


 雷达卡
雷达卡



智能体评估实践:深度 Agent 的测试方法论
在过去的一个月里,LangChain 基于 Deep Agents 架构成功推出了四款实际应用:
- DeepAgents CLI:一个具备代码生成能力的智能代理
- LangSmith Assist:集成在 LangSmith 平台中的智能辅助系统
- Personal Email Assistant:能够通过用户交互持续学习并优化行为的邮件助手
- Agent Builder:面向非技术人员的无代码智能体构建平台
在这些 agent 的开发与部署过程中,团队为每个项目都设计并实施了专门的评估机制,积累了大量关于如何有效衡量复杂智能体表现的经验。本文将重点分享我们在评估深度 agent 时总结出的关键模式和最佳实践。
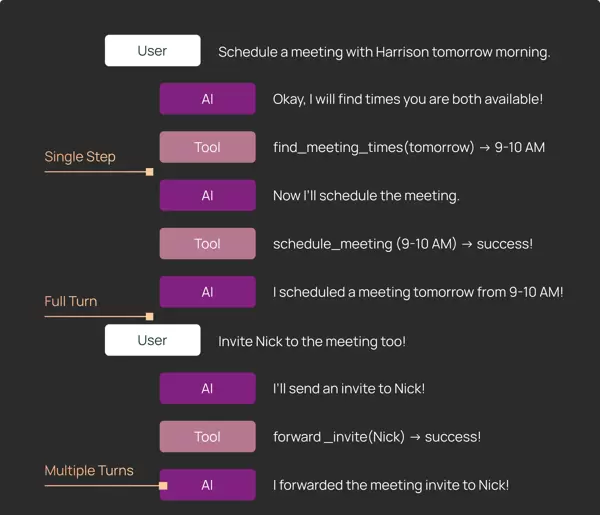
核心评估模式概述
- 测试逻辑需按用例定制 —— 不同场景的成功标准差异显著,难以统一
- 单步运行测试 —— 适用于验证特定决策路径,同时有助于节省 token 消耗
- 完整轮次运行 —— 更关注 agent 最终输出的结果状态
- 多轮对话模拟 —— 接近真实使用场景,但需控制变量以保证可重复性
- 环境配置至关重要 —— 测试环境必须干净、隔离且可复现
关键术语说明
为便于理解后续内容,先明确以下概念定义:
Agent 的三种运行模式
- 单步 (Single step):仅允许 agent 执行一次核心循环,观察其下一步动作决策
- 完整轮次 (Full turn):让 agent 完整处理一次输入请求,期间可能触发多次工具调用
- 多轮对话 (Multiple turns):模拟连续交互过程,agent 可进行多轮响应与状态更新
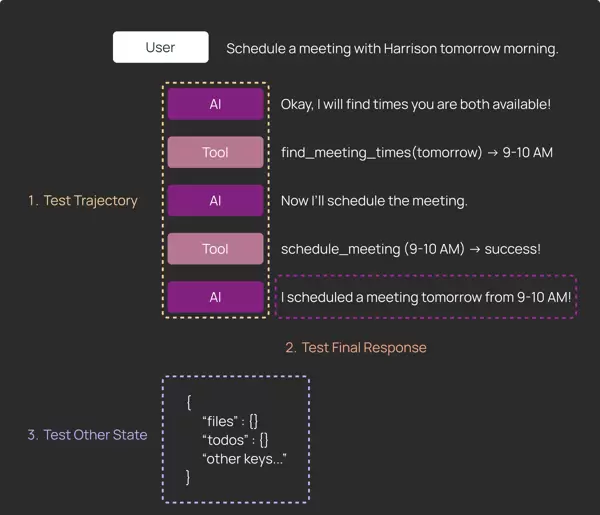
可被测试的内容类型
- 执行轨迹 (Trajectory):记录 agent 调用了哪些工具及其参数传递情况
- 最终响应 (Final response):agent 返回给用户的最终结果或回复文本
- 其他状态 (Other state):运行中产生的中间产物,如临时文件、缓存数据等
深度 Agent 需要个性化测试逻辑
传统的大模型评估流程通常较为标准化:
- 准备一组示例数据集
- 编写通用评估器
- 批量运行应用并生成输出,再由评估器统一打分
在这种模式下,所有数据点都遵循相同的处理逻辑和评分规则。
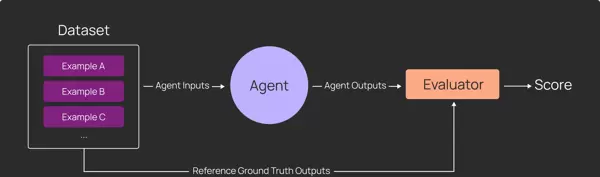
然而,深度 agent 的出现打破了这一范式。我们不仅需要关注最终输出,更要深入分析其内部行为轨迹。更重要的是,不同测试用例的成功判定条件往往截然不同,必须针对具体场景制定个性化的断言规则。
案例解析:日历调度 agent 的记忆更新测试
假设有一个能记住用户偏好的日历调度 agent。当用户说:“记住,不要在早上 9 点前安排会议”,我们需要验证该指令是否被正确记录。
为此,测试应涵盖以下几个方面:
- agent 是否调用了文件编辑工具来修改记忆文件
memories.md - agent 是否在最终回复中向用户确认了记忆已更新
memories.md文件内容是否确实包含了“不在 9am 前开会”的信息
对于文件内容的验证,可以采用两种方式:
- 使用正则表达式检测关键词(如 "9am")是否存在
- 借助 LLM-as-judge 方法,结合具体的成功标准进行更全面的内容分析

