


 雷达卡
雷达卡



本文介绍了一种创新的机器人仿真方法,将 3D Gaussian Splatting 技术集成至主流的向量化物理模拟器中,作为其原生渲染模块。该方案在保持极高模拟速度的同时,实现了出色的视觉保真度——在消费级 GPU 上可达到每秒超过 10 万次模拟步长,画面质量接近真实世界拍摄效果。这一技术被成功应用于“仿真到现实”(sim-to-real)的机器人任务中,验证了其策略迁移的有效性。
所提出的方法不仅支持基于深度信息的感知能力,还能充分利用丰富的视觉语义线索,例如识别需绕行的区域或可交互物体,从而显著增强机器人的环境理解、导航规划与决策水平。它能够高效融合多种来源的数据,快速构建高保真的训练场景,包括使用 iPhone 扫描生成的 3D 环境、大规模室内场景数据集(如 GrandTour),以及由生成式视频模型输出的动态视频内容。通过此方式,GaussGym 在高通量模拟与高质量视觉感知之间建立了有效连接,为可扩展、可泛化的机器人学习提供了新的可能性。

要在非结构化的真实环境中(如家庭、街道、办公室等复杂多变空间)实现自主移动,机器人必须具备精确且语义丰富的环境感知能力。文章聚焦于一个典型任务:引导移动机器人前往指定目标位置。在此过程中,机器人需完成两项核心操作:一是安全避障与路径规划,二是与人造物体进行合理交互。
然而,许多关键障碍物和功能性环境特征无法仅靠激光雷达识别。例如,在城市街道或办公场所中执行送货或巡检任务时,机器人不仅要感知距离(“前方有物体”),更需要“理解”场景内容。像人行道边界、积水区域、红绿灯状态、按钮位置等重要导航线索,本质上依赖颜色、纹理和形状等视觉特征,这些信息难以通过传统测距传感器获取。若缺乏对这类视觉语义的理解,机器人即便能避开障碍,也无法做出符合情境的智能行为。
当前腿式机器人运动控制研究普遍采用 sim-to-real 强化学习范式,即先在虚拟环境中训练控制策略,再将其直接部署到真实机器人上,期望实现无需额外调参的鲁棒运行。尽管现有仿真平台在物理建模方面已相当成熟(如准确模拟重力、摩擦、关节动力学),并能成功完成策略迁移,但在视觉仿真环节仍存在明显短板。
主要问题在于:要么渲染速度过慢,严重拖累训练效率;要么图像逼真度不足,导致虚拟与现实之间的视觉差异过大。由于这一局限,大多数依赖感知的移动系统被迫放弃使用 RGB 摄像头,转而采用激光雷达或深度相机等简化感知方案。这类传感器仅提供几何层面的距离与轮廓信息,使机器人只能知道“前方10米有个障碍”,却无法判断其本质是水坑、草地还是易碎纸箱——而这些语义差异恰恰决定了应采取的不同应对策略(绕行、缓行或避让)。这也限制了可模拟任务的复杂度,诸如“走向那扇开着的门”这类高度依赖视觉语义的任务难以在传统仿真中实现。
为此,本文推出了 GaussGym——一个开源的仿真框架,利用前沿图形学技术 3D Gaussian Splatting,将现实世界扫描或 AI 生成的视频内容数字化,构建出既满足高精度物理模拟又具备照片级真实感的虚拟环境。其核心目标是使机器人能够直接从标准 RGB 相机输入中学习行走与导航策略,摆脱对低维传感器的依赖。
