



 雷达卡
雷达卡
















By Raymond Li.
Today, I’m going to explain in plain English the top 10 most influential data mining algorithms as voted on by 3 separate panels in thissurvey paper.
Once you know what they are, how they work, what they do and where you can find them, my hope is you’ll have this blog post as a springboard to learn even more about data mining.
What are we waiting for? Let’s get started!

Here are the algorithms:
- 1. C4.5
- 2. k-means
- 3. Support vector machines
- 4. Apriori
- 5. EM
- 6. PageRank
- 7. AdaBoost
- 8. kNN
- 9. Naive Bayes
- 10. CART
We also provide interesting resources at the end.
1. C4.5What does it do? C4.5 constructs a classifier in the form of a decision tree. In order to do this, C4.5 is given a set of data representing things that are already classified.
Wait, what’s a classifier? A classifier is a tool in data mining that takes a bunch of data representing things we want to classify and attempts to predict which class the new data belongs to.
What’s an example of this? Sure, suppose a dataset contains a bunch of patients. We know various things about each patient like age, pulse, blood pressure, VO2max, family history, etc. These are called attributes.
Now:
Given these attributes, we want to predict whether the patient will get cancer. The patient can fall into 1 of 2 classes: will get cancer or won’t get cancer. C4.5 is told the class for each patient.
And here’s the deal:
Using a set of patient attributes and the patient’s corresponding class, C4.5 constructs a decision tree that can predict the class for new patients based on their attributes.
Cool, so what’s a decision tree? Decision tree learning creates something similar to a flowchart to classify new data. Using the same patient example, one particular path in the flowchart could be:
- Patient has a history of cancer
- Patient is expressing a gene highly correlated with cancer patients
- Patient has tumors
- Patient’s tumor size is greater than 5cm
The bottom line is:
At each point in the flowchart is a question about the value of some attribute, and depending on those values, he or she gets classified. You can find lots of examples of decision trees.
Is this supervised or unsupervised? This is supervised learning, since the training dataset is labeled with classes. Using the patient example, C4.5 doesn’t learn on its own that a patient will get cancer or won’t get cancer. We told it first, it generated a decision tree, and now it uses the decision tree to classify.
You might be wondering how C4.5 is different than other decision tree systems?
- First, C4.5 uses information gain when generating the decision tree.
- Second, although other systems also incorporate pruning, C4.5 uses a single-pass pruning process to mitigate over-fitting. Pruning results in many improvements.
- Third, C4.5 can work with both continuous and discrete data. My understanding is it does this by specifying ranges or thresholds for continuous data thus turning continuous data into discrete data.
- Finally, incomplete data is dealt with in its own ways.
Why use C4.5? Arguably, the best selling point of decision trees is their ease of interpretation and explanation. They are also quite fast, quite popular and the output is human readable.
Where is it used? A popular open-source Java implementation can be found over at OpenTox. Orange, an open-source data visualization and analysis tool for data mining, implements C4.5 in their decision tree classifier.
Classifiers are great, but make sure to checkout the next algorithm about clustering…
2. k-meansWhat does it do? k-means creates k groups from a set of objects so that the members of a group are more similar. It’s a popular cluster analysis technique for exploring a dataset.
Hang on, what’s cluster analysis? Cluster analysis is a family of algorithms designed to form groups such that the group members are more similar versus non-group members. Clusters and groups are synonymous in the world of cluster analysis.
Is there an example of this? Definitely, suppose we have a dataset of patients. In cluster analysis, these would be called observations. We know various things about each patient like age, pulse, blood pressure, VO2max, cholesterol, etc. This is a vector representing the patient.
Look:
You can basically think of a vector as a list of numbers we know about the patient. This list can also be interpreted as coordinates in multi-dimensional space. Pulse can be one dimension, blood pressure another dimension and so forth.
You might be wondering:
Given this set of vectors, how do we cluster together patients that have similar age, pulse, blood pressure, etc?
Want to know the best part?
You tell k-means how many clusters you want. K-means takes care of the rest.
How does k-means take care of the rest? k-means has lots of variations to optimize for certain types of data.
At a high level, they all do something like this:
- k-means picks points in multi-dimensional space to represent each of the k clusters. These are called centroids.
- Every patient will be closest to 1 of these k centroids. They hopefully won’t all be closest to the same one, so they’ll form a cluster around their nearest centroid.
- What we have are k clusters, and each patient is now a member of a cluster.
- k-means then finds the center for each of the k clusters based on its cluster members (yep, using the patient vectors!).
- This center becomes the new centroid for the cluster.
- Since the centroid is in a different place now, patients might now be closer to other centroids. In other words, they may change cluster membership.
- Steps 2-6 are repeated until the centroids no longer change, and the cluster memberships stabilize. This is called convergence.
Is this supervised or unsupervised? It depends, but most would classify k-means as unsupervised. Other than specifying the number of clusters, k-means “learns” the clusters on its own without any information about which cluster an observation belongs to. k-means can be semi-supervised.
Why use k-means? I don’t think many will have an issue with this:
The key selling point of k-means is its simplicity. Its simplicity means it’s generally faster and more efficient than other algorithms, especially over large datasets.
It gets better:
k-means can be used to pre-cluster a massive dataset followed by a more expensive cluster analysis on the sub-clusters. k-means can also be used to rapidly “play” with k and explore whether there are overlooked patterns or relationships in the dataset.
It’s not all smooth sailing:
Two key weaknesses of k-means are its sensitivity to outliers, and its sensitivity to the initial choice of centroids. One final thing to keep in mind is k-means is designed to operate on continuous data — you’ll need to do some tricks to get it to work on discrete data.
Where is it used? A ton of implementations for k-means clustering are available online:
If decision trees and clustering didn’t impress you, you’re going to love the next algorithm.


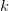 closest labeled training data points — in other words, the k-nearest neighbors.
closest labeled training data points — in other words, the k-nearest neighbors.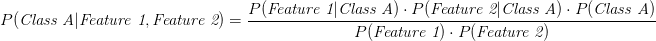

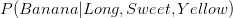
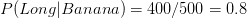
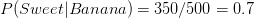
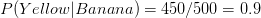
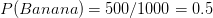
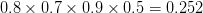
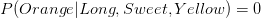
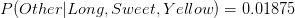
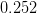 is greater than
is greater than 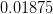 , Naive Bayes would classify this long, sweet and yellow fruit as a banana.
, Naive Bayes would classify this long, sweet and yellow fruit as a banana.

 京公网安备 11010802022788号
京公网安备 11010802022788号







