



 雷达卡
雷达卡




原文链接:
https://mp.weixin.qq.com/s/x6NIkzQSgvl0_rfGe7Cjqg
文章搬得好辛苦,很多图片,如果对你的学习有帮助,欢迎点赞和留言。
感谢大家,同时,感谢原作者。
导读:卷积神经网络(CNNs)在“自动驾驶”、“人脸识别”、“医疗影像诊断”等领域,都发挥着巨大的作用。这一无比强大的算法,唤起了很多人的好奇心。当阿尔法狗战胜了李世石和柯杰后,人们都在谈论“它”。
但是,
“它”是谁?
“它”是怎样做到的?
已经成为每一个初入人工智能——特别是图像识别领域的朋友,都渴望探究的秘密。
本文通过“算法可视化”的方法,将卷积神经网络的原理,呈献给大家。教程分为上、下两个部分,通篇长度不超过7000字,没有复杂的数学公式,希望你读得畅快。
下面,我们就开始吧!
先提一个小问题:
“你是通过什么了解这个世界的?”
当一辆汽车从你身边疾驰而过,你是通过哪些信息知道那是一辆汽车?
“它的材质,速度,发动机的声响,还是什么?”
你可能说不清所以然,但是当你看到下图时,你会第一时间反应出来,“噢,车! ”
为什么你能猜对它?
“轮廓”!
——对,我给你看了它的轮廓。
再给你一些七七八八、大小不一的图片,你总能猜对一些。
你是怎样做到的?
很简单
你读了一张图片 → 找到了图片的特征 → 进而对图片做出了分类
其实,CNNs的工作原理也是这样。
先不考虑那些复杂的专有名词:什么卷积(convolution)、池化(pooling)、过滤器(filter) 等等…… 统统抛到一边。
CNNs做的就是下面3件事:
1. 读取图片;
2. 提取特征;
3. 图片分类。
下面,我们逐一来看各步骤的细节。
如果是一张黑白图片,我们看到的,是这个样子的:
而在计算机的眼里,它看到的,是这个样子的:
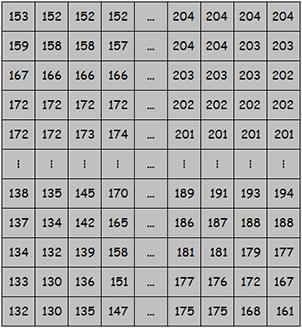
好没有情趣……
这些数字是哪里来的?
因为图片是由一个又一个的像素点构成。(当你将图片无限放大,你能看到那些像素点)
而每一个像素点,都是由一个0~255的数字组成。
所以,在计算机“看”来,一张图片,就是一个又一个的数字。
所以,我们第一步的工作,是将左上图的那只小狗,转换成右上图的那一行行数字。
幸运的是,目前在python中,很多第三方库,诸如PIL/Matplotlib等,都可以实现这种转换,我们需要了解的是,后面的所有运算过程,都是基于右上图来完成的,至于具体的转换过程,不需要我们费心来做。
在文章开篇的例子中,我们知道,在识别一辆汽车的时候,可以将它的轮廓提取出来,从而判断出那是一辆车。
同样的,CNNs在识别图片时,也需要提取图像的特征。
在CNNs中,完成这一工作的小伙叫“卷积”。(希望你不要纠结这个极具个性的名字,懂得它的原理就OK)
“卷积”在每次工作时,手里都会握着几把“过滤器”。

