


 雷达卡
雷达卡






周末,小迪与女朋友小西走出电影院,回味着刚刚看过的电影。
小迪:刚刚的电影很精彩,打斗场景非常真实,又是一部优秀的动作片!
小西:是吗?我怎么感觉这是一部爱情片呢?真心被男主女主的爱情感动了,唔。。。
小迪:是动作片好不好?不信的话我们用K近邻来分类!
小西:K近邻是什么,怎么分类?
小迪:我们以接吻镜头与打斗镜头作为两种电影的特征,只要知道一部电影的接吻镜头与打斗镜头的个数,利用现有的带标签数据集便可以对未知类型的电影进行类型预测。
小西:不是很明白,可以讲简单点吗?
小迪:我们可以这样理解,假设有一个未知的x,我们尽量让特征相近的的点靠近,这样想要知道x是什么性质的,我们可以观察它邻近的k个点,这些点多数是什么性质的,那么x的性质也就是可以预测出来了。
小西:哦哦,明白了。有点像那句俗语——物以类聚人以群分呢!
小迪:是啊,是有这么个意思!我们回去用python实现一下这个算法吧。
小西:好的,走!
K近邻算法概述k-近邻算法(k-Nearest Neighbour algorithm),又称为KNN算法,是数据挖掘技术中原理最简单的算法。KNN的工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类别。

如上图中有红色三角和蓝色方块两种类别,现在需要判断绿色圆点属于哪种类别
当k=3时,绿色圆点属于红色三角这种类别;
当k=5时,绿色圆点属于蓝色方块这种类别。
K近邻分类电影类型小迪回到家,打开电脑,想实现一个分类电影的案例。于是他找了几部前段时间比较热门的电影,然后根据接吻镜头与动作镜头打上标签,用k-近邻算法分类一个电影是爱情片还是动作片(打斗镜头和接吻镜头数量为虚构)。
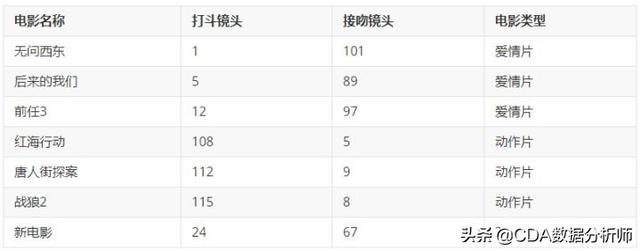
表中就是已有的数据集合,也就是训练样本集。这个数据集有两个特征——打斗镜头数和接吻镜头数。除此之外,每部电影的所属类型也是已知的,即分类标签。粗略看来,接吻镜头多的就是爱情片,打斗镜头多的就是动作片。多年来的经验就是如此。如果现在有一部新的电影,告知电影中的打斗镜头和接吻镜头分别是多少,那么多数人可以根据给出的信息进行判断,这部电影是属于爱情片还是动作片。而k-近邻算法也可以像人类一样做到这一点。但是,这仅仅是两个特征,如果特征变成10,100,1000甚至更多,恐怕人类就难以完成这样的任务了。但是有了算法的计算机是不怕疲劳而且精于计算的,这样的问题可以轻松解决!
已经知道k-近邻算法的工作原理,根据特征比较,然后提取样本集中特征最相似数据(最近邻)的分类标签。那么如何进行比较呢?比如表中新出的电影,该如何判断它所属的电影类别呢?如下图所示。
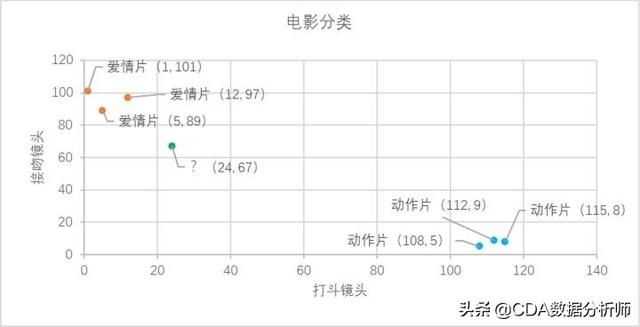
从散点图中大致推断,这个未知电影有可能是爱情片,因为看起来距离已知的三个爱情片更近一点。而在k-近邻算法中是利用距离进行判断的。这个电影分类例子中有两个特征,也就是在二维平面中计算两点之间的距离,这很容易可以联想到中学时代学过的距离公式:

如果是多个特征扩展到N维空间,怎么计算?可以使用欧氏距离(也称欧几里得度量),如下所示:
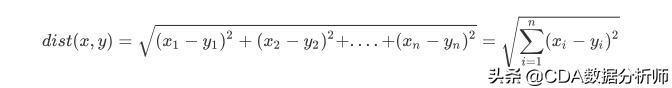
通过计算可以得到训练集中所有电影与未知电影的距离,如下表所示:

