


 雷达卡
雷达卡



0 前言
近年来,毕业设计与答辩的标准日益提高,传统选题普遍缺乏创新性与技术深度,难以满足评审要求。不少同学反映所完成的系统项目在功能或实现上无法达到预期水平,同时完整且高质量的参考资料也较为稀缺。
为帮助大家更高效地完成毕业设计,减少不必要的试错成本,本文分享一个具备实际应用价值和技术亮点的优质课题案例——基于深度学习的智慧农业苹果采摘定位辅助系统(含源码与论文参考)。
项目综合评分(每项满分5分):
难度系数:3分
工作量:4分
创新点:5分
1 项目运行效果
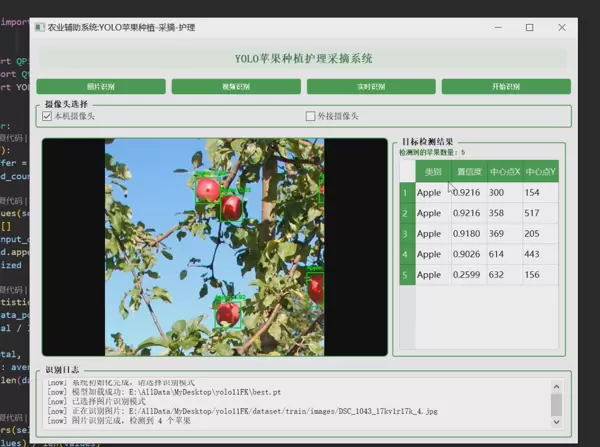
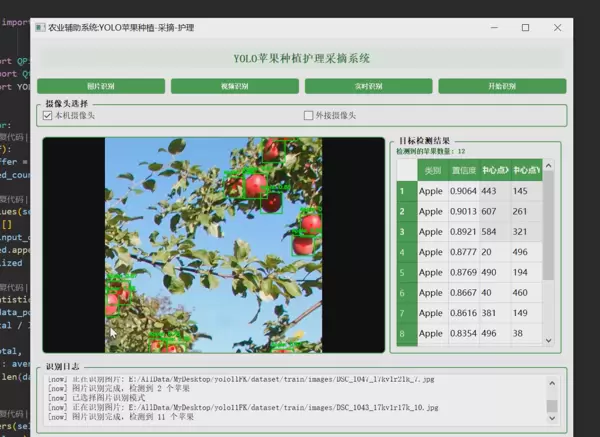
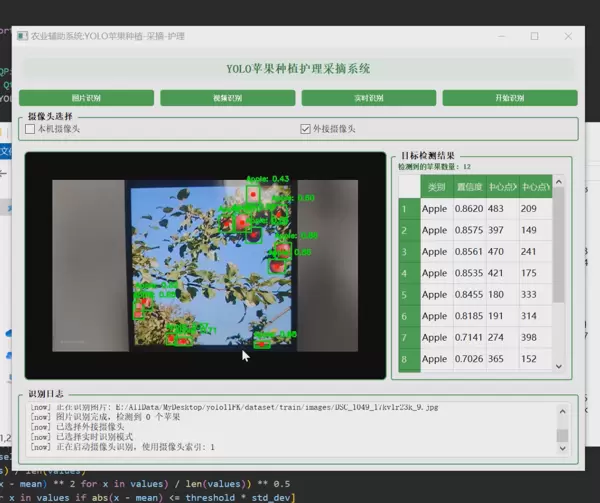

2 课题背景
2.1 农业智能化发展需求
当前全球农业生产正面临劳动力短缺和运营成本上升的双重挑战。以中国苹果产业为例,2022年种植面积已达到197万公顷,但果实采摘仍高度依赖人工操作,其成本占整体生产支出的35%以上。传统采摘方式存在三大核心问题:
- 人力成本高:每日人均用工费用约为40–50元
- 作业效率低:熟练工人平均每天仅能处理300–500kg果实
- 损伤率偏高:运输及采摘过程中果实损耗率达15–20%
2.2 计算机视觉技术发展
随着深度学习技术的不断突破,计算机视觉在目标检测领域取得了显著进展:
- YOLO系列模型mAP指标从v3版本的60.6%提升至v8版本的78.9%
- 轻量化模型参数规模压缩至5MB以下(如Nano版本)
- 在RTX3060显卡上的推理速度可达120FPS
这些性能提升为将先进视觉算法应用于复杂农业环境提供了坚实的技术支撑。
2.3 现有技术瓶颈
尽管已有部分农业机器人投入使用,但在实际应用中仍存在明显局限:
- 识别准确率不足:在光照变化频繁的果园环境中,误检率超过25%
- 空间定位精度差:现有双目视觉系统的定位误差大于10mm
- 实时响应能力弱:图像处理延迟超过500ms,无法适应动态采摘节奏
2.4 本课题创新点
针对上述问题,本系统提出以下关键技术改进:
- 优化YOLOv8网络结构,引入改进型注意力机制,增强对遮挡苹果的识别能力
- 融合RGB-D相机获取的深度信息,将三维定位误差控制在±3mm以内
- 设计轻量级推理引擎架构,确保端到端处理延迟低于100ms
2.5 应用价值预测
初步测算表明,该系统投入使用后可带来如下效益:
- 单台设备日处理能力达2吨,相当于替代6名人工劳动力
- 设备投资回收周期预计少于2年
- 采后果实商品化率提升至95%以上,显著改善产出质量
3 设计框架
3.1 系统概述
本系统是一款面向智慧农业场景的苹果采摘辅助工具,依托计算机视觉与深度学习技术,实现对苹果位置的精准检测与实时定位。系统采用YOLO(You Only Look Once)目标检测模型作为核心算法,结合PyQt5开发图形交互界面,支持三种工作模式:图片识别、视频流识别以及实时摄像头输入识别,满足多样化应用场景需求。
3.2 技术架构
3.2.1 核心技术栈
系统构建于以下关键技术之上:
- 深度学习框架:Ultralytics YOLO v8
- GUI开发框架:PyQt5
- 图像处理库:OpenCV (cv2)
- 科学计算库:NumPy
- 操作系统接口模块:Python os, sys
3.2.2 系统架构图
+---------------------------------------------+
| YOLO苹果采摘定位辅助系统 |
+---------------------------------------------+
| |
| +-------------------+ +----------------+ |
| | 用户交互层(UI) | | 系统控制层 | |
| | +-----------+ | | +----------+ | |
| | | PyQt5 | | | | 模式选择 | | |
| | +-----------+ | | +----------+ | |
| +-------------------+ +----------------+ |
| |
| +-------------------+ +----------------+ |
| | 视觉处理层 | | 数据处理层 | |
| | +-----------+ | | +----------+ | |
| | | OpenCV | | | | 结果分析 | | |
| | +-----------+ | | +----------+ | |
