


 雷达卡
雷达卡



1. 选题的目的与意义
近年来,随着电子商务的快速扩张,用户基数不断增长,其行为数据呈现出高度复杂化和多样化的趋势。面对海量且非结构化的用户行为信息,电商平台亟需借助先进的数据挖掘手段,深入挖掘用户的行为特征,实现精细化的用户分群,从而提升用户体验并增强平台的整体盈利能力。
K-Means作为一种广泛应用的无监督学习算法,具备高效处理大规模数据的能力,能够对用户进行有效的聚类分析,帮助识别高价值客户、潜在活跃用户以及存在流失风险的群体。基于该算法开展电商用户行为研究,具有多重现实意义:
首先,有助于显著提高营销活动的精准度与转化效率。通过对用户的浏览、购买及互动行为进行模式识别,并结合消费偏好完成用户分层,平台可为不同群体制定差异化的推广策略,实现个性化触达,降低无效投放成本。
其次,有利于优化资源配置。在资源有限的前提下,将运营重点聚焦于高贡献或高潜力用户,能最大化投入产出比;而对于低频次、低消费的用户,则可通过低成本方式维持联系,延长生命周期,从而实现整体资源的科学配置与高效利用。
再次,能够有效提升用户体验。依托聚类结果构建的个性化推荐机制和服务体系,使用户更便捷地获取符合自身需求的商品信息,感受到平台的专属关怀,进而增强满意度与忠诚度,促进复购行为的发生。
最后,此类分析还为企业的战略决策提供了坚实的数据支撑。通过洞察各用户群体的行为演变趋势,企业可以及时调整产品布局、优化供应链管理,并发掘新的市场机会点。因此,采用K-Means算法进行电商用户行为建模,不仅在学术层面具备研究价值,在实际业务场景中也展现出强大的应用潜力,是推动电商平台迈向智能化、精细化运营的重要技术路径。
2. 主要研究内容
本研究围绕电商用户行为特征展开系统性分析,主要涵盖以下六个核心环节:
- RFM模型构建:基于用户最近购买时间(Recency)、购买频率(Frequency)和消费金额(Monetary)三项关键指标,建立量化评估体系。
- 数据准备与特征提取:收集原始用户行为日志,完成数据清洗、缺失值处理、异常检测及标准化流程,并从中提取可用于聚类的有效特征。
- K-Means算法应用:利用K-Means方法对预处理后的用户数据执行聚类操作,确定最优簇数并训练最终模型。
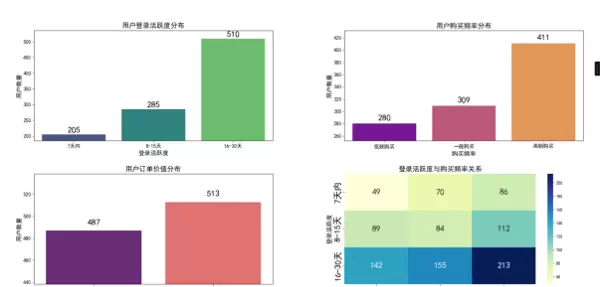
- 聚类结果分析与可视化:通过统计各簇的中心点与均值特征,解析不同用户群体的行为画像;结合PCA降维与雷达图等可视化工具展示聚类效果。
- 应用场景设计:探讨聚类成果在精准营销、会员分级、流失预警等方面的实际落地路径。
- 优化与扩展:引入K-Means++初始化策略提升收敛性能,同时对比其他聚类算法(如层次聚类、DBSCAN),探索模型鲁棒性与适应性的改进空间。



