


 雷达卡
雷达卡



摘要
大型语言模型能否掌握空间导航能力?为探究这一问题,我们对 GPT-2 模型在三类网格环境下的训练表现进行了系统研究:被动探索(觅食模型,用于预测随机游走中的下一步)、目标导向规划(SP-Hamiltonian,基于结构化哈密顿路径生成最短路径)以及结合探索数据微调的混合策略(SP-Random Walk)。通过行为、表征与机制三个层面的分析,我们识别出两种截然不同的学习范式。觅食模型发展出一种稳健的、类似“认知地图”的空间表征体系,其内部构建了一个自洽的坐标系统。因果干预实验显示,该模型在中间网络层便不再依赖历史方向输入,表现出明显的相变特征。此外,它具备一种分层推理机制,能够根据上下文长度动态切换——在短序列中使用低级启发式,在长序列中启用基于地图的推理。相比之下,目标导向模型则始终依赖显式的方向信息,在所有网络层级中维持路径相关的计算策略。尽管混合模型在泛化性能上优于其基础模型,但仍延续了相同的路径依赖机制。这些结果揭示了 Transformer 架构中空间智能可能存在于一个连续谱系:一端是由探索性数据驱动的可泛化世界模型,另一端是为目标优化而生的局部启发式方法。我们进一步从机制角度解释了这种泛化与优化之间的权衡,并强调训练数据的设计如何决定最终涌现的认知策略。
1 引言
尽管仅通过下一个令牌预测(NTP)任务进行训练,大型语言模型仍展现出令人惊讶的空间导航能力,而该任务本身并未包含明确的规划机制 [bachmann2024ntp, nolte2024spatial, dedieu2024]。这一现象构成了理解基础模型 emergent 能力的核心挑战。现有观点认为,NTP 可能诱导模型习得脆弱的统计启发式:这些模式虽能在分布内模拟规划行为,却难以向外泛化 [bachmann2024ntp, dziri2023faithfatelimitstransformers]。然而,NTP 的实际效果高度依赖于训练数据的统计特性 [spens2024consolidation]。例如,探索性质的数据(如随机游走)可能促使模型建立内在的世界模型以降低预测误差;而目标导向型数据则更可能催生受限的映射规则,使模型直接将上下文转化为解决方案,无需真正理解空间结构。要验证这一假设,必须超越传统的行为测试,转向机制可解释性的深度分析,即揭示模型内部所采用的算法逻辑 [davies2024cognitive]。虽然“电路”研究范式已在识别上下文学习 [olsson2022context] 和算法推理 [nanda2023progress, trigonometry] 等功能方面取得进展,但空间推理领域的神经机制探索仍处于起步阶段,具有重要发现潜力。
为此,我们设计了一项对照实验,比较在探索性随机游走(觅食模型)和最短路径生成任务(SP 模型)上分别训练的 GPT-2 模型。综合行为与机制分析,我们得出以下发现:(1)觅食模型形成了可迁移的空间表征,并能依据上下文信息灵活调整策略——从局部启发式过渡到全局地图式推理,表现出类似“认知地图”的特性 [BEHRENS2018490];(2)SP 模型掌握了一套高效但受限的算法,其性能紧密绑定于特定训练设置;(3)通过因果干预手段,我们识别出不同的内部工作机制,包括早期层中存在的局部空间更新回路,以及从第 8 层起出现的独立、完整的空间编码系统。
2 方法
2.1 训练框架
我们采用 Spens & Burgess 提出的建模方式,使用一个 4×4 的网格空间进行实验,每个节点由两个字母组成的标识符命名(如 aq、px),移动动作通过基本方向令牌实现(NORTH, SOUTH, EAST, WEST)[spens2024consolidation, whittington2020tolman]。所有模型均基于 GPT-2 small 架构(含 1.24 亿参数)执行因果语言建模任务。
觅食模型在长度为 120 步的随机游走轨迹上进行训练,目标是预测序列中下一个合法的方向-节点对。SP 模型则被训练用于主动规划任务:给定一段部分或完整揭示网格结构的上下文路径,模型需生成从指定起点到终点的最短路径。
其中,SP-Hamiltonian 模型(简称 SP-H)的上下文来自访问全部 16 个节点且每个节点仅出现一次的哈密顿路径,确保提供完整空间信息。SP-Random Walk 模型(SP-RW)则是在 SP-H 基础上进一步微调,使用 10 至 50 步的部分随机游走作为上下文输入,同时保证所有最短路径涉及的节点均已出现在上下文中。该设计有效分离了任务目标与数据结构的影响因素。