该框架建立在 3D 重建与可微分渲染的基础之上,支持导入多种异构数据源,包括智能手机三维扫描、手持设备录制视频、公开 3D 场景数据集以及生成式模型合成的动态视频序列。实验表明,GaussGym 具备卓越性能:在单张 RTX 4090 消费级显卡上,可同时运行 4096 个并行仿真实例,每个实例均能提供分辨率为 640×480 的高质量视觉输出,极大提升了强化学习训练的数据吞吐能力。
为了验证 GaussGym 在训练“视觉-运动”策略方面的能力,研究者针对双足(类人)和四足(如狗形)机器人设计并训练了移动与导航策略。尽管 GaussGym 具备更高的仿真速度和更逼真的画面表现,但从原始 RGB 像素中直接学习仍面临巨大挑战。这是因为策略网络必须从二维图像中自行推断出三维空间结构信息——例如地面高度、障碍物形态等,而无法像传统方法那样依赖已有的深度图或高程图作为输入。
为此,作者引入了一种辅助的几何重建损失函数。在仿真过程中,系统可访问场景的真实三维模型(ground truth meshes),并要求策略网络在控制机器人运动的同时,额外完成对所见场景几何结构的重建任务。这一附加目标起到了类似“教师信号”的作用,促使网络更加关注环境中的空间结构特征,从而显著提升了学习效率与最终性能。
实验进一步表明,仅在 GaussGym 中基于纯视觉输入训练出的策略,无需任何真实机器人上的微调,即可成功部署于实体机器人进行楼梯攀爬测试,并取得初步成果。这标志着在缩小视觉仿真与现实之间差距的方向上迈出了关键一步。同时,GaussGym 降低了高保真仿真技术的应用门槛,为未来视觉驱动的移动与导航研究提供了坚实平台。
本文主要贡献包括:
- GaussGym:一个快速且开源的仿真平台,集成了多达 2500 个多样化场景。这些场景来源于人工扫描数据、公开数据集以及生成式视频模型重建,实现了视觉丰富性与几何准确性的结合。
- 提出将几何结构重建作为辅助学习任务,有效缓解视觉 sim-to-real 转移难题,显著提升机器人在复杂地形(如楼梯)上的通行能力。
- 通过“到达指定目标点”任务验证:仅基于 RGB 图像训练的导航策略展现出一定的语义理解能力。它能够主动避开某些视觉上“不适宜通行”的区域(如地毯边缘、反光地板),而这类信息对于仅依赖深度感知的策略而言是完全不可见的。
相关工作
面向移动任务的仿真到现实迁移强化学习
仿真环境为强化学习在机器人移动与导航策略训练中的应用提供了一个高效且低成本的途径。相比真实世界的数据采集,仿真避免了昂贵的硬件损耗和潜在的安全风险,同时支持大规模并行试验。理想的仿真器应具备三大核心特性:高物理精度、快速计算通量以及逼真的图形渲染能力。
早期的仿真工具(如 MuJoCo、PyBullet)基于 CPU 实现刚体动力学模拟,首次验证了“仿真训练—现实部署”路径的可行性。然而,受限于串行计算架构,其训练效率难以满足现代强化学习对海量样本的需求。随着 GPU 加速仿真技术的发展(如 Isaac Gym),大规模并行化成为可能。研究人员得以在消费级显卡上同时训练成千上万个智能体实例,极大推动了腿式机器人控制与自主导航算法的进步。
尽管当前主流框架已支持硬件加速的并行物理与渲染,但在实际应用中,成功落地的移动策略大多仍依赖以下两类输入:
- 几何感知信息:如深度图、高程图
- 本体感觉信号:如关节角度、躯干姿态