通过上面表中的计算结果,小迪知道绿点标记的电影到爱情片《后来的我们》距离最近,为29.1。如果仅仅根据这个结果,判定绿点电影的类别为爱情片,是不是这样呢?答案是不是,这个算法叫做最近邻算法,只看距离最近的一个点,而不是k个点,所以不是k-近邻算法。k-近邻算法步骤如下:
(1) 计算已知类别数据集中的点与当前点之间的距离;
(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的k个点;
(4) 确定前k个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测类别。
小迪设定K=4,那么在这个电影例子中,把距离按照升序排列,距离绿点电影最近的前4个的电影分别是《后来的我们》、《前任3》、《无问西东》和《红海行动》,这四部电影的类别统计为爱情片:动作片=3:1,出现频率最高的类别为爱情片,所以在k=4时,绿点电影的类别为爱情片。这个判别过程就是k-近邻算法。
K近邻算法的Python实现1. 算法实现
1.1构建已经分类好的原始数据集
为了方便验证,这里使用python的字典dict构建数据集,然后再将其转化成DataFrame格式。
import pandas as pd
rowdata={'电影名称':['无问西东','后来的我们','前任3','红海行动','唐人街探案','战狼2'],
'打斗镜头':[1,5,12,108,112,115],
'接吻镜头':[101,89,97,5,9,8],
'电影类型':['爱情片','爱情片','爱情片','动作片','动作片','动作片']}
movie_data= pd.DataFrame(rowdata)
movie_data
1.2计算已知类别数据集中的点与当前点之间的距离
new_data = [24,67]
dist = list((((movie_data.iloc[:6,1:3]-new_data)**2).sum(1))**0.5)
dist
1.3将距离升序排列,然后选取距离最小的k个点
dist_l = pd.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])})
dr = dist_l.sort_values(by = 'dist')[: 4]
dr
1.4确定前k个点所在类别的出现频率
re = dr.loc[:,'labels'].value_counts()
re
1.5选择频率最高的类别作为当前点的预测类别
result = []
result.append(re.index[0])
result
2. 封装函数
完整的流程已经实现了,下面我们需要将这些步骤封装成函数,方便我们后续的调用。
import pandas as pd
"""
函数功能:KNN分类器
参数说明:
new_data:需要预测分类的数据集
dataSet:已知分类标签的数据集(训练集)
k:k-近邻算法参数,选择距离最小的k个点
返回:
result:分类结果
"""
def classify0(inX,dataSet,k):
result = []
dist = list((((dataSet.iloc[:,1:3]-inX)**2).sum(1))**0.5)
dist_l = pd.DataFrame({'dist':dist,'labels':(dataSet.iloc[:, 3])})
dr = dist_l.sort_values(by = 'dist')[: k]
re = dr.loc[:, 'labels'].value_counts()
result.append(re.index[0])
return result
测试函数运行结果
inX = new_data
dataSet = movie_data
k = 3
classify0(inX,dataSet,k)
这就是我们使用k-近邻算法构建的一个分类器,根据我们的“经验”可以看出,分类器给的答案还是比较符合我们的预期的。
算法总结小迪:k近邻算法虽然是机器学习算法中最简单的算法,没有之一,但是它确实也是蛮厉害呢!
小西:是呀,没想到这么简单的算法还有这么厉害的作用呢!那是不是这种算法永远不会出错呢?
小迪:那当然不是啦。没有哪个模型是完美的。分类器并不会得到百分百正确的结果,我们可以使用很多种方法来验证分类器的准确率。此外,分类器的性能也会受到很多因素的影响,比如k的取值就在很大程度上影响了分类器的预测结果,还有分类器的设置、原始数据集等等。为了测试分类器的效果,我们可以把原始数据集分为两部分,一部分用来训练算法(称为训练集),一部分用来测试算法的准确率(称为测试集)。同时,我们不难发现,k-近邻算法没有进行数据的训练,直接使用未知的数据与已知的数据进行比较,得到结果。因此,可以说,k-近邻算法不具有显式的学习过程。
小西:原来如此,今天还是收获满满呢!
总结
1. 优点
- 简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归可用于数值型数据和离散型数据无数据输入假定适合对稀有事件进行分类
2. 缺点
- 计算复杂性高;空间复杂性高;计算量太大,所以一般数值很大的时候不用这个,但是单个样本又不能太少,否则容易发生误分。样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)可理解性比较差,无法给出数据的内在含义
小迪跟小西有一个好朋友叫小艾。小艾与小迪是同事,在一家公司做数据分析。
小艾一直使用在线约会网站寻找适合自己的约会对象,尽管约会网站会推荐不同的人选,但他并不是每一个都喜欢,经过一番总结,她发现曾经交往的对象可以分为三类:
- 不喜欢的人魅力一般的人极具魅力得人
小艾收集约会数据已经有了一段时间,他把这些数据存放在文本文件datingTestSet.txt中,其中各字段分别为:
- 每年飞行常客里程玩游戏视频所占时间比每周消费冰淇淋公升数
1. 准备数据
datingTest = pd.read_table('datingTestSet.txt',header=None)
datingTest.head()
datingTest.shape
http://datingTest.info()
2. 分析数据
小艾使用 Matplotlib 创建散点图,查看各数据的分布情况。
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
#把不同标签用颜色区分
Colors = []
for i in range(datingTest.shape[0]):
m = datingTest.iloc[i,-1]
if m=='didntLike':
Colors.append('black')
if m=='smallDoses':
Colors.append('orange')
if m=='largeDoses':
Colors.append('red')
#绘制两两特征之间的散点图
plt.rcParams['font.sans-serif']=['Simhei'] #图中字体设置为黑体
pl=plt.figure(figsize=(12,8))
fig1=pl.add_subplot(221)
plt.scatter(datingTest.iloc[:,1],datingTest.iloc[:,2],marker='.',c=Colors)
plt.xlabel('玩游戏视频所占时间比')
plt.ylabel('每周消费冰淇淋公升数')
fig2=pl.add_subplot(222)
plt.scatter(datingTest.iloc[:,0],datingTest.iloc[:,1],marker='.',c=Colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('玩游戏视频所占时间比')
fig3=pl.add_subplot(223)
plt.scatter(datingTest.iloc[:,0],datingTest.iloc[:,2],marker='.',c=Colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('每周消费冰淇淋公升数')
plt.show()
3. 数据归一化
下表是提取的4条样本数据,小艾想要计算样本1和样本2之间的距离,于是使用欧几里得计算公式:

小艾发现,上面公式中差值最大的属性对计算结果的影响最大,也就是说每年飞行常客里程对计算结果的影响远远大于其他两个特征,原因仅仅是因为它的数值比较大,但是在小艾看来这三个特征是同等重要的,所以接下来要进行数值归一化的处理,使得这三个特征的权重相等。
数据归一化的处理方法有很多种,比如0-1标准化、Z-score标准化、Sigmoid压缩法等等,在这里使用最简单的0-1标准化,公式如下:

函数功能:归一化
参数说明:
dataSet:原始数据集
返回:0-1标准化之后的数据集
"""
def minmax(dataSet):
minDf = dataSet.min()
maxDf = dataSet.max()
normSet = (dataSet - minDf )/(maxDf - minDf)
return normSet
小艾将数据集带入函数,进行归一化处理
datingT = pd.concat([minmax(datingTest.iloc[:, :3]), datingTest.iloc[:,3]], axis=1)
datingT.head()
4. 划分训练集和测试集
为了测试分类器的效果,小艾把原始数据集分为训练集和测试集两部分,训练集用来训练模型,测试集用来验证模型准确率。
关于训练集和测试集的切分函数,网上有很多,Scikit Learn官网上也有相应的函数比如modelselection 类中的traintest_split 函数也可以完成训练集和测试集的切分。
通常只提供已有数据的90%作为训练样本来训练模型,其余10%的数据用来测试模型。这里需要注意的10%的测试数据一定要是随机选择出来的,由于小艾提供的数据并没有按照特定的目的来排序,所以这里可以随意选择10%的数据而不影响其随机性。
"""
函数功能:切分训练集和测试集
参数说明:
dataSet:原始数据集
rate:训练集所占比例
返回:切分好的训练集和测试集
"""
def randSplit(dataSet,rate=0.9):
n = dataSet.shape[0]
m = int(n*rate)
train = dataSet.iloc[:m,:]
test = dataSet.iloc[m:,:]
test.index = range(test.shape[0])
return train,test
train,test = randSplit(datingT)
train
test
5. 分类器针对于约会网站的测试代码
接下来,小艾开始构建针对于这个约会网站数据的分类器,上面已经将原始数据集进行归一化处理然后也切分了训练集和测试集,所以函数的输入参数就可以是train、test和k(k-近邻算法的参数,也就是选择的距离最小的k个点)。
"""
函数功能:k-近邻算法分类器
参数说明:
train:训练集
test:测试集
k:k-近邻参数,即选择距离最小的k个点
返回:预测好分类的测试集
"""
def datingClass(train,test,k):
n = train.shape[1] - 1
m = test.shape[0]
result = []
for i in range(m):
dist = list((((train.iloc[:, :n] - test.iloc[i, :n]) ** 2).sum(1))**5)
dist_l = pd.DataFrame({'dist': dist, 'labels': (train.iloc[:, n])})
dr = dist_l.sort_values(by = 'dist')[: k]
re = dr.loc[:, 'labels'].value_counts()
result.append(re.index[0])
result = pd.Series(result)
test['predict'] = result
acc = (test.iloc[:,-1]==test.iloc[:,-2]).mean()
print(f'模型预测准确率为{acc}')
return test
最后,测试上述代码能否正常运行,使用上面生成的测试集和训练集来导入分类器函数之中,然后执行并查看分类结果。
datingClass(train,test,5)
从结果可以看出,小艾的模型准确率还不错,这是一个不错的结果了,离找女朋友更近了一步。

关注“CDA人工智能学院”,回复“录播”获取更多人工智能精选直播视频!





 京公网安备 11010802022788号
京公网安备 11010802022788号







