


 雷达卡
雷达卡



墙体裂缝智能检测系统:融合YOLO与大语言模型的创新方案
WCIS(Wall Crack Inspection System) 是一款集成了目标检测与多模态语义理解能力的智能化墙体裂缝识别平台。该系统以 YOLOv8 为核心检测引擎,结合 LLaVA 多模态大语言模型进行深度分析,不仅能够准确捕捉墙面裂缝的位置信息,还能进一步解析其潜在成因,并生成具备工程参考价值的修复建议。
系统分层架构设计
本系统采用清晰的模块化分层结构,确保功能解耦与高效协作,主要包括以下三个层级:
表现层(Presentation Layer)
- Web UI 界面:基于 Gradio 4.0 构建的可视化交互前端,提供直观的操作体验。
- 主界面控制器:负责管理多个 Tab 页面的布局与切换逻辑。
- 实时反馈机制:通过 Gradio 的事件监听能力,实现训练进度与任务状态的动态轮询更新。
AdvancedWebInterface业务逻辑层(Business Logic Layer)
- 核心控制器:协调各子系统之间的数据流转与流程控制。
- 视频处理模块:利用 OpenCV 对输入视频逐帧提取,调用检测模型推理后合成带标注的输出视频。
video_detector.py- 批量处理机制:内置多线程队列系统,支持大规模图像文件上传、异步处理及结果打包下载。
web_interface_advanced.py- 历史记录管理:使用 SQLite 或 JSON 格式持久化存储所有操作日志,便于后续追溯与审计。
history_manager.py算法核心层(Algorithm Core Layer)
- 目标检测引擎 — YOLOv8:
- 精准定位裂缝区域坐标。
- 输出高置信度的检测评分。
bboxconfidence- 多尺度推理支持:自动调整图像缩放比例,提升对微小裂缝的检出率。
- 智能分析模块 — LLaVA:通过连接 Ollama 服务接口接入大模型能力。
llava_analyzer.py- Prompt 工程优化:预设专用于裂缝诊断的提示词模板,将检测结果转化为自然语言描述,自动生成专业分析报告。
主要功能特性详解
1. 高精度裂缝识别(基于YOLOv8)
- 实时响应:毫秒级推理速度,适用于现场快速筛查横向、纵向及网状裂缝。
- 可视化标注:在原始图像上绘制精确边界框,采用红/黄工业警示色区分风险等级,并标注置信度百分比。
- 多模型兼容性:支持 YOLOv8n/s/m/l/x 全系列模型,用户可根据设备性能灵活选择精度与效率的平衡点。
2. 基于LLaVA的智能成因诊断
- 上下文感知分析:LLaVA 模型不仅能“看见”裂缝,更能结合环境特征“理解”其形成背景。
- 结构化报告生成:自动输出包含以下内容的专业评估文档:
- 裂缝分布情况:位置、延伸方向等空间特征描述。
- 严重程度评估:依据宽度、长度判断结构安全风险等级。
- 可能诱发因素:如地基不均匀沉降、温度应力收缩或外部机械撞击等。
- 维修策略建议:推荐灌浆处理、表面封闭或结构性加固等应对措施。
- 交互式问答支持:集成智能助手,允许用户针对报告内容发起追问,获取更深入的技术建议。
3. 多样化检测模式支持
- 单图检测模式:适用于高精度分析单张图像,支持放大查看细节区域。
- 视频流检测:
- 兼容 MP4、AVI、MOV 等主流视频格式。
- 支持跳帧处理,可调节参数以优化处理效率与检测密度。
- 处理完成后自动生成带标注轨迹的视频文件,便于后期回放审查。
