




 雷达卡
雷达卡
















这节介绍在 SPSS Statistics 和在 SPSS Modeler 调用 R 语言的方法,重点是前者的实现。而后者需要在前者已有的环境中,使用 SPSS Statistics 输出节点实现,也就是说在 SPSS Modeler 中调用 R 语言,也必须先安装 SPSS Statistics 软件。
2.1 SPSS Statistics 调用 R 语言的实现方式
首先是环境的准备。在已经安装了 SPSS Statistics 和 R 语言的环境中,需要新安装软件包 SPSS Statistics Essentials for R 来实现在 SPSS Statistics 中调用 R 语言。这个新的软件包就像一座桥梁将两个统计分析软件联系起来。
图 1. 用 Essentials for R 连接 R 语言和 SPSS Statistics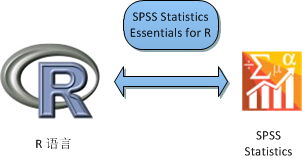
但应注意的是,针对不同的 SPSS Statistics 版本,需要有相对应的 R 语言版本和 SPSS Statistics Essentials for R 版本来匹配,其关系参照如下表格 :
表 1. SPSS Statistics 和 R 语言版本匹配表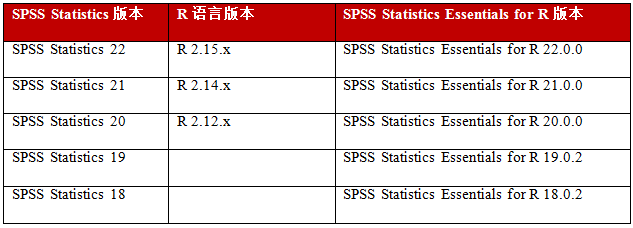
注:
1.前四个版本需要在IBM官网:https://www14.software.ibm.com/webapp/iwm/web/preLogin.do?source=swg-tspssp下载
2.最后一个版本需要在http://sourceforge.net/projects/ibmspssstat/下载
本文以下都以 Windows 操作系统中,使用 SPSS Statistics 22, R 2.15.3 和 SPSS Statistics Essentials for R 22.0.0 为例来讲解。安装 SPSS Statistics Essentials for R 软件包时会要求输入已有的 SPSS Statistics 和 R 语言环境,并建立联系。下面我们就来介绍在 SPSS Statistics 中调用 R 的最简单实现过程。
第 1 步:通过 SPSS Statistics 菜单:文件 --> 新建 --> 语法,打开 语法编辑器
图 2. 调用 R 的第 1 步——使用语法编辑器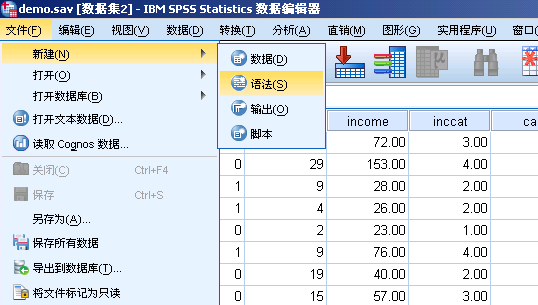
第 2 步:在编辑框中输入对应的语法脚本,遵循结构为:
代码 1. 嵌入 R 代码的基本语法结构BEGIN PROGRAM R. …… 中间为R代码……END PROGRAM如下图所示:
图 3. 调用 R 的第 2 步——在语法框中输入脚本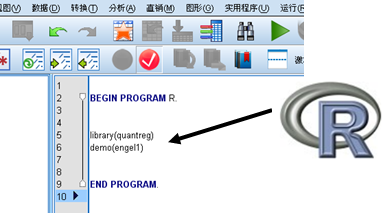
第 3 步:选取这段语法,执行菜单的:运行 --> 选择,或点击图标绿色三角,或执行快捷命令 Ctrl+R, R 代码分析的结果就会在 SPSS Statistics查看器中输出