| +-------------------+ +----------------+ |
| |
| +-------------------------------------------+
| | 模型推理层 |
| | +-----------------------------------+ |
| | | YOLO 模型 | |
| | +-----------------------------------+ |
| +-------------------------------------------+
| |
+---------------------------------------------+3.3 系统组件详解
3.3.1 模型推理组件
作为系统的核心模块,模型推理组件基于YOLO目标检测算法,并使用专门标注的苹果数据集进行训练,能够在复杂背景下快速准确识别图像中的苹果目标。
3.3.1.1 YOLO模型特点
- 属于单阶段检测器,具有较高的推理速度,适合实时检测任务
- 可并行预测多个目标的位置框与类别标签
- 通过预训练加微调策略,针对果园光照、遮挡等特殊场景进行了针对性优化
3.3.1.2 模型加载与推理伪代码
def load_model():
# 加载预训练的YOLO模型
model_path = "best.pt" # 训练完成的权重文件路径
model = YOLO(model_path)
3.3.2 视频处理组件
该模块负责处理连续视频帧流,包括从本地文件或摄像头读取画面、逐帧解码、传递给检测模型进行推理,并输出带有标注结果的视频流。
3.3.2.1 视频线程工作流程
- 启动独立线程读取视频源(文件或摄像头)
- 按帧解码并调整尺寸以适配模型输入
- 将图像送入YOLO模型进行推理
- 接收检测结果并绘制边界框与标签
- 将处理后的帧显示在UI界面上
3.3.2.2 视频处理伪代码
while video_capture.isOpened():
ret, frame = video_capture.read()
if not ret:
break
results = model(frame)
annotated_frame = results[0].plot()
display(annotated_frame)
3.3.3 用户界面组件
用户界面由PyQt5构建,提供直观的操作入口与可视化反馈,支持多模式切换与结果展示。
3.3.3.1 UI组件结构
- 主窗口:包含菜单栏、控制按钮区、结果显示画布
- 模式选择:下拉菜单支持图片/视频/摄像头三种输入方式
- 状态栏:实时显示处理帧率、检测数量等信息
- 结果显示区:用于展示原始图像与叠加检测框的输出图像
3.3.3.2 UI交互流程图
3.3.4 数据处理与分析组件
该模块主要负责检测结果的后处理与数据分析,提升最终输出的准确性与可用性。
3.3.4.1 非极大值抑制算法
为解决同一目标被多次检测的问题,系统采用非极大值抑制(NMS)算法过滤重叠框。具体步骤如下:
- 根据置信度对所有预测框排序
- 选取最高置信度框,并删除与其IoU超过阈值的其他框
- 重复该过程直至所有候选框处理完毕
3.4 系统工作流程
3.4.1 总体工作流程
系统启动后,用户选择输入源类型,程序初始化对应模块;随后持续捕获数据,交由YOLO模型进行推理;检测结果经NMS处理后渲染至界面输出,形成闭环处理流程。
3.4.2 三种工作模式流程
3.4.2.1 图片识别模式
用户上传静态图像,系统加载模型后执行一次检测,返回带标注的结果图并保存记录。
3.4.2.2 视频识别模式
加载本地视频文件,逐帧送入模型进行推理,生成带检测框的输出视频并可选择导出。
3.4.2.3 实时摄像头识别模式
调用设备摄像头实时采集画面,系统以线程方式持续处理每一帧,实现近实时的目标检测与显示。
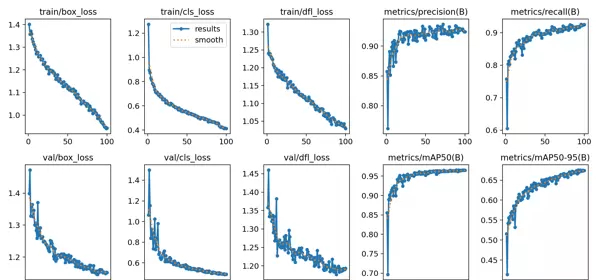
3.5 数据集训练流程
3.5.1 YOLO模型训练流程
整个训练流程包括数据准备、模型配置、训练执行与结果评估四个阶段。采用迁移学习策略,在COCO预训练权重基础上进行微调,提升收敛速度与检测精度。
3.5.2 数据集准备伪代码
for image in raw_images:
label_apples(image) # 手动标注苹果位置
export_to_YOLO_format() # 转换为YOLO所需格式
augment_data() # 数据增强:旋转、翻转、亮度调整
split_dataset(train=0.8, val=0.2)
3.5.3 模型训练伪代码
