


 雷达卡
雷达卡






介绍
如果你从事数据科学、数据工程,或者做前端/后端开发,你会接触到JSON。对于专业人士来说,基本上只有死亡、税务和JSON解析是不可避免的。问题在于解析JSON往往非常麻烦。
无论你是从 REST API 拉取数据、解析日志,还是读取配置文件,最终你都会得到一个嵌套的字典,需要你去解开。说实话:我们写的这些词典代码往往......至少可以说是难看。
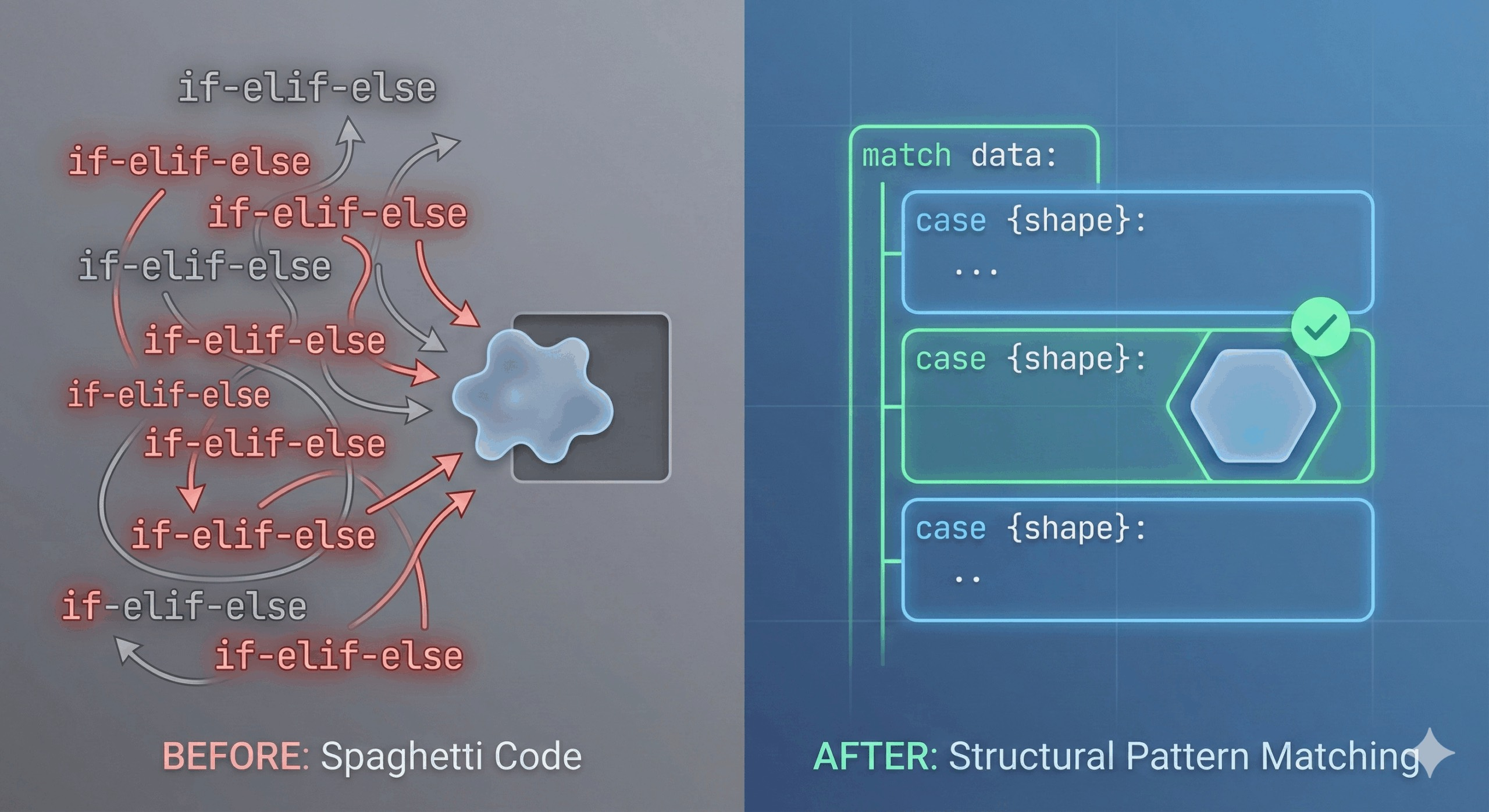
我们都写过“意大利面解析器”。你知道那种。它从一个简单的陈述开始,但随后你需要检查是否存在密钥。然后你需要检查该密钥内的列表是否为空。然后你需要处理错误状态。if
不知不觉中,你就拥有一座40行的陈述塔,难以阅读,更难维护。管道最终会因某些不可预见的边缘情况而破裂。气氛很糟!if-elif-else
几年前发布的Python 3.10中,引入了一个许多数据科学家尚未采用的功能:结构模式匹配(Structural Pattern Match),支持和。它常被误认为是简单的“Switch”语句(比如 C 或 Java 中的),但它的功能要强大得多。它允许你检查数据的形状和结构,而不仅仅是其数值。matchcase
本文将探讨如何用和替换脆弱的词典检查,用优雅且易读的模式。我将重点介绍一个我们都熟悉的具体用例,而不是试图概述如何使用和。matchcasematchcase
情景:“神秘”API响应
让我们想象一个典型的场景。你是在轮询一个你无法完全控制的外部API。假设,为了让设置更具体,API 以 JSON 格式返回数据处理作业的状态。API有点不一致(通常都是这样)。
它可能会返回成功回复:
{
"status": 200,
"data": {
"job_id": 101,
"result": ["file_a.csv", "file_b.csv"]
}
}
或者错误回复:
{
"status": 500,
"error": "Timeout",
"retry_after": 30
}
或者可能是奇怪的遗留响应,只是一个ID列表(因为API文档骗了你):
[101, 102, 103]
旧法:末日金字塔 if-else
如果你用标准的Python控制流程写这篇文章,你很可能会得到这样的防御性代码:
def process_response(response):
# Scenario 1: Standard Dictionary Response
if isinstance(response, dict):
status = response.get("status")
if status == 200:
# We have to be careful that 'data' actually exists
data = response.get("data", {})
results = data.get("result", [])
print(f"Success! Processed {len(results)} files.")
return results
elif status == 500:
error_msg = response.get("error", "Unknown Error")
print(f"Failed with error: {error_msg}")
return None
else:
print("Unknown status code received.")
return None
# Scenario 2: The Legacy List Response
elif isinstance(response, list):
print(f"Received legacy list with {len(response)} jobs.")
return response
# Scenario 3: Garbage Data
else:
print("Invalid response format.")
return None
为什么上面的代码会伤害我的灵魂?
它将“What”和“How ”混合在一起:你实际上是在将业务逻辑(“成功意味着状态200”)与类型检查工具如和混合在一起。isinstance().get() 内容很冗长:我们花了一半代码验证密钥是否存在以避免 。KeyError 难以扫描:要理解什么是“成功”,你需要在脑海中解析多个嵌套缩进层级。
更好的方法:结构模式匹配
输入关键词和。matchcase