图 4. 调用 R 的第 3 步——运行结果显示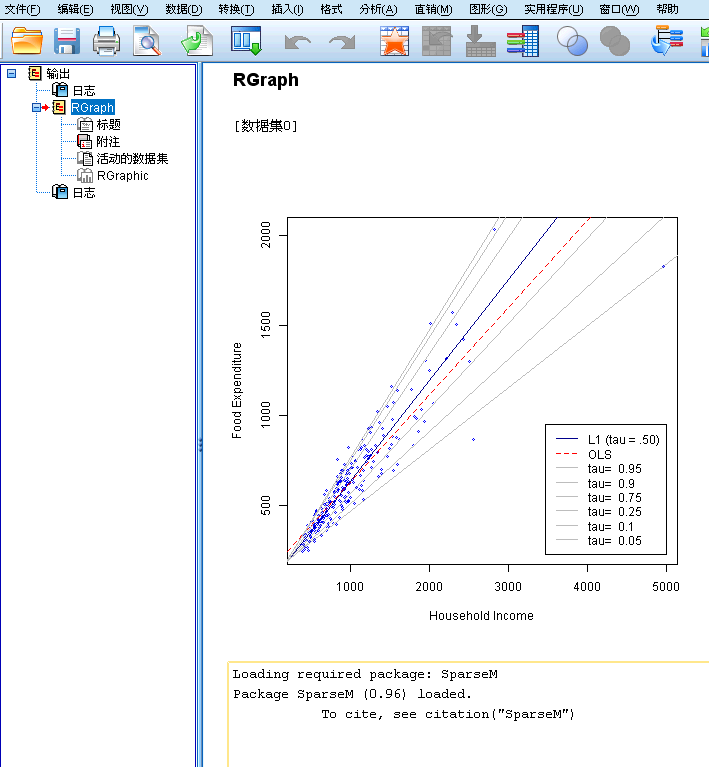
以上是在 SPSS Statistics 中嵌入 R 代码的最简单形式。如果希望在 R 代码中使用 SPSS Statistics 数据编辑器中的数据集,可以使用函数 spssdata.GetDataFromSPSS()。在数据编辑器中打开 SPSS 的实例数据 demo.sav,自动命名为【数据集 1 】。在语法编辑器中执行代码:
代码 2. 使用 SPSS Statistics 编辑器中的数据
- BEGIN PROGRAM R.
- demodata <- spssdata.GetDataFromSPSS()
- mean(demodata$age)
- END PROGRAM.
就可以计算得到 age 字段的均值,如下图:
图 5. 输出结果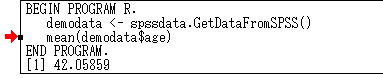
另一方面,也可以更直观地在 SPSS Statistics 查看器中输出 R 中的表格数据,例如代码:
代码 3. 查看 R 中产生的表格- BEGIN PROGRAM R.
- spsspivottable.Display(Formaldehyde,title="Determination of Formaldehyde")
- END PROGRAM.
输出结果为 SPSS 中的表格式样:
图 6. 输出结果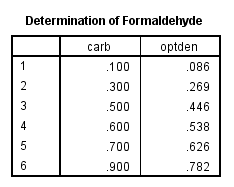
这里使用了函数 spsspivottable.Display()。而更复杂的多维数据表格展示,需要使用更多 SPSS Statistics 的类型和函数,参考我们后面的例子。
2.2 SPSS Modeler 调用 R 语言的实现方式
SPSS Modeler 中调用 R 代码需要使用 Modeler 中 Statistics 输出节点作为过渡来实现。因而该系统中必须也要安装 SPSS Statistics,使用 Modeler 的统计量实用程序(Statistics Utility)关联上 Statistics 的应用目录。同样安装对应的 SPSS Statistics Essentials for R 包。这样就可以在 Modeler 中调用 R 语言了。
图 7. 在 SPSS Modeler 中使用 R 语言的方法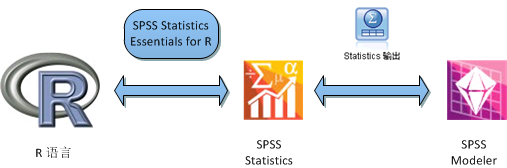
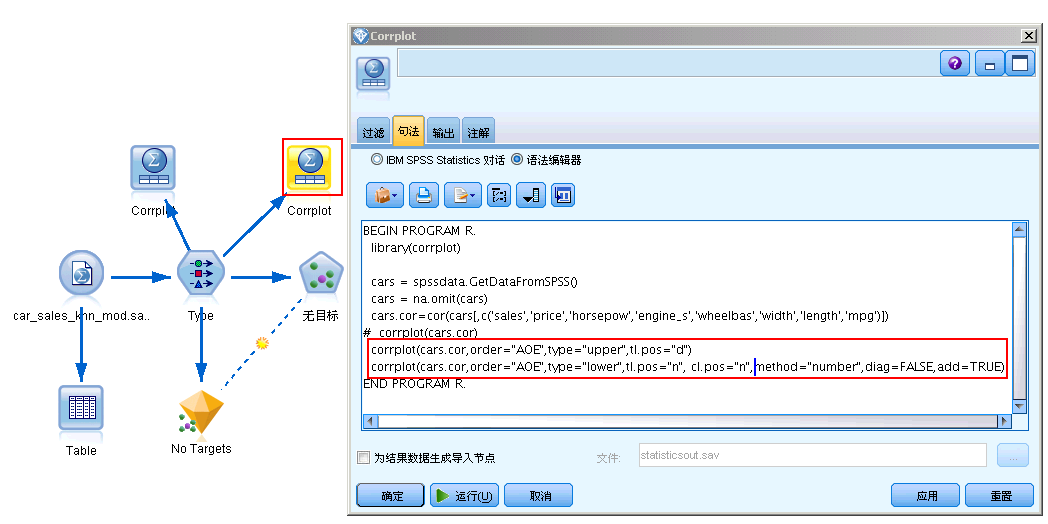
在 Modeler 中添加 Statistics 输出节点,然后在节点的语法编辑器中按照 Statistics 调用 R 的格式输入代码:
图 8. 在 SPSS Modeler 中调用 R 代码的方法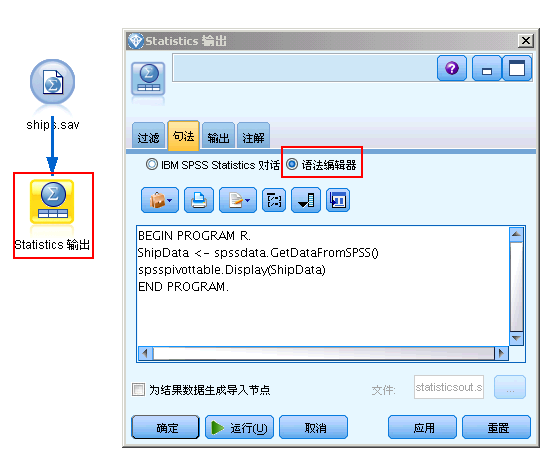
另外,虽然 Statistics 变换节点也有语法编辑器,但其并不支持 BEGIN PROGRAM … END PROGRAM 的语法,所以并不能调用 R 语言。