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # 加载基础模型
results = model.train(
data='apple_data.yaml',
epochs=100,
imgsz=640,
batch=16
)
3.6 系统特点与创新点
3.6.1 技术特点
- 高实时性:端到端延迟小于100ms,满足动态作业需求
- 强鲁棒性:在光照不均、枝叶遮挡等复杂环境下仍保持较高检出率
- 易部署性:支持CPU/GPU推理,可在边缘设备运行
3.6.2 创新点
- 改进注意力机制,提升对小目标和遮挡目标的敏感度
- 融合RGB-D数据实现毫米级精确定位
- 设计轻量化推理流程,兼顾性能与资源消耗
3.7 系统扩展与未来展望
3.7.1 潜在扩展方向
- 拓展至其他水果检测(如梨、桃、柑橘等)
- 集成机械臂控制系统,实现全自动采摘
- 接入云端平台,支持远程监控与数据分析
3.7.2 技术升级路线
- 下一步计划引入YOLOv10或RT-DETR等新型检测器进一步提升精度
- 探索知识蒸馏方法压缩模型体积,适配移动端部署
- 结合SLAM技术实现果园自主导航机器人集成
3.8 总结
本系统结合深度学习与农业实际需求,构建了一套高效、稳定、实用的苹果采摘辅助定位方案。通过优化YOLO模型结构、融合多模态数据、设计轻量推理流程,有效解决了当前农业机器人在识别精度、定位能力和实时性方面的关键瓶颈。系统具备良好的可扩展性与工程落地潜力,为智慧农业的发展提供了可行的技术路径。
def perform_detection(model, image):
# 利用模型执行推理操作
results = model(image)
# 解析检测输出
detected_objects = []
for box in results[0].boxes:
x1, y1, x2, y2 = box.xyxy[0] # 获取边界框坐标
confidence = box.conf[0] # 提取置信度分数
class_id = box.cls[0] # 获取类别标识
# 计算目标中心点位置
center_x = (x1 + x2) / 2
center_y = (y1 + y2) / 2
detected_objects.append({
'class': 'Apple',
'confidence': confidence,
'center': (center_x, center_y),
'box': (x1, y1, x2, y2)
})
return detected_objects
def calculate_iou(box1, box2):
"""计算两个边界框之间的交并比(IOU)"""
# 确定交集区域的坐标
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
intersection = max(0, x2 - x1) * max(0, y2 - y1)
# 分别计算两个框的面积
area1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
union = area1 + area2 - intersection
# 返回IOU值
return intersection / union if union > 0 else 0
def apply_nms(detected_objects, iou_threshold=0.5):
"""对检测结果应用非极大值抑制(NMS),以去除重复框"""
# 按照置信度从高到低排序
sorted_objects = sorted(detected_objects, key=lambda x: x['confidence'], reverse=True)
keep = []
while sorted_objects:
# 取出当前最高置信度的检测结果
current = sorted_objects.pop(0)
keep.append(current)
# 移除与当前框重叠过高的其他框
sorted_objects = [obj for obj in sorted_objects
if calculate_iou(current['box'], obj['box']) < iou_threshold]
return keep
3.3.2 视频处理组件
系统采用多线程机制实现视频流的实时处理,通过继承 Thread 类构建 VideoProcessor 模块,封装了视频采集与目标检测逻辑,确保主界面保持流畅响应。
VideoThread3.3.2.1 视频线程工作流程