主要原因在于:现有仿真器生成的图像在纹理、光照、材质等方面与真实世界存在明显差异,导致基于仿真视觉训练的策略难以泛化至真实摄像头输入。此外,大多数仿真平台缺乏足够多样且高保真的 3D 场景模型。虽然高画质渲染能提升视觉真实性,但通常伴随高昂的计算成本,无法满足强化学习所需的高速模拟节奏。
近年来,隐式场景表示方法(如 3D Gaussian Splatting, 3DGS)为解决上述矛盾提供了新思路。该类技术既能生成接近照片级的真实感图像,又可在 GPU 上实现极高速渲染,兼顾了视觉保真度与计算效率,成为构建下一代视觉仿真系统的有力候选。
场景生成方法
目前主流的场景构建方式主要包括程序化生成、资产库导入、视频重建与真实扫描等路径。
程序化地形生成利用预设规则或随机算法创建复杂几何结构(如台阶、斜坡阵列),被广泛用于提升机器人应对极端地形的鲁棒性。但此类方法仅能定义形状,无法赋予场景真实的视觉外观,导致生成环境呈现为无纹理的抽象几何体,缺乏现实世界的视觉多样性。
另一种方案是从高质量 3D 资产库中导入带纹理模型来搭建场景,如 ReplicaCAD 和 AI2-THOR 等平台提供的精细室内布局。虽然能获得较高建模质量,但其构建过程耗时费力,扩展性和灵活性受限。
有研究尝试从视频序列中重建动态场景用于训练,但往往放弃重新渲染 RGB 图像,转而仅使用提取的几何信息进行策略学习。这反映出在保持高视觉保真度的前提下实现实时渲染的技术瓶颈。
使用专业设备对真实空间进行三维扫描后导入仿真,虽能获取最贴近现实的环境数据,但流程繁琐、成本高昂,不适合大规模部署。总体来看,多数现有方法依赖传统的基于纹理网格的渲染管线,常导致视觉细节缺失、材质失真等问题,限制了其在视觉主导型任务中的应用潜力。
近年来,辐射场技术(如NeRF和3DGS)在机器人领域展现出巨大潜力。NeRF作为一种从图像中重建高质量3D场景的先进方法,能够生成极为逼真的视觉效果,并已在多个维度上取得显著进展——包括重建质量、适用规模、处理速度以及对动态场景的支持。最初被应用于高精度抓取任务后,由于其具备嵌入语言等高维语义特征的能力,NeRF逐渐被拓展至语言引导的操作任务中。然而,其训练与渲染过程计算开销大、速度缓慢,严重限制了其在机器人仿真中的广泛应用。
作为NeRF的一种高效替代方案,3D高斯泼溅(3DGS)不再依赖复杂的神经网络进行场景建模,而是采用一组带有方向性的3D高斯椭球集合来表示空间内容。这种显式表达方式支持现代GPU上的可微分光栅化操作,实现了极快的渲染速度。同时,许多研究已成功将NeRF的高级特性(如语义场、语言对齐)迁移到3DGS框架下,应用于语言驱动的抓取、长期交互任务以及视觉模仿学习等场景。
辐射场不仅可用于高保真视觉重建,还在多个机器人应用中发挥作用:例如用于可微碰撞检测以辅助导航;作为视觉模拟器支持基于RGB像素输入的无人机飞行或自动驾驶策略学习;亦或作为多视角增强的场景表征,训练运动“功能可供性”模型。这些成果为GaussGym的设计提供了重要启发。
GaussGym融合了IsaacSim提供的精确接触级物理模拟与基于3DGS的高真实感视觉模拟,构建了一个完整的“视觉-物理”协同仿真系统,专注于实现端到端的机器人运动控制策略训练。该系统直接从像素输入生成动作指令,在保证高度真实感的同时,达成前所未有的模拟效率。