crack_detection_system.py- 批量处理(高效模式):
- 支持一次性拖拽上传数百张现场照片。
- 后台启用多线程并行处理,避免阻塞前端操作。
- 自动生成 CSV 格式的统计报表,包含文件名、裂缝数量、最高置信度等关键指标。
- 支持一键打包下载全部结果图像(ZIP 格式)。
4. 可视化模型训练功能
- 零代码训练配置:无需编写任何 Python 脚本,直接在 Web 界面设置 Epochs、Batch Size、Image Size 等超参数。
- 训练过程可视化监控:
- 动态展示 mAP50 与 mAP50-95 曲线变化趋势。
- 实时滚动显示训练日志输出。
- 配备进度条与剩余时间预估功能。
- 硬件自适应机制:系统自动检测可用 GPU(CUDA),优先启用加速;若无 GPU 支持则无缝切换至 CPU 模式,并智能调整推荐参数。
5. 完善的历史数据与任务管理
- 全生命周期记录:所有检测与训练任务均被自动保存至本地数据库。
- 便捷的数据回溯:
- 支持按时间范围和任务类型(检测/训练)进行筛选查询。
- 可随时调阅历史检测结果与对应的 LLaVA 分析报告。
- 实时同步机制:界面具备一键刷新功能,确保多人协同工作时数据状态一致。
推荐运行环境配置
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10/11, Linux (Ubuntu 20.04+) | Windows 11 或 Ubuntu 22.04 |
| Python 版本 | 3.8 | 3.10 |
| GPU | NVIDIA GTX 1060 (6GB) | NVIDIA RTX 3060 (12GB) 或更高 |
| 内存 | 16 GB | 32 GB |
| 硬盘空间 | 20 GB 可用空间 | 50 GB SSD |
必需软件依赖: Ollama
运行依赖说明:
- LLaVA 模型:用于实现智能分析功能,为系统提供深度语义理解能力。
- FFmpeg:负责视频文件的解析与处理,是视频检测模块正常运行的前提条件。
安装与部署流程
第一步:环境配置
安装项目所需的 Python 第三方库,请执行以下命令:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple第二步:外部组件安装
Ollama(支持智能分析)
前往 Ollama 官网 下载并完成安装。安装成功后,在终端中运行如下指令以获取 LLaVA 模型:
ollama pull llava第三步:启动系统服务
使用以下命令启动可视化 Web 界面:
python run_web_advanced.py启动完成后,浏览器将自动打开并访问以下地址:
http://localhost:7860功能使用详解
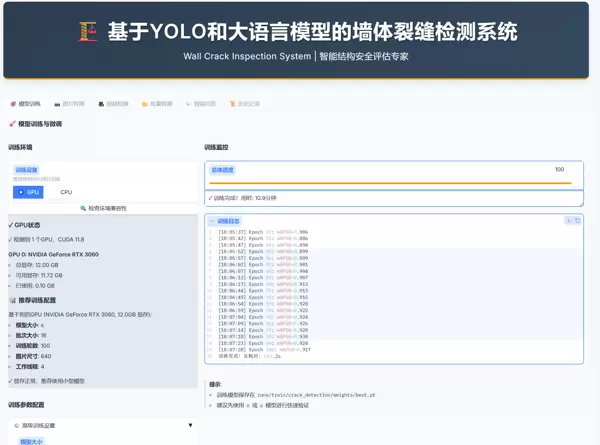
标签页 1:模型训练
本页面支持对自定义数据集进行模型微调,提升特定场景下的识别准确率。
环境配置
系统会自动识别可用 GPU 设备,建议选择 GPU 进行加速以显著缩短训练时间。
参数设置
- 模型大小:
(nano 版本)处理速度最快;n
(extra large)精度最高。x
推荐选用
或s
以平衡效率与性能。m - Epochs(训练轮数):通常设置在 100 至 300 轮之间可获得较优结果。
开始训练
点击“???? 开始训练”按钮,右侧日志区域将实时输出训练进度信息。