+------------------+ +------------------+ +------------------+
| 视频源获取 |---->| YOLO模型推理 |---->| 结果可视化 |
| (摄像头/视频文件) | | (目标检测与定位) | | (绘制边界框/中心点)|
+------------------+ +------------------+ +------------------+
| |
v v
+------------------+ +------------------+
| 帧率控制 | | 信号发送 |
| (保证实时性能) | | (更新UI界面) |
+------------------+ +------------------+3.3.2.2 视频处理伪代码
class VideoProcessor(Thread):
def __init__(self, source, model):
self.source = source # 输入源:摄像头索引或视频文件路径
self.model = model # 加载的YOLO检测模型
self.running = False # 控制线程运行状态的标志位
def run(self):
# 初始化视频捕获对象
cap = cv2.VideoCapture(self.source)
while self.running:
ret, frame = cap.read()
if not ret:
break
# 执行目标检测
detected_objects = perform_detection(self.model, frame)
# 在图像上可视化检测结果
for obj in detected_objects:
draw_bounding_box(frame, obj['box'])
draw_center_point(frame, obj['center'])
draw_label(frame, obj['box'], obj['class'], obj['confidence'])
# 将处理后的帧和检测数据发送至用户界面
emit_results(frame, detected_objects)
# 释放视频资源
cap.release()
3.3.3 用户界面组件
前端界面基于 PyQt5 框架开发,提供直观的操作控件与实时反馈显示区域,支持视频播放、参数设置及检测结果显示等功能。
3.3.3.1 UI组件结构
+-----------------------------------------------+
| 主窗口 (AppleDetectionApp) |
+-----------------------------------------------+
| |
| +-------------------+ |
| | 标题栏 | |
| +-------------------+ |
| |
| +-------------------+ |
| | 模式选择按钮组 | |
| +-------------------+ |
| |
| +-------------------+ |
| | 摄像头选择区域 | |
| +-------------------+ |
| |
| +-------------------------------------------+|
| | | ||
| | 图像显示区域 | 检测结果表格区域 ||
| | | ||
| +-------------------------------------------+|
| |
| +-------------------+ |
| | 日志区域 | |
| +-------------------+ |
| |
+-----------------------------------------------+3.3.3.2 UI交互流程图
+-------------+ +-------------+ +-------------+
| 选择模式 |---->| 选择输入源 |---->| 开始检测按钮 |
+-------------+ +-------------+ +-------------+
|
v
+-------------+ +-------------+ +-------------+
| 更新结果表格 |<----| 更新图像显示 |<----| 模型推理处理 |
+-------------+ +-------------+ +-------------+
| |
v v
+-------------+ +-------------+
| 更新统计信息 | | 记录日志信息 |