LangSmith 提供的 Pytest 和 Vitest 集成支持此类高度定制化的测试需求。开发者可以针对每一个测试用例,独立设置对 agent 轨迹、输出消息及运行状态的差异化断言。
# 标记为 LangSmith 测试用例
@pytest.mark.langsmith
def test_remember_no_early_meetings() -> None:
user_input = "I don't want any meetings scheduled before 9 AM ET"
# 可以把 agent 的输入记录到 LangSmith
t.log_inputs({"question": user_input})
response = run_agent(user_input)
# 可以把 agent 的输出记录到 LangSmith
t.log_outputs({"outputs": response})
agent_tool_calls = get_agent_tool_calls(response)
# 断言 agent 调用了 edit_file 工具来更新记忆
assert any([tc["name"] == "edit_file" and tc["args"]["path"] == "memories.md" for tc in agent_tool_calls])
# 用 LLM-as-judge 记录反馈: 最终消息是否确认了记忆更新
communicated_to_user = llm_as_judge_A(response)
t.log_feedback(key="communicated_to_user", score=communicated_to_user)
# 用 LLM-as-judge 记录反馈: 记忆文件是否包含正确信息
edit_filememory_updated = llm_as_judge_B(response)
t.log_feedback(key="memory_updated", score=memory_updated)
关于如何使用 Pytest 的通用代码示例,可以参考以下文档内容:
2 单步评估:高效且实用的验证方式
在对深度 Agent 进行评估时,约有一半的测试场景适用于单步评估。这种方式关注的是:给定一组输入消息后,LLM 是否会立即做出正确的决策?
这种评估方法特别适合验证 agent 在特定情境下是否正确调用了工具,例如:
- 是否正确发起会议时间的搜索?
- 是否准确读取了目标目录的内容?
- 是否成功更新了记忆状态?
许多回归问题往往出现在某个具体的决策节点,而非整个执行流程中。借助 LangGraph 提供的流式执行能力,可以在某次工具调用后中断 agent 的运行,从而提前检查输出结果,避免必须跑完整个流程才能发现问题。
如下代码所示,通过在 tools 节点前设置断点,可使 agent 仅执行一步,便于后续对状态进行检查和断言。
@pytest.mark.langsmith
def test_single_step() -> None:
state_before_tool_execution = await agent.ainvoke(
inputs,
# interrupt_before 参数指定在哪些节点前暂停
# 此处设置为在 tools 节点前中断,以便检查工具调用参数
interrupt_before=["tools"]
)
# 输出当前的消息历史,包含最新的工具调用请求
print(state_before_tool_execution["messages"])

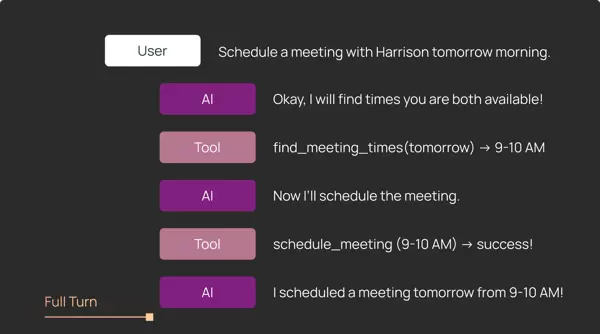
3 完整轮次运行:掌握端到端行为
可以把单步评估看作是“单元测试”,用于确保 agent 在具体场景下的局部行为符合预期;而完整轮次运行则更像“集成测试”,能够观察 agent 从开始到结束的整体表现。
完整轮次运行支持从多个维度评估 agent 行为:
- 执行轨迹分析: 判断某个关键工具是否在整个执行过程中被调用过,而不严格限定其调用时机。例如,在日历调度任务中,可能需要多次尝试才能找到所有参与者都空闲的时间段。
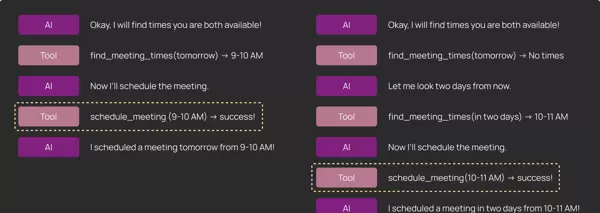
- 最终响应质量: 在一些开放式任务(如代码生成或信息研究)中,最终输出的质量比中间路径更重要。此时重点评估的是 agent 返回结果的有效性和完整性。