而不是问诸如“这是字典吗?”这样的问题。它有叫做状态的密钥吗?那是密钥200吗?“,我们可以简单描述我们想处理的数据形状。Python 试图将数据适应到那个形状中。
这里是完全相同的逻辑,重新写成了 和:matchcase
def process_response_modern(response):
match response:
# Case 1: Success (Matches specific keys AND values)
case {"status": 200, "data": {"result": results}}:
print(f"Success! Processed {len(results)} files.")
return results
# Case 2: Error (Captures the error message and retry time)
case {"status": 500, "error": msg, "retry_after": time}:
print(f"Failed: {msg}. Retrying in {time}s...")
return None
# Case 3: Legacy List (Matches any list of integers)
case [first, *rest]:
print(f"Received legacy list starting with ID: {first}")
return response
# Case 4: Catch-all (The 'else' equivalent)
case _:
print("Invalid response format.")
return None
注意它比这条线短了几行,但这并不是唯一的优势。
为什么结构模式匹配如此棒
我至少能想到三个理由说明结构模式匹配能改善上述情况。matchcase
1. 隐式变量解包
注意案例1中发生的事情:
case {"status": 200, "data": {"result": results}}:
我们不仅仅是检查钥匙。我们同时检查了 是 ,并且 将 的值提取到一个名为 的变量中。status200resultresults
我们用简单的可变位置替代了。如果结构不匹配(例如缺失),则直接跳过此情况。没有,没有崩溃。data = response.get("data").get("result")resultKeyError
2. 模式“万用牌”
在案例2中,我们使用和作为占位符:msgtime
case {"status": 500, "error": msg, "retry_after": time}:
这告诉 Python:我期望一个状态为 500 的词典,并且对应关键字和 。无论这些值是多少,都绑定到变量上,这样我就能立即使用它们。"error""retry_after"msgtime
3. 列表结构化
在案例3中,我们处理了列表响应:
case [first, *rest]:
该模式匹配任何至少包含一个元素的列表。它将第一个元素绑定到,列表的其余绑定到。这对递归算法或处理队列非常有用。firstrest
增加“守卫”以增强控制
有时,仅匹配结构还不够。只有在满足特定条件时才需要匹配结构。你可以通过直接在案例中添加一个子句来实现。if
想象一下,我们只想处理包含少于10个项目的遗留列表。
case [first, *rest] if len(rest) < 9:
print(f"Processing small batch starting with {first}")
如果列表过长,该情况将不存在,代码将转移到下一个情况(或通用情况)。_
结论
我并不是建议你用块替换每个简单语句。不过,你应该强烈考虑使用和当你:ifmatchmatchcase
解析API响应:如上所述,这就是致命的用例。 处理多态数据:当函数接收 a 、a 或 a 时,需要对每个函数表现出不同的行为。 intstrdict遍历AST或JSON树:如果你写脚本来抓取或清理混乱的网页数据, 作为数据专业人士,我们的工作通常80%是清理数据,20%是建模。任何能让清洁阶段更少出错、更易阅读的做法,都是对生产力的巨大胜利。
考虑放弃意大利面。让和工具来承担重任吧。if-elsematchcase
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !





 京公网安备 11010802022788号
京公网安备 11010802022788号







