


 雷达卡
雷达卡



一、词向量(词嵌入)
将自然语言中的词汇转化为机器可处理的数值型向量,是自然语言处理中的基础步骤。这种转化过程被称为词向量或词嵌入。
1. 编码方式
OneHot独热编码
OneHot编码是一种基于离散符号表示词的方法。在该方法中,词向量的维度等于词汇表的总词数。每个词对应一个唯一的编号,在该位置上取值为1,其余位置均为0。
缺点在于:当词汇量庞大时,向量维度极高,且各词之间相互独立,无法体现语义上的关联性。
分布式语义表示
与OneHot不同,分布式语义表示将每个词映射到一个多维实数空间中的点,即一个实数向量。在这个空间中,语义相近的词彼此距离更近,从而能够捕捉词语之间的相似性和关系。
2. 词向量构建方法
Word2Vec
基于大规模语料库进行训练,为词汇表中的每一个词学习出对应的向量表示。其核心思想是:上下文越相似的词,语义也越接近。
模型通过滑动窗口确定中心词 $c$ 及其周围的上下文词 $o$。以预测上下文为例,输入层仅激活中心词对应的位置,经由隐藏层连接后,输出层通过softmax函数生成对V个可能上下文词的概率分布。目标是使正确上下文词的概率最大化。
在此过程中存在两组权重矩阵U和V,分别对应输入到隐藏层、隐藏层到输出层的连接权重,最终概率由这两个词向量的内积决定。
不足之处在于:虽然输入计算简单(只需激活一个节点),但输出端需计算全部V个词的概率,计算开销较大。
GloVe
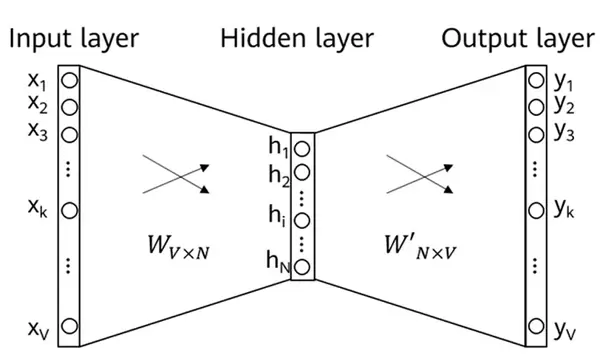
采用统计共现信息来构建词向量。首先设定固定大小的上下文窗口,若两个词在同一窗口内出现,则认为它们共现,并记录在共现矩阵中。该矩阵是对称的,第$i,j$项表示词$i$与词$j$共同出现的频率。
目标是让任意两个词的向量乘积尽可能逼近其共现频率的对数值。引入权重函数$f$,用于调节高频共现对损失的影响——频率越高,权重越大,学习优先级更高。
最终得到的词向量为两个向量之和(如中心词向量与上下文向量之和)。
局限性:无法有效处理未登录词(OOV),即不在原始词汇表中的新词。
fastText
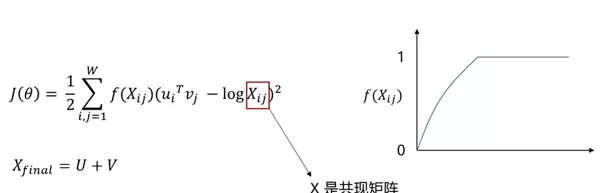