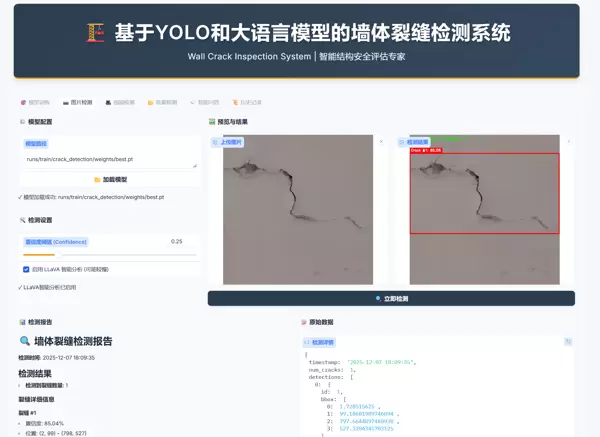
标签页 2:图片检测
加载模型
默认加载的模型为
best.pt上传图像
可通过点击图像区域或直接拖拽的方式上传待检测图片。
检测配置
- 置信度阈值:用于过滤低可信度的检测框,避免误报。
- 启用 LLaVA:勾选后将调用大语言模型进行智能分析,单张图片处理耗时约 5–10 秒。
查看结果
左侧展示标注后的检测图,右侧同步生成详细的智能分析报告。
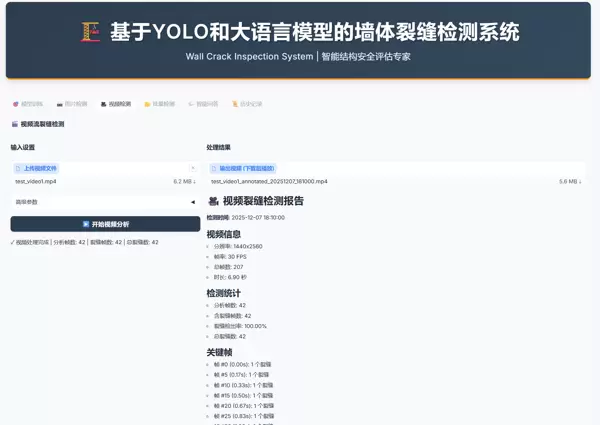
标签页 3:视频检测
上传视频
支持常见格式如 MP4、AVI 等。
跳帧设置
默认值为 5。数值越大处理越快,但可能导致快速闪现的目标(如裂缝)被漏检。
结果下载
处理完毕后可直接在线播放,或通过顶部工具栏图标下载已标注的视频文件。
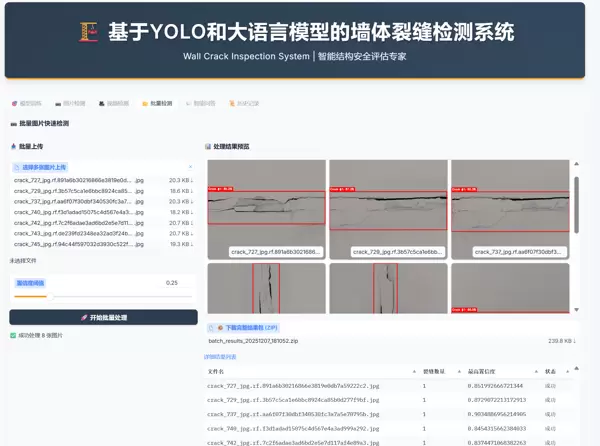
标签页 4:批量检测(新增功能)
批量上传
支持一次性选择多张图片进行上传操作。
自动化处理
点击“???? 开始批量处理”,系统将自动逐张完成检测任务。
结果导出
- 预览:以缩略图形式浏览所有检测结果。
- 下载:系统将打包生成一个 ZIP 文件,包含所有标注图片及
。summary_report.csv
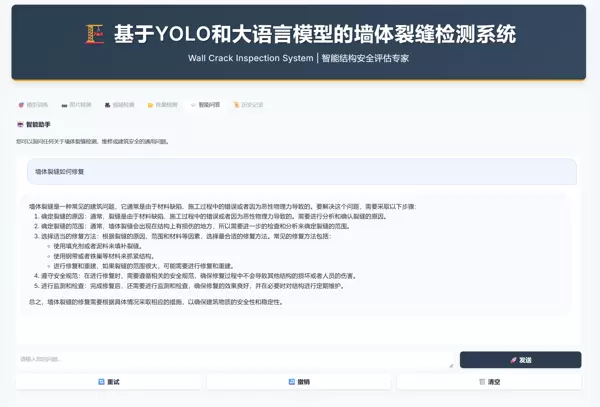
标签页 5:智能问答
集成通用工程知识助手,可用于咨询建筑规范、裂缝修复方法、材料选型等相关问题。
底层由 Ollama/LLaVA 模型驱动,支持自然语言交互。
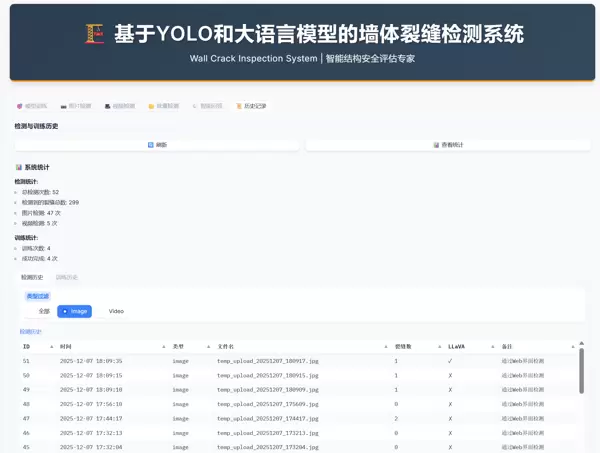
标签页 6:历史记录
自动保存
所有检测和训练任务均会被系统持久化存储。
筛选查看
点击“检测历史”或“训练历史”子标签,可查看对应的任务列表表格。
自动刷新
切换至该标签页时,表格内容将自动更新以反映最新状态。
配置文件说明(config.yaml)
核心配置项位于
config.yamlweb:
host: "127.0.0.1" # 服务监听地址
port: 7860 # 服务端口
share: false # 是否开启公网共享链接
yolov8:
model_size: "n" # 默认使用的模型尺寸
train:
device: 0 # 使用的 GPU 编号
batch_size: 16 # 训练批次大小
llava:
ollama_url: "http://localhost:11434" # Ollama 服务接口地址
model: "llava" # 调用的大模型名称常见问题排查(Troubleshooting)
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
启动时报错 |
依赖未正确安装 | 确认已执行 |
| 无法启用 LLaVA 功能 | Ollama 服务未运行 | 检查是否已安装 Ollama,并尝试在终端运行 |
视频检测出现错误 |
缺少 FFmpeg 组件 | 请安装 FFmpeg 并将其路径添加到系统环境变量 PATH 中 |
| 训练过程中显存溢出(OOM) | batch_size 设置过大 | 在训练配置中减小 |
| 端口被占用 | 已有实例正在运行 | 关闭其他终端窗口,或通过任务管理器终止 |




 京公网安备 11010802022788号
京公网安备 11010802022788号