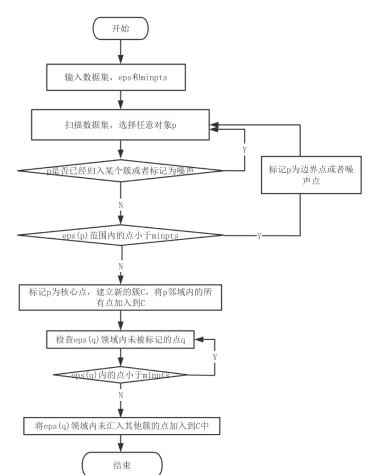 DBSCAN算法流程图
DBSCAN算法流程图

3. 研究条件、方法与实施措施
(1)研究条件
- 硬件支持:配备高性能计算设备,以保障大规模用户行为数据的存储与运算效率。
- 软件环境:
- Python 编程语言及其常用数据分析库:Pandas(数据处理)、Numpy(数值计算)、Scikit-learn(机器学习建模)、Matplotlib 与 Seaborn(数据可视化)。
- 开发工具:PyCharm,用于代码编写、调试与结果呈现。
- 数据来源:采用真实电商平台提供的脱敏用户行为记录,或使用模拟生成的数据集,包含订单信息、页面访问轨迹、点击流日志等关键字段。
(2)研究方法
本研究主要依托Python生态中的多种算法与工具库实现全流程分析:
- K-Means聚类建模:基于Scikit-learn库实现核心聚类逻辑,完成用户分群任务。
- 数据预处理:运用Pandas与Numpy进行数据清洗、去重、填补缺失值及特征构造。
- 结果可视化:利用Matplotlib和Seaborn绘制分布图、热力图、雷达图等,直观展现聚类特征差异。
- 降维与算法对比:采用主成分分析(PCA)对高维特征进行压缩,辅助可视化;同时引入层次聚类、DBSCAN等算法进行横向比较,验证K-Means的适用性与稳定性。
(3)实施措施
为确保研究顺利推进,采取如下具体措施:
- 广泛查阅相关领域的学术文献与专业书籍,深入理解K-Means算法原理、RFM模型架构及其在用户分群中的典型应用案例。
- 系统学习并实践Python数据科学栈,掌握从数据加载到模型评估的完整技术链条。
- 完成程序编码与多轮调试,持续优化模型参数与流程设计,提升聚类精度与泛化能力。
- 针对动态变化的用户行为数据,设计周期性模型更新机制,确保分析结果的时效性。
- 按照规范结构撰写论文,突出实验设计思路、分析过程与实际应用价值,强化研究成果的逻辑性与可读性。
(4)实验设计方案
实验流程分为五个阶段:
- 数据准备
从公开数据集或合作平台获取原始用户行为数据,包括交易记录、会话日志等;随后进行数据清洗,剔除重复项、异常值及严重缺失样本;最后通过StandardScaler或MinMaxScaler对特征变量进行归一化处理,消除量纲影响,保证聚类公平性。
- RFM模型构建
- Recency(R):计算每位用户距离当前日期最近一次购买的时间间隔,反映其近期活跃状态。
- Frequency(F):统计用户在指定时间段内的下单次数,衡量其参与频率。
- Monetary(M):汇总用户在此期间的总消费额,体现其商业价值。
- K-Means算法实施
- 通过肘部法则(Elbow Method)绘制SSE随簇数变化的曲线,初步判断最优K值。
- 结合轮廓系数(Silhouette Score)进一步验证聚类质量,选择综合表现最佳的簇数量。
- 使用选定K值训练K-Means模型,迭代更新聚类中心直至收敛。
- 识别并分析离群点,挖掘异常消费行为背后的潜在原因。
- 聚类结果分析与可视化
- 计算每个簇在R、F、M三个维度上的平均值,归纳各类用户的典型行为特征。
- 采用PCA将四维及以上数据降至二维平面,绘制散点图展示各簇的空间分布情况。
- 利用雷达图、柱状图等形式对比不同群体在各项指标上的表现差异,形成清晰的用户画像。
- 模型优化与功能拓展
- 引入K-Means++算法优化初始质心选择,加快收敛速度并提升聚类稳定性。
- 与其他聚类方法(如层次聚类、DBSCAN)进行效果对比,评估各自优劣。
- 设计自动化更新机制,定期重新训练模型以适应用户行为的动态演化。
(5)参考文献
(此处省略具体参考文献列表,按正式论文格式另行整理)
随着电子商务的快速发展,用户行为分析在精准营销和客户管理中的作用日益凸显。众多研究者围绕电商环境下的用户行为展开了深入探讨,其中基于数据挖掘技术的分析方法成为主流方向之一。K-Means聚类算法因其结构简单、执行效率高,在电商用户细分、消费偏好识别及潜在价值评估中得到了广泛应用。
韩晨(2023)利用K-Means聚类对直播购物场景下的消费者偏好进行分类研究,揭示了不同群体在观看时长、互动频率与购买转化方面的显著差异,为直播运营策略提供了数据支持[1]。类似地,张玉琨(2022)将该算法应用于学生客户群体的细分,识别出具有不同消费特征的学生子群,有助于电商平台制定更具针对性的促销方案[7]。王慧丽(2022)则设计了一种基于K-Means的电商数据智能分析框架,提升了客户分群的准确性和实用性[9]。
为进一步提升聚类效果,部分学者对传统K-Means算法进行了优化。郭磊等(2019)提出一种改进型K-Means算法,用于电商用户的聚类分析,有效提高了收敛速度与分类稳定性[15]。顾亦然与陈禹洲(2021)结合SOM神经网络与K-Means算法,对商品评论文本进行主题聚类,实现了情感倾向与用户反馈内容的深度挖掘[11]。韩琮师(2020)在其研究中也指出,通过引入初始中心点优化机制,可显著增强算法在电商平台精准营销中的适用性[14]。
除基础聚类外,多模型融合方法也被广泛探索。吴丹与朱美芳(2022)结合K-Means聚类与神经网络模型,构建了电商客户潜在价值评估体系,实现了对高价值客户的有效识别[8]。李清华与李兴东(2024)则将RFBC模型与聚类分析相结合,从频率、金额、行为多样性等多个维度对用户进行综合划分,增强了用户画像的立体性[10]。
在社交电商领域,用户行为呈现出更强的互动性与复杂性。高昀及其导师牛少彰(2021)针对社交平台用户的行为路径展开分析,提取关键行为指标并进行聚类归类,为平台推荐机制优化提供依据[2][3]。杨非非(2022)基于客户旅程理论,对淘宝用户的购买行为进行预测建模,发现不同阶段的行为特征可通过聚类有效捕捉[5]。
此外,K-Means算法的应用已拓展至非传统零售场景。胡朝晖与张革伕(2019)将其应用于净菜配送门店的客户管理中,根据消费周期与订单金额划分客户层级,辅助企业实施差异化服务策略[12]。戴远泉(2021)则将该方法集成于电商企业的ERP系统中,实现对大客户的动态跟踪与分析[6]。
黄益国(2021)强调,数据挖掘技术不仅可用于用户行为建模,还能同步分析商品销售趋势,从而支持库存优化与品类管理决策[4]。这一观点体现了数据分析在电商运营中的多维价值。
总体来看,国内外学者在聚类分析领域已有坚实理论基础。Kaufman与Rousseeuw(2021)在《Finding Groups in Data》中系统阐述了聚类分析的基本原理与发展脉络[17],而Tan、Steinbach与Kumar(2023)在《Introduction to Data Mining》中进一步介绍了包括K-Means在内的多种数据挖掘算法及其应用场景[18],为后续应用研究提供了重要参考。
上述研究表明,以K-Means为核心的聚类方法已成为电商数据分析的重要工具,并持续向智能化、精细化方向演进。

 京公网安备 11010802022788号
京公网安备 11010802022788号







