


 雷达卡
雷达卡






CDA人工智能学院致力于以优质的人工智能在线教育资源助力学员的DT职业梦想!课程内容涵盖数据分析、机器学习、深度学习、人工智能、tensorFlow、PyTorch、知识图谱等众多核心技术及行业案例,让每一个学员都可以在线灵活学习,快速掌握AI时代的前沿技术。PS:私信我即可获取《银牌会员》1个月免费试听机会
1、问题与数据
在某胃癌筛查项目中,研究者想了解首诊胃癌分期(Stage)与患者的经济水平的关系,以确定胃癌筛查的重点人群。为了避免性别因素对结论的混杂影响,研究者将性别(Sex)也纳入分析(本例仅为举例说明如何进行软件操作,实际研究中需控制的混杂因素可以更多)。研究者将所有筛查人群的结果如表1,变量赋值如表2。
表1. 原始数据

表2. 变量赋值情况
2、对数据结构的分析
该设计中,因变量为四分类,且分类间有次序关系,针对因变量为分类型数据的情况应该选用Logistic回归,故应采用有序多分类的Logistic回归分析模型进行分析。
有序多分类的Logistic回归原理是将因变量的多个分类依次分割为多个二元的Logistic回归,例如本例中因变量首诊胃癌分期有1-4期,分析时拆分为三个二元Logistic回归,分别为(1 vs 2+3+4) 、(1+2 vs 3+4)、(1+2+3 vs 4),均是较低级与较高级对比。需注意的是,有序多分类Logistic回归的假设是,拆分后的几个二元Logistic回归的自变量系数相等,仅常数项不等。其结果也只输出一组自变量的系数。
因此,有序多分类的Logistic回归模型中,必须对自变量系数相等的假设进行检验(又称平行线检验)。如果不满足平行线假设,则考虑使用无序多分类Logistic回归或其他统计方法。
3、SPSS分析方法
(1)数据录入SPSS
首先在SPSS变量视图(Variable View)中新建四个变量:ID代表患者编号,Sex代表性别,Income代表收入水平,Stage代表首诊胃癌分期。赋值参考表1。然后在数据视图(Data View)中录入数据。
(2)选择Analyze → Regression → Ordinal Logistic
(3)选项设置
将因变量Stage放入因变量(Dependent)位置,自变量性别(Sex)、收入水平(Income)为分类变量,故放入因子(Factors)位置。若研究中还有连续型变量需要调整,则放入协变量(Covariate)位置。
点击输出(Output)选项,勾选平行线检验(Test of parallel lines)。其余选项维持默认。点击确定(OK)。
4、结果解读
(1)Case Processing Summary
给出的是数据的一般情况,这里不进行介绍。
(2)模型拟合优度检验
有两个,一个是似然比检验结果(Model Fitting Information).该检验的原假设是所有纳入自变量的系数为0,P(Sig.)<0.001,说明至少一个变量系数不为0,且具有统计学显著性。也就是模型整体有意义。
另一个结果是拟合优度检验(Goodness-of-Fit)结果,提供了Pearson卡方和偏差(Deviance)卡方两个检验结果。但是,这两个检验结果不如上图的似然比检验结果稳健,尤其是纳入的自变量存在连续型变量时,因此推荐以似然比检验结果为准。
(3)伪决定系数(Pseudo R-Square)
对于分类数据的统计分析,一般情况下伪决定系数都不会很高,对此不必在意。
(4)参数估计(Parameter Estimates)
阈值(Threshold)对应的Stage=1,2,3三个估计值(Estimate)分别是本次分析中拆分的三个二元Logistic回归的常数项。位置(Location)中Sex和Income变量对应的参数估计值为自变量的估计值。其中Income为多分类,在分析中被拆分成了三个哑变量(即Income 取值1、2、3),分别与Income=4的组进行对比。且有序多分类Logistic回归假定拆分的多个二元回归中自变量系数均相等,因此结果只给出了一组自变量系数。
Income=1系数估计值(Estimate)为-1.617意味着,在调整性别变量的情况下,Income=1(即收入水平最低)的组,相比于Income=4(收入水平最高)的组,初诊胃癌分期至少高一个等级的可能性是exp(-1.617)=0.198倍。其他系数解释相同。这说明,收入水平高的人群,其初诊胃癌时病情更严重。
Sex变量系数无统计学意义(P=0.428),如果没有其他证据证明不同性别的初诊胃癌分期有区别,那么从模型精简的角度考虑,应当将Sex变量从模型中去掉再次进行回归,得到收入水平的参数估计值。如果研究者比较肯定不同性别初诊胃癌分期会产生区别,那么即使在本研究中其系数无统计学意义也应保留在模型中(因为无统计学意义有可能是因为样本量小造成的,并不能说明该变量不产生影响)。本研究中予以保留。
(5)平行线假设检验(Test of Parallel Lines)
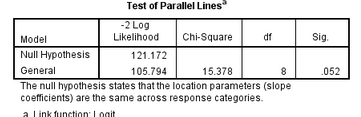
该检验的原假设是三个二元Logistic回归自变量系数相等,检验P(Sig.)值为0.052,不拒绝原假设,可以认为假设成立,可以使用多重有序Logistic回归。如果将参数无统计学意义的Sex变量去掉,会发现平行线假定检验P值会增大(P=0.175)(是否去掉Sex变量重回归,取决于是否有充足研究证据证明Sex是一个混杂变量,如果是,Sex变量应保留在模型中)。
5、结果汇总
胃癌患者的初诊分期与患者的收入水平有关。低等收入、中等收入与中高等收入人群与高等收入人群相比,初诊胃癌分期高至少一个等级的可能性分别为0.198(P<0.001)、0.310(P<0.001)、0.640(P=0.071)倍。
关注“CDA人工智能学院”,回复“录播”获取更多人工智能精选直播视频!




 京公网安备 11010802022788号
京公网安备 11010802022788号







