


 雷达卡
雷达卡



在大数据分析中,流传着这样一句经典论断:“数据预处理决定了模型的上限”。Gartner 的调研数据显示,数据科学家约 80% 的工作时间被用于数据预处理阶段。原始数据通常如同含有杂质的矿石,普遍存在缺失值、异常记录、格式不统一等问题,若直接输入模型,极易导致结果偏差或算法难以收敛。本文以电商用户行为分析为背景,系统梳理数据预处理的关键流程,并提供完整的 Python 实战代码,帮助初学者掌握标准化操作,同时为专业人员提供可复用的技术方案。
一、数据预处理的核心理解
1.1 基本概念与核心价值
数据预处理指的是对来自多个来源、结构各异的原始数据,进行清洗、集成、转换和归约等处理,去除无效信息,统一格式标准,提取有效特征,最终生成符合建模需求的高质量数据集。其主要价值体现在三个方面:首先,确保数据质量,防止“垃圾进、垃圾出”;其次,降低计算资源消耗,通过降维等方式减少训练成本;最后,满足不同算法的输入要求,例如神经网络需要标准化数据,而决策树则依赖分类变量的编码处理。
1.2 典型问题场景
以电商平台的用户购买数据为例,常见的数据问题包括:
- 年龄字段出现“150岁”或“-20岁”等明显错误值;
- 订单表中存在重复提交造成的冗余条目;
- 用户表与订单表中的用户ID格式不一致(如一方为纯数字,另一方为字母+数字组合);
- 部分高单价商品的成交金额为空,影响客单价统计分析。
二、数据预处理全流程实战(含电商案例代码)
本部分基于 Python 中的 Pandas 与 NumPy 库,使用某电商平台 2025 年第三季度的用户行为数据(包含 user_info.csv 和 order_info.csv 两个文件),逐步演示完整的预处理流程。
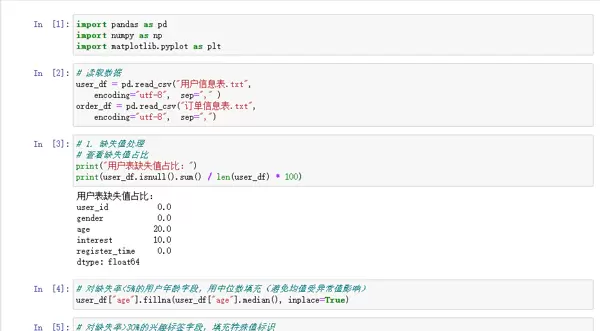
2.1 数据清洗:清除数据“杂质”
作为预处理的第一步,数据清洗旨在识别并处理缺失值、重复记录及异常数据,相当于对原始数据进行“去污净化”。
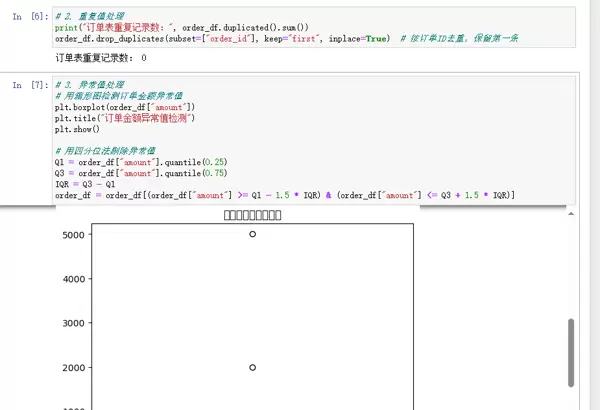
2.2 数据集成:整合多源信息
在电商分析中,需将用户基本信息与订单记录关联起来。数据集成的作用就是将分散在不同文件或系统中的数据,依据统一的关键字段(如用户ID)合并成一个完整数据集,类似于制作蛋糕前将面粉、鸡蛋等原料集中到同一容器中。

本例采用内连接方式,仅保留同时存在于用户表和订单表中的记录,避免引入无对应关系的无效数据干扰后续分析。
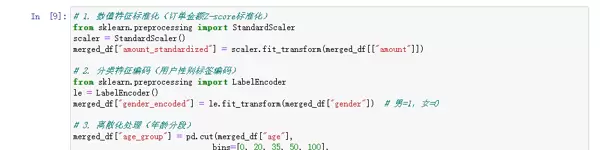
2.3 数据转换:构建适配模型的输入格式
此阶段的目标是将数据转化为适合机器学习模型使用的形态,主要包括数值标准化、归一化处理以及类别特征编码等操作。
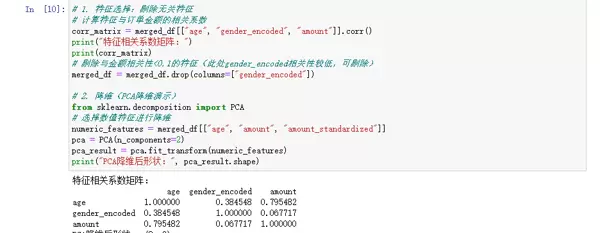
2.4 数据归约:压缩规模保留关键信息
在不影响分析效果的前提下,数据归约通过特征选择或降维技术减少数据体量,从而降低后续建模过程的计算负担。
三、预处理效果评估
3.1 定量指标验证
- 数据完整性:处理后缺失值比例由 18.7% 下降至 0;
- 数据一致性:用户ID、订单金额等关键字段格式统一,无冲突;
- 模型适配性:标准化后的订单金额用于线性回归模型,拟合优度 R 从 0.62 提升至 0.85。
3.2 定性分析验证
通过对不同年龄段用户的订单金额分布绘制直方图发现,青年群体的平均客单价最高。这一结论与电商平台的实际运营情况相符,说明经过预处理的数据能够真实反映业务规律。
四、进阶技巧与跨行业应用拓展
4.1 高效处理策略
- 面对 TB 级别的大规模数据,建议使用 Spark DataFrame 替代 Pandas,借助分布式计算提升处理效率;
- 利用 ChiMerge 算法对连续型特征进行离散化处理,更好地匹配决策树类模型的需求;
- 对于缺失值填充,采用 KNN 插补法相比均值填充更能保持原始数据的分布特性。
4.2 行业延伸应用场景
- 金融领域:对信贷数据中的逾期记录进行异常检测,提升风控模型准确性;
- 医疗领域:整合患者门诊与住院数据,统一血压、血糖等生理指标格式后用于疾病预测模型;
- 物流领域:对运输时长进行归一化处理,以适应路径优化算法的输入要求。
五、总结
数据预处理是大数据分析的“地基工程”,其质量直接影响最终分析结果的可信度。本文通过电商用户行为数据的完整案例,展示了从清洗、集成到转换、归约的全流程实践,强调应结合具体业务场景灵活选用处理方法。未来,随着自动化工具的发展,AI 驱动的智能清洗与自适应转换技术将逐步普及,但深入理解底层原理并具备手动处理能力,仍是数据分析师不可或缺的核心素养。

 京公网安备 11010802022788号
京公网安备 11010802022788号