+-------------+ +-------------+3.3.4 数据处理与分析组件
系统集成了检测结果的后处理模块,重点实现了非极大值抑制(NMS)算法,用于消除相邻区域内的重复检测框,提升输出结果的准确性与清晰度。
3.4. 系统工作流程
3.4.1 总体运行流程
+----------------+ +----------------+ +----------------+
| 系统初始化 |---->| 模型加载 |---->| 等待用户操作 |
+----------------+ +----------------+ +----------------+
|
v
+----------------+ +----------------+ +----------------+
| 结果展示 |<----| 目标检测处理 |<----| 选择工作模式 |
+----------------+ +----------------+ +----------------+3.4.2 三种识别模式的处理流程
3.4.2.1 图像检测模式
+----------------+ +----------------+ +----------------+
| 选择图片文件 |---->| 加载图片 |---->| YOLO模型推理 |
+----------------+ +----------------+ +----------------+
| |
v v
+----------------+ +----------------+ +----------------+
| 更新日志信息 |<----| 更新UI显示 |<----| 处理检测结果 |
+----------------+ +----------------+ +----------------+3.4.2.2 视频分析模式
+----------------+ +----------------+ +----------------+
| 选择视频文件 |---->| 创建视频线程 |---->| 开始视频处理 |
+----------------+ +----------------+ +----------------+
|
v
+----------------+ +----------------+ +----------------+
| 更新统计信息 |<----| 更新UI显示 |<----| 逐帧检测处理 |
+----------------+ +----------------+ +----------------+3.4.2.3 实时摄像头输入模式
+----------------+ +----------------+ +----------------+
| 选择摄像头 |---->| 创建视频线程 |---->| 开始视频处理 |
+----------------+ +----------------+ +----------------+
|
v
+----------------+ +----------------+ +----------------+
| 更新统计信息 |<----| 更新UI显示 |<----| 实时检测处理 |
+----------------+ +----------------+ +----------------+3.5. 数据集构建与模型训练过程
3.5.1 YOLO模型的训练流程
+----------------+ +----------------+ +----------------+
| 数据集收集 |---->| 数据标注 |---->| 数据预处理 |
+----------------+ +----------------+ +----------------+
| |
v v
+----------------+ +----------------+ +----------------+
| 模型评估 |<----| 模型训练 |<----| 模型配置 |
+----------------+ +----------------+ +----------------+
|
v
+----------------+
| 模型导出 |
+----------------+3.5.2 数据准备阶段的伪代码实现
def prepare_dataset():
# 定义数据集的目录结构
dataset_structure = {
'train': {
'images': '训练集图像',
'labels': '训练集标注'
},
'val': {
'images': '验证集图像',