3. SPSS 调用 R 语言的实例3.1 利用 SPSS Statistics 优化 R 语言的数据显示
因为 R 语言是基于命令行的文本显示方式,对于常见的多维数据不能很直观地展示。当把 R 语言集成到 SPSS Statistics 后,就可以调用 Statistics 专门设计的一些函数,在查看器中更形象地使用数据透视表(pivot table)来展示多维数据。以下例子为 R 中自带数据 HairEyeColor,其统计了不同头发和眼睛颜色的男女学生的学生人数:
图 9. R 中的数据 HairEyeColor
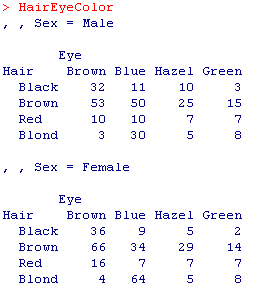
由此可见,这个数据有头发颜色(Hair)、眼睛颜色(Eye)和性别(Sex)3 个维度(dimension),而度量(measure)是统计的人数。在基本的 R 中只能显示二维数据表格,包含一个行维度(row dimension)和一个列维度(column dimension)。更高维的数据则分解为多个二维表格——即分解到这两个维度以外的其他维度取值的组合数目的表格中,其它维度的组合称作层维度(layer dimension)。这个例子中第三个维度 Sex 有 Male 和 Female 两个取值,所以用两个二维数据表格来展示整个数据。如果需要在一个表格中展示整个多维数据,传统中使用平表(flat table),例如:
图 10. 平表 (flat table) 显示多维数据
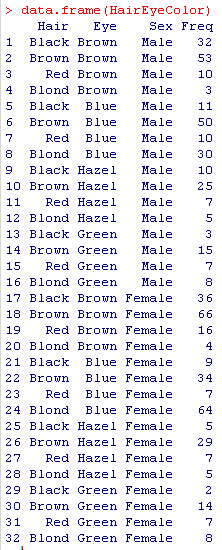
将三个维度分别作为 3 列,它们取值的组合正好就对应了第 4 列的人数度量(measure)。这样的显示不直观,而且各个维度的取值会重复显示多次,太累赘。而在 SPSS Statistics 中可以定义复杂的数据透视表(pivot table),例如在一个数据透视表中显示 HairEyeColor 的所有三个维度:
图 11. 透视表 (pivot table) 显示多维数据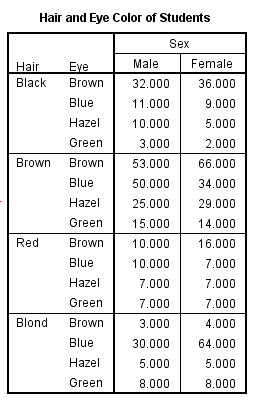
SPSS Statistics 中数据透视表的结构和各部分定义如图。
图 12. SPSS Statistics 中数据透视表的结构和定义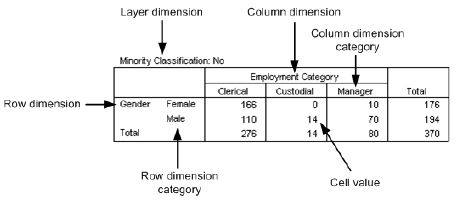
你可将多维数据中的一个或多个维度设定在任意的行维度、列维度或层维度上,这些维度的取值称作类别(category),而度量值放在单元(cell)中。依据以上数据透视表各个部分的定义,创建一个数据透视表包括以下四个基本步骤:
- 创建 BasicPivotTable 类的一个实例
- 增加维度
- 定义各个维度的类别
- 设置单元值
而各个步骤中需要调用相应的 SPSS Statistics 函数。这里是所有用于数据透视表显示的类和方法包括:
表 2. 显示数据透视表的类和方法
根据以上的步骤,使用数据透视表显示的函数,我们给出一个 R 语言代码的例子:
代码 4. SPSS Statistics 中显示数据透视表
- BEGIN PROGRAM R.
