自定义归档格式:
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.dmp -F c
- 导出为目录归档格式:
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test -F d
- 导出为 tar 格式:
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.tar -F t
- 导出为纯文本格式:
-
导出特定 schema
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.sql -F p -n PUBLIC
-
导出指定表
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.sql -F p -n PUBLIC -t test
-
仅导出数据
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.sql -F p -n PUBLIC -t test -a
-
仅导出定义
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.sql -F p -n PUBLIC -t test -s
-
排除某个 schema 进行导出
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.sql -F p -N PUBLIC
-
排除指定表
gs_dump postgres -U root -W huawei@123Pwd -h192.168.157.1 -p 8000 -f /home/Ruby/test.sql -F p -T test
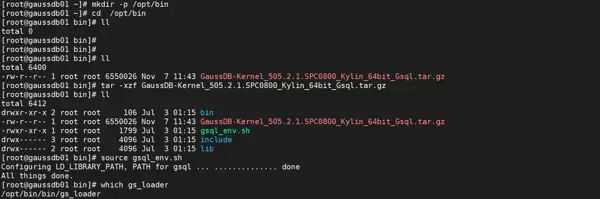
gs_loader 安装与部署步骤
- 创建用于存放工具包的目录:
mkdir -p /opt/bin
- 将 gsql 工具包上传至上述目录中。
上传文件示例:“GaussDB-Kernel_数据库版本号_操作系统版本号_64bit_gsql.tar.gz” 到 /opt/bin 目录。
- 进入工具包所在目录并解压:
cd /opt/bin tar -zxvf GaussDB-Kernel_数据库版本号_操作系统版本号_64bit_gsql.tar.gz source gsql_env.sh
- 验证工具安装路径及是否存在:
which gs_loader
- 检查客户端版本信息:
gs_loader 的版本与 gsql 客户端一致,可通过以下命令查看:gsql -V
- 确认数据库服务端版本信息,确保与客户端版本匹配:
使用 gsql 成功连接数据库后,执行如下 SQL 查询:select version();
参数校验
在执行导入或导出操作前,建议对关键参数进行检查,确保主机、端口、用户权限、网络连通性及目标路径可写等条件满足要求,避免任务执行失败。
参数 enable_copy_error_log 用于控制是否启用错误表 gs_copy_error_log 和日志表 gs_copy_summary_log。默认值为 off,表示不使用这两个数据库表进行记录。此时,所有错误信息将直接写入 gs_loader 的 bad 文件中,日志信息则写入 gs_loader 的 log 文件中。
当该参数设置为 on 时,系统会启用 gs_copy_error_log 和 gs_copy_summary_log 表,并将相应的错误和日志数据插入到这些表中。
可通过以下命令动态加载配置:
gs_guc reload -Z datanode -N all -I all -c "enable_copy_error_log = on"接下来创建用于数据导入的用户:
CREATE USER load_user WITH PASSWORD 'huawei@123Pwd';并授予其必要的权限:
GRANT ALL ON FUNCTION copy_error_log_create() TO load_user;
GRANT ALL ON SCHEMA public TO load_user;
SELECT copy_error_log_create();
SELECT copy_summary_create();
GRANT ALL PRIVILEGES ON pg_catalog.pgxc_copy_error_log TO load_user;