过滤器的作用是:寻找图片的特征。
仍以小狗为例,过滤器会在图片上从头到尾“滑过”一遍
每滑到一个地方,就将该地方的图像特征提取出来。
那它是怎样提取的呢?
别忘了,在计算机的眼里,世界是这个样子的:
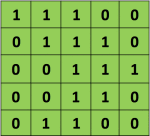
(为了简化问题,这里将像素值仅用0和1表示)
假设过滤器是这个样子的:
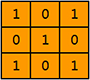
当橘色的过滤器在绿色矩形框中,缓慢滑过时,
我们用橘色过滤器中的每一个值,与绿色矩形框中的对应值相乘、再相加
有点儿拗口,直接看图:
结果“4”,就是我们从第一个橘色方框中,提取出的特征。
如果我们每次将橘色过滤器,向右、向下移动1格,则提取出的特征为:
你可能会问:
我知道绿色矩阵代表一张图片,是计算机“眼中”图片的样子。
但是,
经过橘色过滤器提取特征后,得到的粉色矩阵,那是什么?
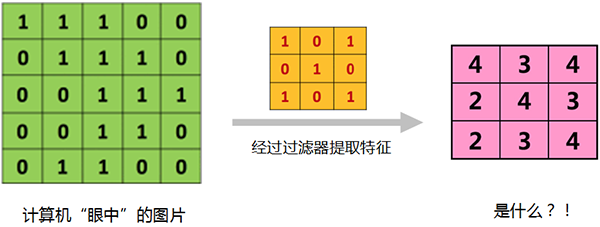
我们从人类的视角,再重新审视一遍。
这次,我们回到之前的例子中。
仍以这张萌狗为例,它经过“过滤器”提取特征后,得到的是一张……哦,好吧……看起来有点儿模糊的图。
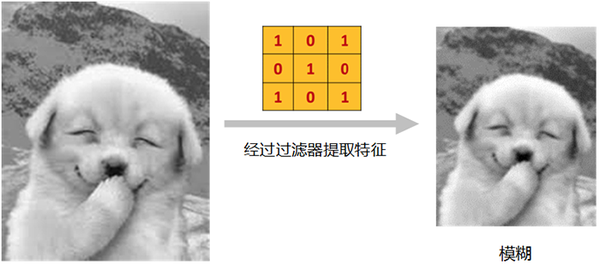
虽然图片模糊了,但是图片中的主要特征,已经被过滤器全部提取出来,单凭这么一张模糊的图,作为人类的我们,足以对它做出判断了。(谁敢说它是一只猫?!)
下面,我们再换几个过滤器试试。
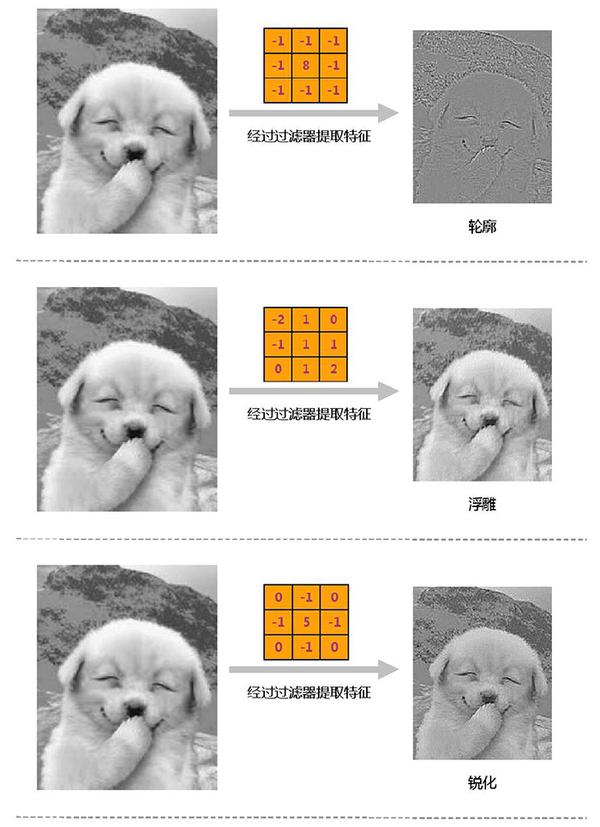
这些就是经过过滤器提取后,得到的不同“特征图片”。
由此我们可以看出,采用不同的“过滤器”,能够提取出不同的图片特征。
你可能又会问:
那过滤器里的数值,该如何确定呢?
。。。。。论坛字数限制,不让我发了,等哪天有时间,我再开一帖吧。






 京公网安备 11010802022788号
京公网安备 11010802022788号