与传统方法不同,fastText利用字符级别的n-gram信息。它将单词拆分为多个子词单元(subword units),然后将整个词的向量表示定义为所有子词向量的累加和。
这一机制使得模型具备一定的泛化能力,可以为未曾在训练集中出现的词生成合理的向量表示,从而有效应对未登录词问题。
3. 词向量评估方法
内部评估
- 相似度任务:通过计算词向量间的余弦相似度或欧氏距离,衡量语义相近程度。
- 类比推理任务:例如 $King - Man + Woman \approx Queen$,检验词向量是否能捕捉语法或语义类比关系。
外部评估
将词向量应用于具体NLP任务,根据下游任务的表现来间接评价其质量。常见任务包括命名实体识别、机器翻译、文本分类、情感分析等。
二、文本分类
定义:给定一篇文档 $d$ 和一组预定义类别集合 $C = \{C_1, C_2, ..., C_j\}$,目标是判断该文档所属的类别。
典型应用:情感倾向判断、用户意图识别、内容合规性审核等。
深度学习方法
TextCNN
不同于图像领域中的二维卷积,TextCNN在文本序列上执行一维卷积操作。卷积核沿词序列方向滑动,提取局部n-gram特征,而不会跨词向量维度移动。
TextRNN
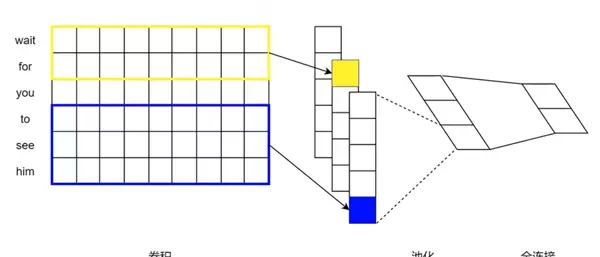
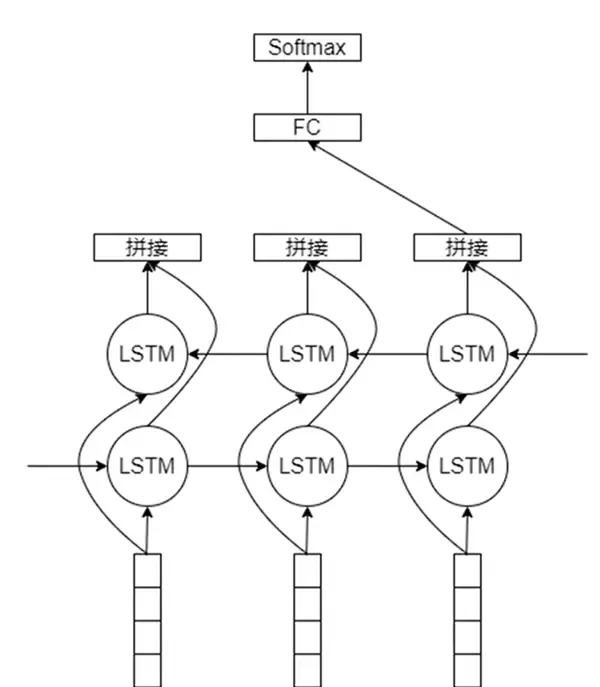
使用循环神经网络结构建模文本序列。以双向LSTM为例,前向和后向LSTM分别读取正序和逆序输入,相同时间步的隐藏状态被拼接起来,形成包含上下文信息的完整表示。
三、序列标注
对于每个输入元素 $x_i$,都分配一个对应的标签 $y_i$,实现逐元素的结构化预测。
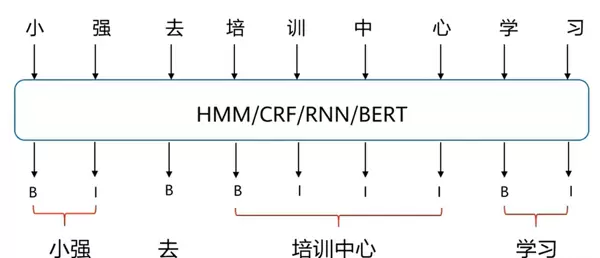
中文分词
Chinese Word Segmentation 指的是将连续的汉字序列切分成有意义的词语单位。该过程本质上是依据语言规则将字串重新组合成词序列。
常用标注体系中,B表示新词的起始位置,I表示延续前一个词的部分。
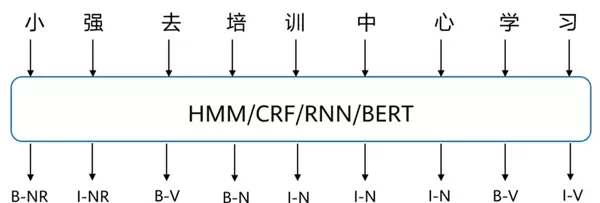
词性标注