GRANT ALL PRIVILEGES ON pg_catalog.gs_copy_summary TO load_user;在开启日志表功能前,需执行函数 copy_error_log_create() 与 copy_summary_create() 来生成对应的日志表。执行后将创建出 pgxc_copy_error_log 和 gs_copy_summary 两张表。
随后,创建名为 loader.ctl 的控制文件:
vi loader.ctl在文件中添加如下内容:
Load Data
TRUNCATE INTO TABLE gsloader
FIELDS TERMINATED BY ','
TRAILING NULLCOLS(
id "trim(:id)",
text "to_char(SYSDATE,'yyyymmdd')",
gmt_create ?"trim(:gmt_create)",
create_str "trim(:create_str)"
)控制文件各参数说明如下:
- Load Data:控制文件的起始标识关键字。
- TRUNCATE INTO TABLE gsloader:表示在加载数据前清空目标表
gsloader。其中TRUNCATE可替换为INSERT(追加数据)或REPLACE(删除原有数据后插入新数据)。 - FIELDS TERMINATED BY:指定字段之间的分隔符。
- TRAILING NULLCOLS:用于处理源数据中字段缺失的情况,缺失字段将自动填充为 NULL。
- id "trim(:id)":实现字段映射与类型转换,支持对字符类型进行处理。
执行导入操作时,确保用户 load_user 拥有对应表的操作权限。示例如下:
gs_loader control=loader.ctl data=data.csv db=testdb discard=loader.dis bad=loader.bad errors=5 host=172.16.104.15 port=8000 passwd='huawei@123Pwd' user=load_user常用参数说明:
- control:指定控制文件路径。
- data:指定待导入的数据文件。
- db:指定目标数据库名称。
- discard:定义 WHEN 条件不匹配时的废弃行存储文件,可指定目录,系统将根据数据文件名自动生成文件名。
- errors:允许的最大错误行数,超过此数量则任务终止。
- bad:记录出错行及其详细信息的文件名称,也可指定目录,若未指定则按数据文件名生成。
GDS(General Data Service)适用于分布式环境下大规模数据导入导出效率低下的场景。
其工作原理如下:
- CN 节点仅负责任务的规划与分发,实际的数据加载由 DN 节点完成。
- GDS 进程对输入数据进行切分,并分配给各个 DN 节点。
- 各 DN 节点对接收到的数据进行处理,依据分布列计算哈希值,将属于本节点的数据缓存至本地,不属于本节点的数据则通过网络发送至对应 DN。
GDS 使用方法:
首先启动 GDS 服务:
查看 GDS 版本信息:
gds -V查询数据库版本,确保 GDS 版本与数据库内核版本一致,避免因版本不兼容导致错误:
SELECT version();启动 GDS 命令格式如下:
gds -d dir -p ip:port -H address_string -l log_file -D -t worker_num --enable-ssl off参考示例:
在 IP 地址为 10.164.3.8、端口为 50001 的服务器上,启动位于 /home/Ruby/tpch 目录的 GDS 服务。
gds -d /home/Ruby/tpch/ -p 10.164.3.8:50001 -H 0.0.0.0/0 -l /tmp/gds_tpch_1.log -D -t 2 --enable-ssl off
参数详解:
- -d dir:指定包含待导入数据文件的目录路径。
- -p ip:port:设置GDS监听的IP地址与端口号。默认为127.0.0.1,需更改为可与GaussDB通信的万兆网IP地址。
- -H address_string:定义允许连接并使用GDS服务的主机范围,需采用CIDR格式。应确保该网段覆盖GaussDB集群所有节点。若使用IPv6,则-p和-H需同时配置为IPv6格式。
- -l log_file:设定GDS日志输出路径及文件名。
- -D:使GDS在后台运行,仅适用于Linux操作系统。
- -t worker_num:配置GDS并发处理线程数量。当GaussDB和数据服务器具备充足I/O资源时,适当增加线程数可提升性能。
GDS根据导入事务的并发情况动态分配服务线程。即使启动时指定了多线程模式,也不会加快单个导入事务的速度。默认情况下,每条INSERT语句视为一个独立的导入事务。