与现有工作相比,GaussGym在三个方面实现了关键突破:
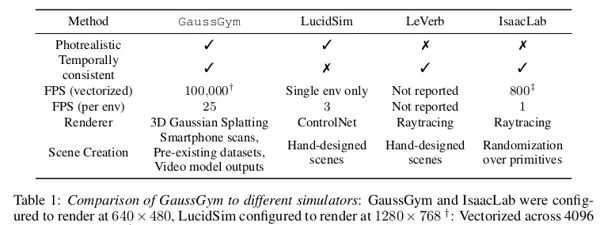
- 卓越的可扩展性:系统架构支持快速集成数千个真实扫描场景,而类似系统如LucidSim通常仅限于少量特定测试环境。
- 深度集成大规模并行物理引擎:通过与IsaacGym等高性能物理仿真平台紧密耦合,GaussGym可同时运行数千个机器人实例,极大加速强化学习训练流程。
- 面向未来研究的开放框架设计:作为一个灵活、开源的基础平台,GaussGym旨在服务于整个学术社区,鼓励后续扩展与创新,而非仅展示单一研究成果。
当前一些前沿的生成式视频模型虽能根据文本提示生成逼真且多视角一致的视频内容,为大规模3D资产创建带来革命性可能,但其推理速度极慢,难以直接用于实时仿真。而GaussGym恰好可以接收这类模型输出的视频序列作为输入源,将其转化为可交互、可物理响应的仿真环境,从而有效架起“生成内容”与“实际仿真”之间的桥梁。
此外,Zhu等人曾利用多个场景的3DGS构建高层级视觉导航策略;另有研究尝试使用3DGS建模关节式物体结构,或用于预测物体URDF参数及进行物体参数估计。这些工作共同验证了3DGS在机器人学中的实用价值。相比之下,GaussGym的核心贡献在于将3DGS深度整合进物理仿真流程,首次实现从原始像素到动作执行的端到端策略训练,并达到工业级模拟速度。
值得一提的是,LucidSim也提出了一个结合3DGS的“真实到仿真”框架,主要贡献包括:
- 利用ControlNet从深度图和语义掩码生成增强视觉数据,提升数据多样性;
- 借助Polycam生成的网格手动对齐坐标系,完成真实与仿真的映射。
尽管如此,GaussGym在自动化程度、扩展能力和物理集成方面均实现了超越。
本方法继承自NeRF2Real的思想,后者通过NeRF捕获场景以提升视觉保真度,再经由网格提取和人工后处理来训练移动策略。但由于光线追踪效率低下,无法在GPU上对大量环境进行并行模拟,导致整体计算成本过高。GaussGym则从根本上解决了这一瓶颈。
GaussGym 系统流程
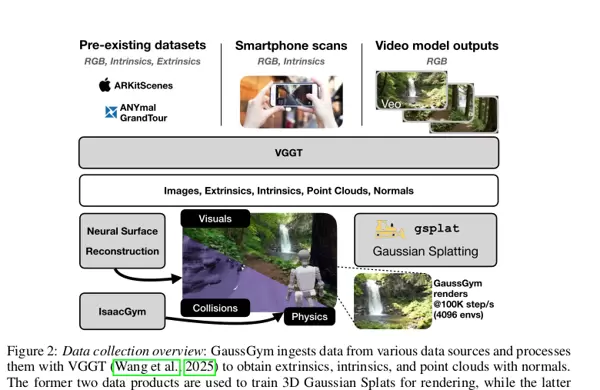
如图所示,GaussGym支持多种输入形式,包括带位姿标注的数据集、智能手机扫描结果或由视频生成模型输出的RGB图像序列。所有输入均通过VGGT网络进行标准化处理,统一估计相机内参、外参、密集点云及表面法线信息。
为了构建完整的仿真环境,GaussGym采用双路径策略生成所需的3D资产:
- 路径一:网格生成 —— 原始数据首先生成中间几何表示,随后送入神经表面重建模块,产出可用于物理仿真的三角网格。此类网格为物理引擎提供明确的表面定义,是实现精准碰撞检测的关键基础。
- 路径二:高斯泼溅生成 —— 利用VGGT输出的点云直接初始化3D高斯集合。得益于3DGS本身极快的训练收敛速度,该路径可在短时间内优化出外观高度真实的渲染模型。
两条路径所产生的资产——即用于物理交互的网格与用于视觉呈现的高斯表示——会被自动对齐至同一全局坐标系下。这一机制确保了机器人“所见”(由高斯渲染生成的画面)与其“所感”(由网格计算的物理接触)在空间上完全同步,构成了高真实感仿真的核心保障。