Part-Of-Speech tagging (POS tagging) 是指为句子中每个已切分的词赋予正确的词性类别,如名词、动词、形容词等。它是许多高级NLP任务(如句法分析、信息抽取)的重要前置步骤,虽非绝对必需,但能显著提升后续处理效率与准确性。
示例标记中,N代表名词,V代表动词。
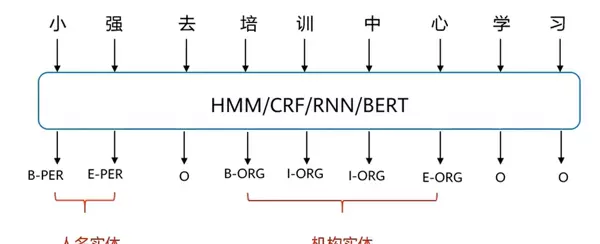
命名实体识别
Named Entity Recognition (NER) 是自然语言处理的基础任务之一,旨在从文本中识别并分类特定类型的命名实体,如人名、地名、机构名、时间、货币金额、百分比等。
通常采用BIOES标注体系:B表示实体开始,I表示实体中间部分,E表示结束,O表示非实体,S表示单字实体。
CRF(条件随机场)
Conditional Random Field (CRF) 改进了隐马尔可夫模型(HMM)中存在的标签偏置问题和上下文依赖缺失问题。它取消了HMM的两个独立性假设,将标签转移关系和当前上下文特征统一纳入全局建模框架。
特征函数 $f$ 的输入包括整个句子文本 $x$ 和标签序列 $y$,其中 $y$ 可涉及相邻两个位置,从而捕获标签间的转移模式。由于考虑的是整条标签路径,因此实现了全局归一化。
打分函数中,$\lambda$ 为可学习参数,通过双重循环遍历序列位置和特征类型,累计所有相关特征得分。
最终通过归一化指数函数(类似softmax)对所有可能的标签序列求和作为分母,寻找具有最高概率的最优标签序列。
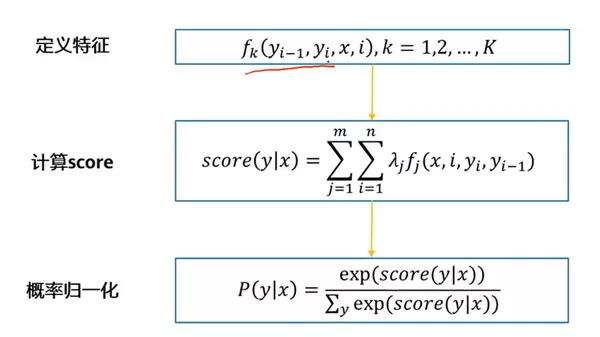
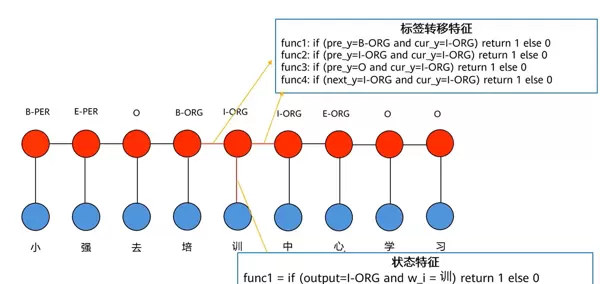
特征函数主要包括以下几类:
四、语言模型与文本生成
语言模型的核心任务是根据已知的词序列预测下一个最可能的词。给定一个词序列 w, w, ..., wi1,模型需要计算下一个词 w 出现的概率分布:
P(w|w, w, ..., wi1)
1. N-Gram 语言模型
该模型基于 n 元语法(n-gram),通过统计方法估算条件概率。其基本假设是:当前词仅受前 n1 个词的影响,超出此范围的历史信息被忽略。因此,可使用频率计数比值来近似计算条件概率:
P(w|w, w, ..., wi1) ≈ P(w|wi(n1), wi(n2), ..., wi1) = count(wi(n1), ..., wi1, w) / count(wi(n1), ..., wi1)
