


 雷达卡
雷达卡





CDA数据分析师:数据科学、人工智能从业者的在线大学。
数据科学(Python/R/Julia)数据分析、机器学习、深度学习 Q群:874447702
常见的文本检索方案有哪些?
(1)数据库LIKE法
将标题数据存放在数据库中,使用like来查询,方案非常简单,能支持简单的模糊搜索,但不支持分词。
画外音:显然不适用于本例。
(2)数据库全文检索法
将标题数据存放在数据库中,建立全文索引来检索,方然依然简单,利用了数据库的能力,不用额外开发,但性能较低。
画外音: 本例的并发肯定扛不住。
(3)开源方案索引外置 法
搭建lucene,solr,ES等开源搜索工具,建立索引,支持分词,支持数据量和吞吐量的水平扩展。
该方案能够很好的满足本例的需求。但是,杀鸡焉用牛刀,本例有一些业务特性: 文本短,更新不频繁 ,如果利用好这两个特点,能有更巧妙的方案。

画外音: 任何脱离业务的架构设计,都是耍流氓。
针对“更新不频繁”的特性 ,可以使用“ 分词+DAT ”方案。
画外音:分词就不多说了。
什么是DAT?
DAT是double array trie的缩写,是trie树的一个变体优化数据结构,它在保证trie树检索效率的前提下,能大大减少内存的使用,经常用来解决检索,信息过滤等问题。
画外音:更具体的,可以Google一下“DAT”,DAT的缺点是,需要提前建立索引,索引不能实时更新。

为什么用trie树的变种DAT, 是否可以 直接使用trie树呢?
trie树的优点是,索引可以实时更新;不足是,占用内存非常大。
本例索引无需实时更新,无法利用trie树的优点。但是,如果300W短文本建立好trie树内存能装下,则可以使用trie树,否则只能使用DAT。
普及, 什么是trie树?
trie树,又称单词查找树,经常 用于搜索引擎词频统计,短文本检索,输入法输入提示等。
画外音:什么数据结构适合什么业务场景,一定要烂熟于胸。
它的特点是,能利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较, 其查询时间复杂度只与树的高度有关,与查询数据量级无关 ,因此查询效率非常高。
画外音:“时间复杂度与查询数量级无关”这个太屌了。
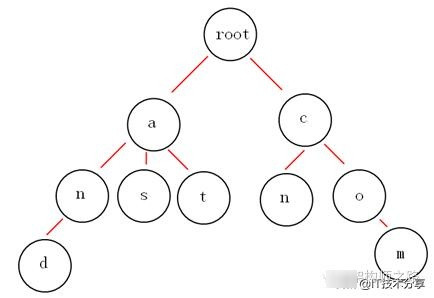
例如: 上面的trie树就能够表示{and, as, at, cn, com}这样5个标题的集合,可以用来做这5个字符串的词频统计,或者检索。
画外音:检索时,节点存储命中该item的doc_list。
分词之后,是不是需要多次扫描trie树?
是的。
分词之后,每个item都要扫描一次trie树,得到的doc_list的交集,就是最终命中每个item的检索结果。
针对“短文本”“500W数据”“不频繁更新”这些特性 ,还能使用“ 分词+内存hash ”方案。
这个方案需要 先对索引进行初始化 :
对所有短文本进行分词,以词的hash为key,doc_id的集合为value。
查询的过程 也很简单:
对查询字符串进行分词,对每个分词进行hash,直接查询hash表格得到doc_list,再对每个分词的检索结果进行交集。
举个栗子进行说明。
例如:
doc1 : 我爱北京
doc2 : 我爱到家
doc3 : 到家美好
先对短文本进行分词:
doc1 : 我爱北京 -> 我,爱,北京
doc2 : 我爱到家 -> 我,爱,到家
doc3 : 到家美好 -> 到家,美好
对分词进行hash,建立hash表:
hash(我) -> {doc1, doc2}
hash(爱) -> {doc1, doc2}
hash(北京) -> {doc1}
hash(到家) -> {doc2, doc3}
hash -> {doc3}
这样,所有短文本初始化完毕,与trie树类似,查询时间复杂度与文本数据量也没有关系。
画外音:只与被分词后有多少数据量,即hash桶个数有关。
查询的过程是这样的:
假如用户输入“我爱”,分词后变为{我,爱},对各个分词的hash进行内存检索
hash(我)->{doc1, doc2}
hash(爱)->{doc1, doc2}
然后进行合并,得到最后的查找结果是{doc1, doc2}。
这个方法的 优点 是, 纯内存操作,能满足很大的并发,时延也很低,占用内存也不大,实现非常简单快速,而且冗余索引很容易水平扩展。

画外音: 做索引高可用也不难,建立两份一样的hash索引即可。
它的 缺点 也很明显,索引全内存, 没有落地,还是需要在数据库中存储固化的短文本数据,如果内存数据全丢失,数据恢复起来会比较慢。
总结
短文本,高并发,支持分词,不用实时更新的检索场景,可以使用:
(1)ES,杀鸡用牛刀;
(2)分词+DAT(trie);
(3)分词+内存hash;
等几种方式解决。
思路比结论重要 ,希望大家有收获。


 京公网安备 11010802022788号
京公网安备 11010802022788号