在运行时,高斯泼溅作为“即插即用”的视觉组件,提供逼真的感官输入,并支持大规模并行渲染;物理引擎则负责处理重力、摩擦、动力学演化和碰撞响应。两者始终保持时间与空间的一致性。这种精巧的设计使GaussGym能够无缝整合多样化的现实世界数据与合成数据源,既发挥3DGS的速度优势,又满足大规模机器人学习的需求。

GaussGym 具备高度灵活的设计,能够从多种不同的数据源中获取输入信息。这些数据源包括带有位姿标注的数据集(例如 ARKitScenes 和 GrandTour)、经内参标定的智能手机拍摄图像,甚至可以是不包含位姿信息的视频生成模型所产生的 RGB 图像序列。
无论原始数据来自手机扫描、视频流还是公开数据集,在进入处理流程前都会被统一转换至一个重力对齐的坐标系中。这一标准化步骤是实现全流程自动化的基础,确保了不同来源的数据能够在一致的空间框架下进行处理。系统采用 VGGT 技术来提取相机的内参与外参,并生成密集的场景表征,如点云和法线图等。
随后,处理流程分叉为两个并行分支,分别用于构建物理仿真与视觉渲染所需的资产:
- 物理碰撞用网格:基于 VGGT 输出的结果,利用神经核表面重建(NKSR)技术生成高质量三维网格。该网格将作为物理引擎中的碰撞体,支撑精确的力学交互。
- 视觉渲染用高斯溅射:直接使用 VGGT 生成的点云初始化 3D 高斯分布。这种方式不仅显著提升了几何保真度(因点云源自真实观测,结构准确),还加快了训练过程中的收敛速度。
通过上述自动化管线,GaussGym 实现了视觉渲染结果(来自 3D 高斯)与物理碰撞体(来自重建网格)在空间几何上的一致性匹配。这种一致性对于可靠的物理仿真至关重要——机器人“看到”的物体轮廓必须与其实际“碰撞”到的形状完全吻合。
相较于目前最接近的相关工作 LucidSim,GaussGym 在以下三个方面实现了关键性提升:
- 更广泛的数据兼容性:LucidSim 仅支持智能手机扫描数据;而 GaussGym 可处理多样化的输入源,涵盖生成视频、专业数据集及移动设备采集内容。
- 更高的自动化程度:LucidSim 要求人工干预完成网格与 3DGS 模型的配准对齐;GaussGym 则实现了全自动对齐,为大规模场景扩展提供了可行性。
- 更强的性能表现:LucidSim 缺乏向量化渲染能力(即无法并行处理成千上万个环境实例);而 GaussGym 原生支持向量化渲染架构,极大提升了模拟效率与吞吐量。
3DGS 作为即插即用渲染器
在场景构建完成后,GaussGym 使用已重建的 3D 高斯进行光栅化操作,即将三维空间中的高斯椭球投影为二维屏幕像素图像。相比传统图形学方法,该技术能以极低计算成本实现照片级画质输出。更重要的是,它并非逐个环境顺序渲染,而是支持数千个环境的同步并行渲染,天然适配 GPU 的大规模并行计算特性,从而保障了极高的渲染效率与强化学习训练速度。
作者借助 PyTorch 的多线程内核对所有环境中的高斯参数进行批量处理,充分挖掘 GPU 计算潜力,同时支持分布式训练架构下的高效扩展。
为了进一步提升效率并缩小仿真与现实之间的差距,GaussGym 引入了两项关键技术策略:
- 渲染与控制频率解耦:避免以高频控制器更新速率进行实时图像渲染,转而采用接近真实摄像头帧率(如 30 或 60 FPS)进行视觉输出。由于物理引擎和机器人控制器通常运行在数百乃至上千赫兹的高频率下,若每一步都渲染一帧图像,将产生大量视觉冗余帧,造成严重计算浪费。通过降低渲染频率,系统在保持高保真视觉反馈的同时大幅提升整体效率。
- 运动模糊模拟:引入一种新颖的方法合成逼真的运动模糊效果,增强策略在面对快速运动时的鲁棒性。真实摄像头在曝光过程中若存在相对运动,会自然形成模糊现象。传统仿真器往往输出“绝对清晰”的图像,导致与真实画面之间出现域差异。GaussGym 根据相机的运动轨迹,在路径上生成一组轻微偏移的中间视图,并通过 AlphaBlend 方式按透明度叠加融合,最终生成一张具有真实感模糊伪影的图像。
这一机制不仅提高了视觉的真实性,使渲染画面更贴近真实摄像机拍摄结果,也增强了策略迁移能力——在训练阶段就接触模糊图像,使得模型在部署到真实世界后,面对因高速运动或机械震动引起的模糊仍能稳定运行。尤其在剧烈动态场景中(如爬楼梯时的颠簸或高速巡检任务),运动模糊尤为显著,因此该优化对复杂任务的成功执行具有决定性意义。
超越现实的训练环境
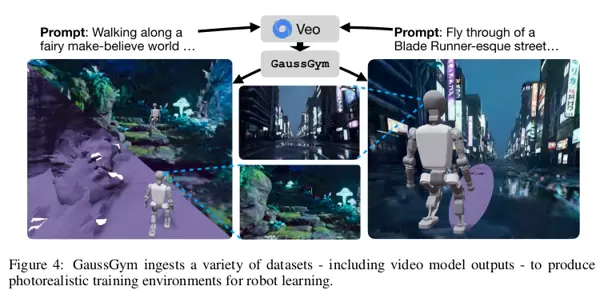
GaussGym 不仅可用于数字化现实空间(如通过手机扫描建模),其最具突破性的能力在于能够利用 Veo 等生成式视频模型创建全新的视频内容,并据此构建现实中难以获取或根本无法拍摄的环境类型,例如洞穴内部、灾难废墟或外星地貌。
其实现核心依赖于两大技术支撑:一是 Veo 模型具备出色的多视角一致性生成能力;二是 VGGT 工具可以从无位姿标签的生成视频中准确估计相机参数,并恢复出高质量的密集点云结构,从而构建可用于仿真的三维场景。
视觉驱动的运动与导航
为验证 GaussGym 所提供照片级渲染的真实价值,研究人员选取了“视觉引导的楼梯攀爬”与“复杂地形下的视觉导航”作为典型测试任务。在方法设计上,他们有意采用了更具挑战性的端到端单阶段训练范式,而非依赖中间监督或简化流程的“师生蒸馏”策略,旨在直接证明从原始像素输入到动作输出的完整学习路径的有效性。
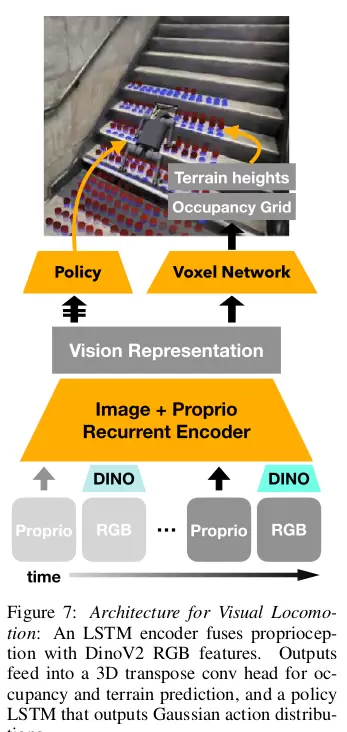
本框架的核心是一个循环编码器,作为系统的主要结构组件。其关键功能在于融合来自视觉与本体感觉的多模态信息,并捕捉这些信息随时间演变的动态特性。出于在真实机器人平台上实现高效推理的实际需求,该架构选用了LSTM而非当前主流的Transformer结构。
输入信号由两个独立的数据流构成:一是来自摄像头的原始RGB图像,代表外部环境的视觉感知;二是机器人自身传感器采集的本体感觉数据,如关节角度、电机扭矩以及身体姿态等内部状态信息。
由于原始像素数据维度高且存在大量冗余,不会被直接送入网络处理。取而代之的是,RGB图像首先通过一个强大的预训练视觉模型——DinoV2,将其转化为一个高度压缩但语义丰富的数学向量(即嵌入表示)。这一步相当于将复杂的视觉场景提炼为一段包含关键语义的描述性特征。