当 n=1 时称为一元模型(unigram),n=2 时为二元模型(bigram)。
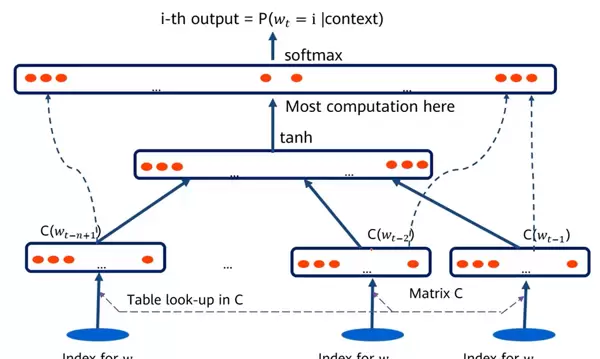
2. 固定窗口神经网络语言模型
在此类模型中,输入为固定大小的滑动窗口内的词。每个词首先被转换为对应的词向量,随后这些向量按顺序拼接成一个联合输入,送入隐藏层进行处理。最终输出结合所有词向量信息,通过 softmax 层产生对下一个词的概率预测。
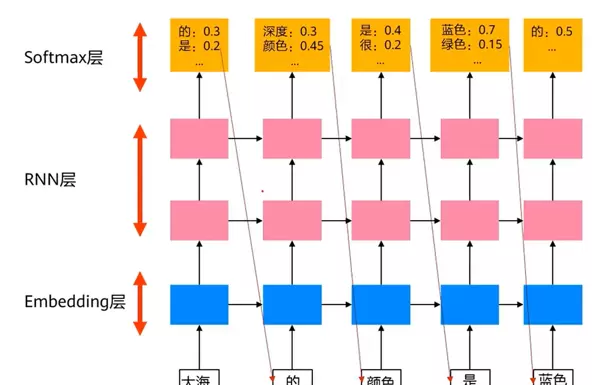
3. RNN 语言模型
采用单向循环神经网络(RNN)构建语言模型,避免使用双向结构,以防模型在预测时“看到”未来待预测的词。在训练过程中,当前时刻的输出应最大化对应下一个真实词的标签概率。
语言模型用于生成词向量
传统静态词向量(如 Word2Vec)无法体现一词多义现象。而基于语言模型的方法可以生成上下文相关的动态词向量,使同一个词在不同语境下拥有不同的表示。
1. ELMo(Embeddings from Language Models)
ELMo 使用两个独立的双向 LSTM 构建,但每个方向仍保持单向传播逻辑,以维持语言的时间顺序特性。
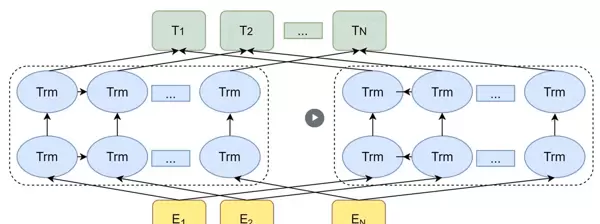
句子从左到右和从右到左分别输入两个方向的LSTM,形成双层结构:
- 第一层 LSTM(h)主要捕捉句法层面的信息,例如词性标注和短语结构;
- 第二层 LSTM(h)更侧重于语义理解,反映词语在上下文中的具体含义。
对于句子中的每一个词(如示例中的“退了”),提取其在双向 LSTM 各层的隐状态,并将左右方向的表示进行拼接。
最终的词向量由多个层级的隐状态经可学习权重加权融合而成,实现灵活且丰富的上下文感知表达。

2. BERT(Bidirectional Encoder Representations from Transformers)
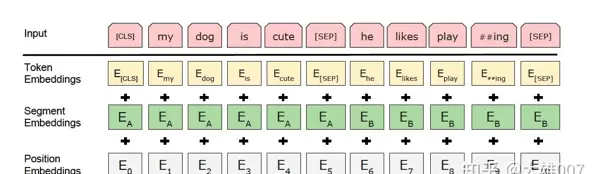
BERT 模型通过堆叠多个 Transformer 编码器层构成,其输入嵌入由三种向量相加而成:
- Token Embeddings:即常规的词向量。输入的第一个位置固定为 [CLS] 标记,其最终隐藏状态可用于表示整个句子的语义。每个词被映射为 768 维的向量;
- Segment Embeddings:用于区分两个不同的句子,适用于涉及句子对的任务(如自然语言推理),帮助模型判断两句话之间的关系;
- Position Embeddings:引入位置信息,表示词在序列中的顺序,弥补 Transformer 本身无序性的不足。
五、序列到序列模型(Seq2Seq)
序列到序列模型(Sequence-to-sequence, Seq2Seq)是一种典型的 encoder-decoder 架构,通常由双向 RNN 构成,能够处理变长输入与输出序列之间的映射问题,广泛应用于机器翻译、摘要生成等任务。
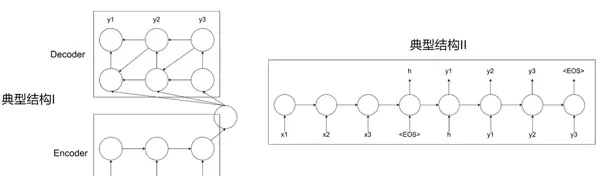
其中,Encoder 负责编码输入序列并提取关键特征,Decoder 则基于这些信息逐步生成目标序列。
典型结构有两种信息传递方式:
- 结构一:Encoder 提取的整体信息参与 Decoder 每一步的生成过程;
- 结构二:仅在 Decoder 的初始时刻传入 Encoder 的最终状态。
然而,这类模型存在明显缺陷:所有输入信息都压缩至最后一个时间步的隐状态中传递给解码器,导致在面对长文本时,信息容易丢失或压缩过度,限制了模型的表达能力。
标签转移与状态特征
标签转移特征:强调相邻标签之间的依赖关系,例如在命名实体识别中,“B-PER”之后更可能接“I-PER”,而非直接跳转为其他类型标签。
状态特征:关注特定输入条件下模型应对各个输出标签赋予的打分依据,即某一时刻某标签的匹配程度取决于当前输入内容。
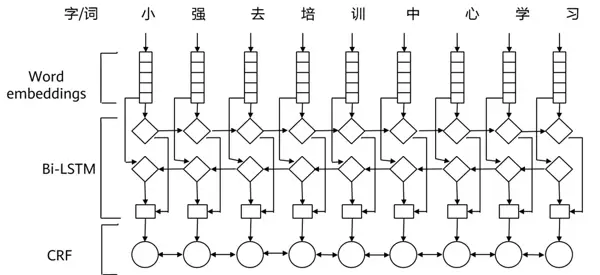
2 BiLSTM + CRF 模型架构
在 BiLSTM 输出的基础上引入 CRF(条件随机场)层,可以有效增强标签间的转移约束。BiLSTM 负责提取上下文特征并输出各标签得分,CRF 则进一步建模标签序列的整体合法性,优化最终路径选择,提升序列标注任务的准确性。

 京公网安备 11010802022788号
京公网安备 11010802022788号