- --enable-ssl:控制是否启用SSL加密传输数据。默认开启(on),如不显式设置则无需添加此参数;若启用,需配合--ssl-dir指定证书路径。
- --ssl-dir Cert_file:指定SSL证书存放目录,必须与已配置的证书路径一致。
停止GDS服务
ps aux |grep gds| grep -v 'grep' |awk '{print $2}' |xargs kill -9
创建外部表
CREATE FOREIGN TABLE TESTGDS_LOAD (
ID INT,
NAME CHAR(10),
AGE INT
)
SERVER gsmpp_server
OPTIONS (
LOCATION 'gsfs://10.164.3.8:50001/lineitem.tbl',
FORMAT 'TEXT',
DELIMITER '|',
ENCODING 'utf8',
HEADER 'false',
FILL_MISSING_FIELDS 'true',
IGNORE_EXTRA_DATA 'true'
)
LOG INTO product_info_err
PER NODE REJECT LIMIT 'unlimited';
执行数据导入
通过INSERT SELECT语句将外部表数据导入目标表:
INSERT INTO TESTGDS SELECT * FROM TESTGDS_LOAD;
再次关闭GDS服务
ps aux |grep gds| grep -v 'grep' |awk '{print $2}' |xargs kill -9
场景测试示例:gs_loader 使用练习
部署 gs_loader 工具
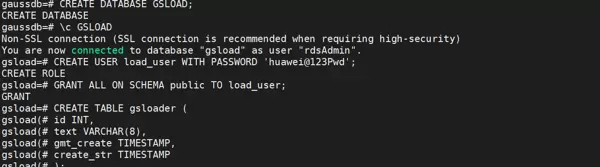
准备数据库环境
CREATE DATABASE GSLOAD;
切换至GSLOAD数据库上下文。
CREATE USER load_user WITH PASSWORD 'huawei@123Pwd'; GRANT ALL ON SCHEMA public TO load_user;
建表示例
CREATE TABLE gsloader (
id INT,
text VARCHAR(8),
gmt_create TIMESTAMP,
create_str TIMESTAMP
);
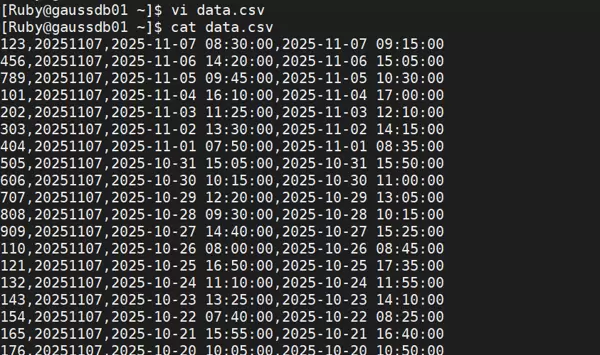
准备本地数据文件
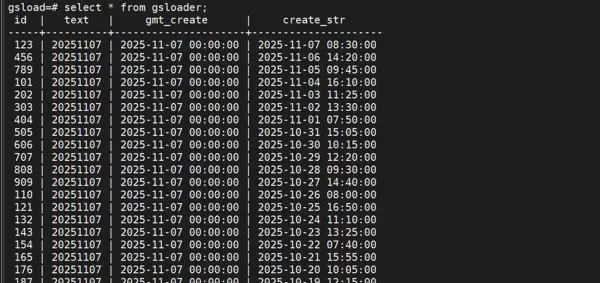
创建名为 data.csv 的CSV文件,并填入以下内容:
123,20251107,2025-11-07 08:30:00,2025-11-07 09:15:00 456,20251107,2025-11-06 14:20:00,2025-11-06 15:05:00 789,20251107,2025-11-05 09:45:00,2025-11-05 10:30:00 101,20251107,2025-11-04 16:10:00,2025-11-04 17:00:00 202,20251107,2025-11-03 11:25:00,2025-11-03 12:10:00 303,20251107,2025-11-02 13:30:00,2025-11-02 14:15:00 404,20251107,2025-11-01 07:50:00,2025-11-01 08:35:00 505,20251107,2025-10-31 15:05:00,2025-10-31 15:50:00
176,20251107,2025-10-20 10:05:00,2025-10-20 10:50:00
187,20251107,2025-10-19 12:15:00,2025-10-19 13:00:00
165,20251107,2025-10-21 15:55:00,2025-10-21 16:40:00
154,20251107,2025-10-22 07:40:00,2025-10-22 08:25:00
143,20251107,2025-10-23 13:25:00,2025-10-23 14:10:00
132,20251107,2025-10-24 11:10:00,2025-10-24 11:55:00
121,20251107,2025-10-25 16:50:00,2025-10-25 17:35:00
110,20251107,2025-10-26 08:00:00,2025-10-26 08:45:00
909,20251107,2025-10-27 14:40:00,2025-10-27 15:25:00
808,20251107,2025-10-28 09:30:00,2025-10-28 10:15:00