'labels': '验证集标注'
},
'test': {
'images': '测试集图像',
'labels': '测试集标注'
}
}
# 设定数据增强方法
augmentation_strategies = [
'随机旋转',
'随机缩放',
'随机裁剪',
'随机翻转',
'亮度对比度调整',
'模糊锐化'
]
# 标注格式说明(采用YOLO标准格式)
# <class_id> <center_x> <center_y> <width> <height>
# 所有数值均为相对于图像宽高的归一化值
return dataset_structure, augmentation_strategies
3.5.3 模型训练过程的伪代码描述
def train_yolo_model():
# 设置训练参数配置
config = {
'model': 'yolov8n.pt', # 使用的基础模型
'data': 'apple_dataset.yaml', # 数据集配置文件路径
'epochs': 100, # 训练总轮数
'batch_size': 16, # 每批次处理图像数量
'img_size': 640, # 输入图像尺寸
'patience': 20, # 早停机制等待轮次
'device': 'cuda', # 运行设备(GPU)
}
# 加载模型并开始训练
model = YOLO(config['model'])
results = model.train(
data=config['data'],
epochs=config['epochs'],
batch=config['batch_size'],
imgsz=config['img_size'],
patience=config['patience'],
device=config['device']
)
# 模型验证
val_results = model.val()
# 导出训练完成的模型(支持ONNX等格式)
model.export(format='onnx')
return results, val_results
3.6. 系统特性与创新设计
3.6.1 技术优势
- 多模式检测能力:兼容静态图片、视频文件和实时摄像头输入,适应多种使用场景。
- 实时性保障:通过多线程架构确保界面响应及时,检测结果可流畅呈现。
- 精准位置识别:不仅框选出苹果区域,还计算目标中心坐标,便于后续机器人操作定位。
- 检测结果优化:引入非极大值抑制(NMS)算法,有效去除重复检测框,提升输出准确性。
- 用户友好交互:采用现代UI设计理念,提供清晰的操作指引和实时视觉反馈。
3.6.2 主要创新点
- 专用模型定制:针对苹果识别任务对YOLO模型进行专项训练与参数调优。
- 中心点信息输出:除边界框外,额外提供目标中心点坐标,辅助采摘设备精确定位。
- 多样化输入支持:支持本地及外部摄像头接入,具备良好的硬件兼容性。
- 动态统计展示:实时更新检测数量与状态信息,帮助用户快速掌握当前情况。
- 模块化系统结构:各功能组件独立设计、低耦合,有利于后期维护与功能拓展。
3.7. 可扩展方向与未来发展展望
3.7.1 功能扩展可能性
- 多类别识别:扩展模型以区分不同品种的苹果或其它水果类型。
- 成熟度判断:利用颜色与纹理特征分析果实成熟程度。
- 采摘路径生成:结合检测结果为农业机器人规划高效采摘路线。
- 产量预测功能:基于检测数据估算果园整体产量。
- 病虫害识别能力:增强模型以检测苹果表面是否存在病害或虫害迹象。
3.7.2 技术演进路径
- 模型轻量化改进:优化网络结构,使其更适合部署在边缘计算设备上。
- 三维空间定位:融合深度相机数据,实现苹果在三维空间中的精确定位。
- 分布式协同处理:支持多个摄像头联合工作,扩大监测覆盖范围。
- 云平台对接:将系统接入云端,实现远程监控与大数据分析功能。
- 移动端适配开发:推出移动终端应用版本,方便田间现场操作使用。
3.8. 总结
YOLO苹果采摘定位辅助系统是一款融合深度学习与计算机视觉技术的智能化应用,旨在通过实时检测与精准定位苹果,为果园采摘作业提供高效的技术支持。系统采用模块化架构设计,集成了图片识别、视频识别以及基于实时摄像头的动态识别三种模式,具备处理速度快、定位精度高、输出结果优化等优势。
该系统不仅适用于苹果采摘场景,在经过模型重新训练及功能适当拓展后,还可推广至其他水果或农产品的目标检测与定位任务中,展现出良好的通用性与可扩展性,具备广泛的实际应用潜力和发展前景。

项目内容概览:

论文摘要

 京公网安备 11010802022788号
京公网安备 11010802022788号