随后,将上述生成的视觉嵌入?与当前时刻的本体感觉测量值?进行拼接,形成一个联合特征向量。该向量作为输入传递给LSTM单元。得益于LSTM的“记忆”机制,它不仅能响应当前输入,还能保留并利用历史信息,从而有效建模时序依赖关系。最终输出的是一个紧凑的潜在表示,综合了过往的视觉语义和本体感觉状态,构成了对当前整体环境与机器人自身状态的高度抽象概括。
尽管Transformer在诸多AI任务中表现出色,作者仍选择LSTM,主要基于实际部署中的推理速度要求,强调实时性与效率。
在此共享编码器生成的潜在表示基础上,网络分出两个并行的任务头,分别承担不同职责:
体素预测头:该分支旨在从潜在空间中重建出场景的3D几何结构,包括体素占用情况和地形高度图。这是一个辅助学习任务,目的是促使网络内部表征具备良好的几何理解能力。具体过程是将共享编码器输出的latent表示映射到一个粗粒度的3D网格上,再通过一系列3D转置卷积层逐步上采样,最终生成精细的体素预测结果。这一过程引入了明确的几何归纳偏差,迫使网络关注影响运动的关键空间特征(例如台阶边缘、地面起伏),而非无关的纹理或颜色细节。该任务对应的损失函数被称为辅助重建损失,虽不直接影响控制动作,却显著提升了主任务的表现。
策略头:这是执行主控任务的核心部分,负责输出机器人下一时刻的动作指令,具体表现为各关节的位置偏移量。该模块使用另一个LSTM对共享编码器产生的latent表示及其自身的隐藏状态进行处理,以确保动作序列的时间连续性和一致性。输出结果并非确定性的动作值,而是高斯分布的参数,意味着策略学习的是动作的概率分布。智能体据此采样得到具体的动作指令,这种设计为探索行为和应对不确定性提供了必要空间。
整体架构通过设置辅助任务来监督和优化内部特征表示的质量,从而间接但显著地增强主线控制任务的性能表现。
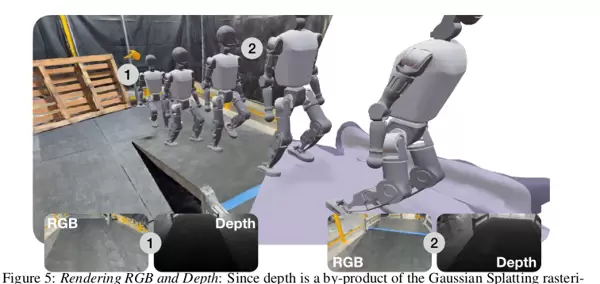
研究人员选取“爬楼梯”作为典型测试任务,用以验证纯视觉驱动策略的有效性。虽然此类任务可通过深度传感器甚至无视觉反馈的方式完成(即“盲爬”),但该实验重点展示的是仅依赖RGB图像所学到的高级行为能力。实验结果显示,基于Unitree A1机器人并在纯视觉条件下训练出的策略,能够精准落脚、自适应调整步态,并且无需任何微调即可直接从仿真环境迁移到真实机器人上成功执行爬楼动作。
在GaussGym仿真平台中,使用RGB图像训练的策略展现出以下能力:
- 精确的脚部放置: 能准确将脚落在台阶表面,避免踢到边缘或踩空。
- 自适应的步态调整: 可动态调节步伐,防止与楼梯竖板发生碰撞。
- 鲁棒的速度跟踪: 即使在复杂地形下也能稳定跟随指定行进速度。
这些行为表明,策略并非简单记忆固定模式,而是真正理解了三维空间结构及其与机器人运动之间的交互逻辑。

在视觉导航任务中,智能体需完成稀疏目标跟踪,即绕过障碍物并抵达远处的目标点。为此,作者构建了一个包含障碍物的测试场地,并设置了一块特殊区域——地板上的黄色斑块作为惩罚区。在训练过程中,若智能体进入该区域,则会受到负奖励信号。
实验对比了两种策略:一种基于RGB图像输入,另一种则依赖深度图输入。

RGB策略成功避开了黄色斑块。这是因为该策略能够识别图像中的颜色和纹理特征,并通过训练建立起“黄色斑块 = 惩罚”的语义关联,从而学会将其视为应避开的危险区域。