707,20251107,2025-10-29 12:20:00,2025-10-29 13:05:00
606,20251107,2025-10-30 10:15:00,2025-10-30 11:00:00
创建控制文件
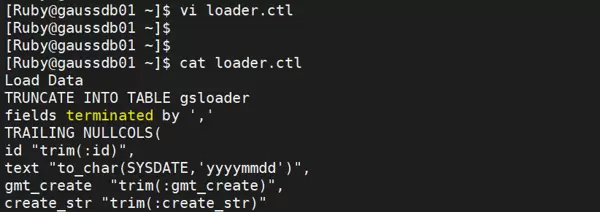
使用 vi 编辑器创建 loader.ctl 文件:
vi loader.ctl
在文件中添加以下内容:
Load Data TRUNCATE INTO TABLE gsloader fields terminated by ',' TRAILING NULLCOLS( id "trim(:id)", text "to_char(SYSDATE,'yyyymmdd')", gmt_create ?"trim(:gmt_create)", create_str "trim(:create_str)" )
执行 gs_loader 数据导入
运行如下命令进行数据加载:
gs_loader control=loader.ctl data=data.csv db=gsload discard=loader.dis bad=loader.bad errors=5 host=172.16.104.15 port=8000 passwd='huawei@123Pwd' user=load_user

权限问题处理
若导入过程中提示权限不足,需为用户授予更高权限:
alter user load_user with sysadmin;
完成授权后重新执行导入命令:
gs_loader control=loader.ctl data=data.csv db=gsload discard=loader.dis bad=loader.bad errors=5 host=172.16.104.15 port=8000 passwd='huawei@123Pwd' user=load_user

GDS 测试练习
首先创建用于测试的表结构:
CREATE TABLE TESTGDS ( ID INT , NAME CHAR(10), AGE INT );
启动 GDS 服务
执行以下命令启动 GDS 进程:
gds -d /home/Ruby/gds/ -p 192.168.0.134:50001 -H 0.0.0.0/0 -l /tmp/gds_test.log -D -t 2 --enable-ssl off

准备外部数据文件
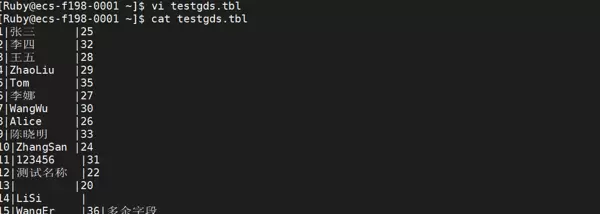
在目录 /home/Ruby/gds/ 下创建名为 testgds.tbl 的文件,并写入以下测试数据:
1|张三 ?????|25 2|李四 ?????|32 3|王五 ?????|28 4|ZhaoLiu ??|29 5|Tom ??????|35 6|李娜 ?????|27 7|WangWu ???|30 8|Alice ????|26 9|陈晓明 ???|33 10|ZhangSan |24 11|123456 ???|31 12|测试名称 ?|22 13| ????????|20 14|LiSi ?????| 15|WangEr ???|36|多余字段
创建外部表映射
定义一个指向本地文件的外部表,以便通过数据库访问该数据:
CREATE FOREIGN TABLE TESTGDS_LOAD ( ID INT , NAME CHAR(10), AGE INT ) SERVER gsmpp_server OPTIONS ( LOCATION 'gsfs:// 192.168.0.134 :50001/testgds.tbl', FORMAT 'TEXT' , DELIMITER '|', ENCODING 'utf8', HEADER 'false', FILL_MISSING_FIELDS 'true', IGNORE_EXTRA_DATA 'true' )
LOG INTO product_info_err PER NODE REJECT LIMIT 'unlimited'; INSERT INTO TESTGDS SELECT * FROM TESTGDS_LOAD;数据导入过程中出现错误,需检查数据库参数 enable_stream_operator 是否已设置为 ON。
终止GDS进程操作如下: 通过ps命令查找相关进程,过滤出非grep自身的GDS进程,并使用kill -9强制结束: ps aux |grep gds| grep -v 'grep' |awk '{print $2}' |xargs kill -9


 京公网安备 11010802022788号
京公网安备 11010802022788号