- spsspkg.StartProcedure("MyProcedure")
- demo <- data.frame(HairEyeColor)
-
- # 创建一个BasePivotTable的实例
- table = spss.BasePivotTable("Hair and Eye Color of Students", "OMS table subtype")
- # 增加三个维度:前两个行维度(Hair and Eye),最后一个列维度(Sex)
- dim1=BasePivotTable.Append(table,Dimension.Place.row,names(demo)[1])
- dim2=BasePivotTable.Append(table,Dimension.Place.row,names(demo)[2])
- dim3=BasePivotTable.Append(table,Dimension.Place.column,names(demo)[3])
- # 定义各个维度的类别
- ctg1=BasePivotTable.SetCategories(table,
- dim1,
- as.list(apply(as.matrix(levels(demo[[1]])),1,spss.CellText.String)))
- ctg2=BasePivotTable.SetCategories(table,
- dim2,
- as.list(apply(as.matrix(levels(demo[[2]])),1,spss.CellText.String)))
- ctg3=BasePivotTable.SetCategories(table,
- dim3,
- as.list(apply(as.matrix(levels(demo[[3]])),1,spss.CellText.String)))
- # 设置单元值
- MyCellFun <- function(x)
- cell = BasePivotTable.SetCellValue(
- table,
- list(spss.CellText.String(x[1]),
- spss.CellText.String(x[2]),
- spss.CellText.String(x[3])),
- spss.CellText.Number(as.numeric(x[4])))
- apply(demo, 1, MyCellFun)
-
- spsspkg.EndProcedure()
- END PROGRAM.
运行以上的语法代码就会获得前面的多维度数据透视表输出。应该注意的是,使用这些这些类和方法,需要在一个 Procedure 环境中,也就是必须以 spsspkg.StartProcedure() 为开始行,以 spsspkg.EndProcedure() 为结束行。
 的时候,雨也是晴;心雨
的时候,雨也是晴;心雨 的时候,晴也是雨!
的时候,晴也是雨!



 京公网安备 11010802022788号
京公网安备 11010802022788号







