


 雷达卡
雷达卡



20分钟告别懵懂:手把手带你轻松入门线性回归
学习目标:掌握线性回归的基本概念、核心原理、参数求解方式及其典型应用场景。
预计耗时:约20分钟
1. 初识线性回归
1.1 线性回归是什么?
设想一个场景:你想根据房屋面积来预测房价。通常情况下,面积越大,价格也越高。那么,面积和价格之间是否存在某种可量化的规律?线性回归正是用来揭示这种数量关系的工具——可以将其理解为一把“智能测量尺”。
在机器学习领域,线性回归常被称为算法中的“Hello World”。就像编程初学者第一个写的程序是输出“Hello World”一样,它是进入机器学习大门的第一步。其逻辑清晰、易于理解,并为后续复杂模型的学习打下坚实基础。
举个例子说明:假设我们有一组数据点 (x, y),其中 x 表示某城市的人口数量,y 表示该城市的月度收入总额。我们的目标是寻找一条直线,使它能最好地描述人口与收入之间的线性趋势。如下图所示:
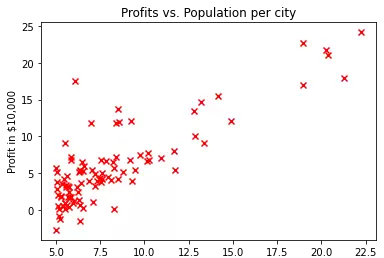
经过拟合后,我们可以得到一条尽可能贴近所有数据点的直线,如下图所示:
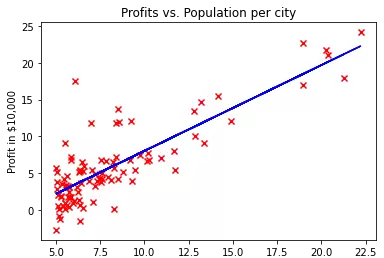
这条直线的数学表达式为:
fw,b(x) = wx + b
其中:
- 权重 w(weight):表示每增加一个单位人口时,收入的变化量;
- 偏置 b(bias):表示当人口为零时,模型对收入的预测值(即截距)。
我们的最终目标就是找出最优的 w 和 b,使得模型的预测结果与真实数据之间的误差最小化。
1.2 代价函数(Cost Function)详解
为了衡量预测值与实际值之间的差距,我们需要引入“代价函数”这一概念。代价函数的本质就是所有样本预测误差的平均度量。越小的代价函数值,代表模型拟合效果越好,预测也就越精准。
具体计算步骤如下:
对于第 i 个训练样本,模型的预测输出为:
fwb(x(i)) = wx(i) + b
对应的单个样本的误差(平方损失)为:
cost(i) = (fwb - y(i))
将所有 m 个样本的误差取均值,得到整体的代价函数:
J(w, b) = (1 / 2m) ∑i=0m-1 cost(i)
其中:
- m 是训练集的总样本数;
- ∑ 表示对所有样本进行累加求和。
1.3 权重与偏置如何影响代价函数
我们知道,直线的位置完全由两个参数决定:权重 w 和偏置 b。因此,它们的取值会直接影响代价函数的大小。
关于权重 w:它控制着直线的倾斜程度。若 w 设置过大,可能导致预测值严重偏离真实值,造成代价函数上升;而 w 过小则会使模型过于平缓,无法捕捉数据变化趋势,也可能导致误差增大。
关于偏置 b:它决定了直线在纵轴上的起始位置。如果 b 太小,整条线会下移,远离真实数据;反之若 b 过大,则会上移,同样导致拟合不佳,代价函数变大。
为了更直观地观察 w、b 与代价函数 J(w, b) 三者之间的关系,我们可以绘制一个三维图像:
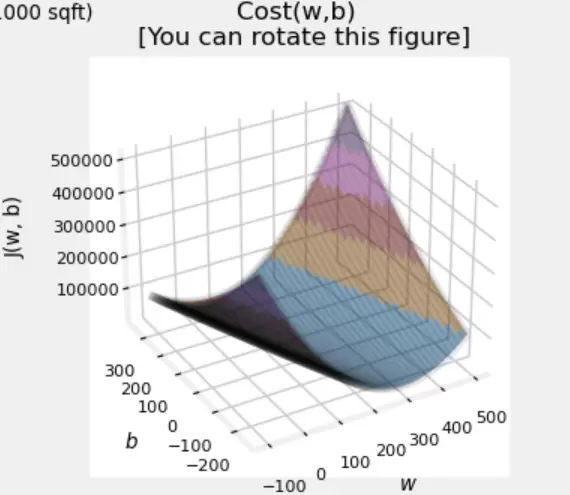
在这个图像中:
- X 轴表示权重 w 的取值范围;
- Y 轴表示偏置 b 的取值范围;
- Z 轴表示对应组合下的代价函数值。
我们的目标是在这个曲面上找到最低点——也就是代价函数取得最小值的位置。此时对应的 w 和 b 即为最优参数组合。而实现这一目标的关键方法,就是接下来要介绍的“梯度下降法”。
2. 使用梯度下降法寻找最优参数 w 和 b
梯度下降是一种优化算法,用于逐步调整参数以最小化代价函数。其核心思想是沿着函数下降最快的方向(即负梯度方向)不断更新参数,直到收敛到极小值点。
其迭代公式如下:
重复执行以下步骤直至收敛:
w := w - α × (J(w,b)/w)
b := b - α × (J(w,b)/b)
注意:w 和 b 必须同时更新,不能先改一个再用新值算另一个。
首先,我们需要计算代价函数对两个参数的偏导数:
对偏置 b 的偏导数为:
J(w,b)/b = (1/m) ∑i=0m-1 (fw,b(x(i)) - y(i))(公式2)
对权重 w 的偏导数为:
J(w,b)/w = (1/m) ∑i=0m-1 (fw,b(x(i)) - y(i))x(i)(公式3)
其中 α 是学习率,控制每次更新的步长。合适的 α 能加快收敛速度,而过大或过小都会影响结果稳定性。
通过反复应用上述更新规则,模型将逐步逼近最佳的 w 和 b 值,从而使预测更加准确。
在机器学习中,线性回归是一个基础但非常重要的模型。其核心目标是通过优化参数来最小化损失函数。损失函数的梯度计算如下:
\[ \frac{\partial J(w,b)}{\partial w} = \frac{1}{m} \sum\limits_{i=0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})x^{(i)} \tag{3} \]
其中,m 表示训练样本的总数;fw,b(x(i)) 是模型对第 i 个样本的预测输出;而 y(i) 是对应的真实标签值。
什么是梯度?
简单来说,梯度指向的是函数在某一点上变化最快的方向。更准确地说,**负梯度方向是函数下降最快的方向**。我们可以用一个类比来理解:假设你站在山顶,想要以最快的方式下山,那么每一步选择最陡峭的下行路径,就是沿着梯度的反方向前进。
学习率 α 的作用
学习率(α)决定了我们在每次迭代中沿梯度方向移动的步长:
- 如果 α 设置得过大,可能会导致跳过最优解,甚至发散;
- 如果 α 过小,则收敛速度会非常缓慢,需要更多迭代才能接近最优值。
这就像下山时的步伐控制:步子太大容易踩空冲过谷底,步子太小则耗时太久。
算法收敛的判断
当不断更新参数 w 和 b 后,若发现它们的变化幅度变得极小,或者代价函数 J(w, b) 几乎不再下降,就可以认为优化过程已经“收敛”,即找到了一个较为理想的参数组合。
实例演示:线性回归的迭代过程
考虑以下三组训练数据:(1, 2), (2, 3), (3, 4),我们尝试拟合一条直线 f(x) = wx + b。
设定初始参数:w = 0,b = 0,学习率 α = 0.1。
经过多次梯度下降迭代后,参数将逐渐调整至 w ≈ 1,b ≈ 1,最终得到模型 f(x) = x + 1,能够很好地拟合给定的数据点。
线性回归的实际应用场景
3.1 房价预测
输入特征:房屋面积、房龄、卧室数量、地理位置等
预测目标:房屋市场价格
实际应用:链家、贝壳等房产平台利用类似模型进行价格评估和房源推荐。
3.2 销售额预测
输入特征:广告支出、促销活动强度、季节性因素、历史销售记录
预测目标:未来一段时间内的销售额
实际应用:电商平台在大型促销前预估销量,合理安排库存,避免缺货或积压。
3.3 医疗健康分析
输入特征:年龄、体重、日常运动量、饮食结构
预测目标:血压水平、血糖浓度或慢性病风险
实际应用:健康管理类 APP 基于此提供个性化的健康干预建议。
3.4 金融风控建模
输入特征:个人收入、信用记录、负债比率、职业稳定性
预测目标:贷款违约的可能性
实际应用:银行用于自动审批贷款申请,并据此设定利率与授信额度。
3.5 气候趋势预测
输入特征:历史气温、湿度、风速、季节周期
预测目标:未来某时段的温度或降水量
实际应用:农业管理部门依据气候预测指导种植计划,降低极端天气带来的损失。
总结
线性回归虽然结构简单,却如同自行车一般——虽非最快,却是理解“前行机制”的最佳起点。每一位精通复杂模型的机器学习专家,都曾从研究这个最基础的公式开始成长。
关键在于:不要被数学表达式吓住,真正重要的是理解背后的逻辑思想。当你能用线性回归预测明天奶茶店的销售杯数时,你就已经迈出了机器学习的第一步。
本文内容到此结束。接下来的文章我们将进入代码实践环节,详细介绍如何用编程语言实现线性回归模型。

 京公网安备 11010802022788号
京公网安备 11010802022788号