- 其他内部状态检查: 类似于评估最终输出,部分 agent 并不以对话形式回应用户,而是生成实际产物。通过 LangGraph 可直接访问 agent 的状态,进而验证这些产物是否符合预期。
- 对于编码类 agent:可读取并运行其生成的文件,验证能否通过测试。
- 对于研究类 agent:可断言其是否找到了正确的参考资料或链接。
LangSmith 将每一次完整的 agent 执行记录为一条 trace,不仅展示高层指标(如延迟、token 消耗),还允许深入分析每一步模型或工具调用的细节。
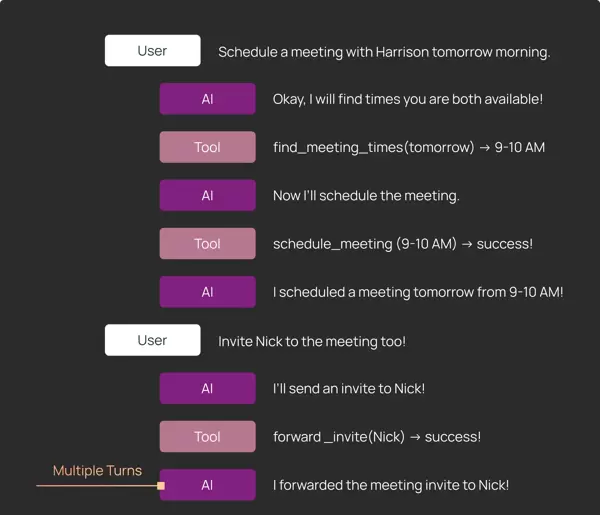
4 多轮对话测试:贴近真实交互场景
某些功能需要验证 agent 在连续多轮对话中的表现,即面对多个连续用户输入时的行为连贯性。直接硬编码一系列输入存在风险:一旦 agent 偏离预设路径,后续输入就可能不再适用。
为此,团队在 Pytest 与 Vitest 测试中引入了条件判断逻辑,实现动态控制流程:
- 先运行第一轮交互;
- 检查 agent 的输出是否符合预期;
- 若符合,则继续下一轮;否则提前失败。
该策略无需穷举所有分支路径,即可完成多轮评估。同时,若需单独测试第二轮或第三轮行为,只需从对应阶段开始,配置好初始状态即可快速启动测试。
5 构建合适的评估环境至关重要
深度 Agent 具备状态记忆能力,专为处理复杂、长期任务设计,因此其评估也需要更严谨的运行环境。
与传统无状态 LLM 评估不同,后者通常只涉及少量静态工具,而深度 Agent 的每次测试都应在一个全新、隔离的环境中运行,以保障结果的可复现性。
以编码 agent 为例:
- Harbor 为 TerminalBench 提供了基于专用 Docker 容器或沙箱的运行环境;
- 对于 DeepAgents CLI,团队采用了轻量级方案:每个测试用例均在一个独立的临时目录中执行 agent。
总结来说,深度 Agent 的评估必须保证每个测试都能重置运行环境 —— 否则极易导致结果不稳定、难以重现。
小技巧: 可考虑对 API 请求进行 mock,以提升测试速度并减少对外部服务的依赖。
为了实现 LangSmith Assist 的功能,需要与真实的 LangSmith API 建立连接。然而,直接在真实服务上运行评估通常效率较低且成本较高。一种更高效的替代方案是将 HTTP 请求录制并保存到文件系统中,在测试阶段再进行回放。
在 Python 环境中,可以使用 vcr 库来实现请求的录制与重放;而对于 JavaScript 项目,则可通过 Hono 应用作为代理来拦截和记录请求。
fetch通过模拟(Mock)或重放 API 请求,能够显著提升深度 Agent 的评估速度,并极大改善调试体验,尤其是在 Agent 高度依赖外部系统状态的情况下,这种做法尤为有效。
值得注意的是,使用 Mock 接口有助于快速打通整体流程,验证输入与输出的正确性,这也是开发者在实际调试过程中常用的重要手段之一。

 京公网安备 11010802022788号
京公网安备 11010802022788号