相比之下,仅依赖深度信息的策略未能规避该区域,直接穿行而过。因为在几何层面,该区域是一片平坦可通行的空间,没有障碍物阻挡,因此被视为最优路径。这说明纯几何感知无法捕捉基于视觉语义的风险提示。
为了系统评估GaussGym框架中各项设计选择的有效性,作者在四种不同地形场景下(平坦地面、陡坡、低矮楼梯、高楼梯)开展大规模消融实验。结果表明:
- 体素网格回归任务和预训练的DINO视觉编码器均为提升整体性能的关键要素,任意一项的移除都会导致性能明显下降。
- 相较于仅在少量场景中训练,使用多样化场景进行联合训练能显著提高泛化能力,这也凸显了GaussGym支持多场景无缝集成训练架构的技术优势。
尽管GaussGym在视觉策略学习方面取得了显著成果,仿真到现实的迁移仍然是一个尚未完全攻克的核心难题。作者深入分析了当前框架存在的多项局限性,为后续研究提供了清晰的方向指引。这些挑战涵盖了真实硬件部署中的实际困难、高级语义奖励函数的手动设计问题、物理参数设置的单一化、所依赖生成模型的固有缺陷,以及对动态环境和复杂物理现象(如流体、可变形物体)的建模能力不足等。
在仿真环境中,基于视觉的控制策略能够有效识别并避开高代价区域,并实现精确的落脚定位。然而,该策略尚未在未见过的新类型楼梯场景中进行测试,其泛化性能仍有待验证。虽然实现了零样本从仿真到现实的转移,但在真实机器人上的表现显示精度有所下降,例如脚部放置的位置不如仿真中精准,暴露出跨域适应能力的不足。
真实世界中的部署面临诸多固有挑战:
- 物理延迟:真实机器人在图像采集、传输与计算过程中存在延迟,而仿真环境中的响应是即时的,这种时序差异影响了控制的实时性和稳定性。
- 自我中心视角的局限性:机器人依赖的是局部且不断变化的视角,相较于仿真中可能采用的全局观测方式,这一限制增加了感知与决策的难度。
- 与传统方法的对比:在低层级控制任务中,基于高程图构建与高速状态估计的传统几何方法表现出更高的稳定性,这凸显了当前纯视觉策略在鲁棒性方面的差距。
在涉及高阶语义理解的任务中,例如遵循“走人行道”这类体现社交规范的行为,GaussGym尚无法自动构建相应的成本或奖励机制,仍需人工定义相关规则。未来可通过引入基础语言模型来解析自然语言指令,并自动生成与高级语义对齐的奖励函数,从而提升系统的智能化水平。
当前系统还缺乏对物理属性与视觉外观之间关联的建模能力。所有环境资产使用统一的物理参数(如摩擦系数),导致无法表达“看似冰面实则湿滑”或“形似泥潭踩之下陷”这类视觉与物理特性不一致的情况。这种解耦限制了智能体在复杂多变地形中的适应能力。
此外,框架所依赖的生成式模型本身存在若干缺陷:
- 输出不一致性:如Veo等模型生成的内容可能前后矛盾,需反复调整提示以获得稳定结果。
- 视角控制能力弱:仅通过文本难以精确控制生成画面的视角与构图。
因此,集成更先进且可控的世界模型(如Genie 3)成为一条明确可行的优化路径。
当前仿真的能力边界也显而易见:
- 动态场景处理缺失:无法应对包含行人、车辆等移动障碍物的动态环境,限制了其在开放场景中的应用。
- 复杂物理模拟受限:由于底层物理引擎IsaacGym的能力限制,系统尚不能支持流体、沙地、布料等非刚体或连续介质的物理行为模拟。

 京公网安备 11010802022788号
京公网安备 11010802022788号