两种 SP 模型均应用损失掩码技术,仅对有效路径生成部分进行优化,避免模型过度关注上下文重建。所有模型均在一百万个随机生成的网格实例上训练,并配备自定义 BPE 分词器。详细的训练配置参见附录 A。
2.2 分析框架
我们的分析体系整合了三种相互补充的技术路径:
行为评估
通过导航准确性、跨情境泛化能力及全局空间理解任务来衡量模型的空间推理水平(详见附录 B)。
表征分析
利用探针分类器、相似性度量与降维可视化等手段,解析隐藏状态中空间信息的编码方式与演化过程。
3 结果
3.1 行为性能分析
觅食模型在空间泛化方面表现出最强的鲁棒性。其在未见过的更大网格上依然保持优异表现,例如在 5×5 网格中实现了 98.3% 的下一步预测准确率,并能完成需要全局理解的任务——如哈密顿环闭合,准确率达到 100%,即模型能够正确推断出访问所有节点后返回起点的路径。
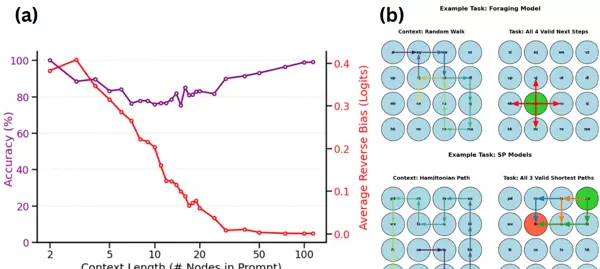
值得注意的是,该模型的行为随上下文长度(即用于预测下一步的历史步数)发生显著变化(见图 1a)。当上下文长度为 2-3 步时,模型达到 100% 准确率,且强烈倾向于逆转上一步的方向(logits 偏向为 0.114,定义见附录 B.2);随着上下文延长至约 11 步,准确率下降至 71%,方向偏向也减弱至 0.029;而当上下文超过 30 步时,准确率回升至 >96%,同时方向逆转偏好几乎消失。这一趋势表明:模型初始依赖局部启发式策略,在获得更长轨迹信息后转向基于整体结构的空间推理。
相比之下,SP-H 模型虽然在其训练分布内任务中表现完美(在长度为 16 的哈密顿路径上下文中进行最短路径预测,准确率达 100%),但泛化能力极弱。它在多数新任务中失败,例如在 5×5 网格上的边到边路径预测中仅得 3.6%,其他上下文长度下均为 0%。SP-RW 模型则处于中间状态,在 10 至 50 步的上下文范围内维持 >97% 的准确率。它在 5×5 和 6×6 网格上实现了部分泛化(平均准确率分别为 42.2% 和 17.38%),对简单路径任务(如边到边移动)成功率达 78%,但在超出训练期间最大曼哈顿距离(MD > 6)的路径上表现不佳(准确率仅为 28.6%)。更多详细结果参见附录 B 中的图 4。
图 1:
? (a) 随着上下文长度增加,觅食模型导航策略的演变。紫色线表示单步预测准确率;红色线反映对逆转前一方向的偏好程度。从高逆转偏向向均匀预测的转变,揭示了从局部启发式行为向全局空间推理的过渡。(b) 两个模型示例任务对比。顶部:觅食模型以随机游走作为输入上下文(左),并预测有效的下一步动作(右,红色箭头所示)。底部:SP-H 模型使用哈密顿路径作为上下文(左,蓝色箭头),目标是推断起始(红色)与终点(绿色)之间的最短路径(右,展示多条可能路径)。
3.2 表征分析
通过对节点令牌隐藏状态进行主成分分析(PCA),结合线性探测方法(详见附录 C 和 D.1),我们发现了不同模型间显著差异的表征结构(见图 2)。
觅食模型展现出三阶段的空间表征演化过程。在早期网络层(第 1–3 层),位置信息较为模糊和嘈杂。到第 7 层,节点表征逐渐形成清晰的空间布局:前两个主成分分别与网格的 x 和 y 轴高度对齐(余弦相似度 ≈ –0.0415),呈现出一种正交、类似笛卡尔坐标系的空间编码机制,且该机制独立于序列历史 [spens2024consolidation]。线性探测进一步验证了这一点——节点坐标可从隐藏状态中线性解码,并在第 8 层趋于稳定(R ≈ 0.93)。进入后期层(第 11–12 层),表征出现功能性的聚类现象:角点节点各自形成独立簇,边缘节点按共享移动方向聚合,中心节点则汇聚为一个统一簇,反映出完全自由的运动潜力(详见附录 C)。
相反,SP 类模型未能发展出类似的异中心空间结构。SP-H 模型在整个网络中均表现出明显的水平镜像效应:在 4×4 网格中沿中央水平轴对称的位置(如 (0,0) 与 (0,2),(2,0) 与 (2,2))在 PCA 空间中高度聚集(见图 2 右),说明其采用了一种脆弱的压缩策略,利用了哈密顿训练数据中的对称特性。SP-RW 模型则介于两者之间:其早期层呈现类似于觅食模型的噪声化网格结构,但该结构并未进一步收敛为精确地图,而是持续存在于中间层,最终在第 12 层坍缩为压缩的列状结构,暗示可能存在无法通过线性降维揭示的非线性有效组织形式。
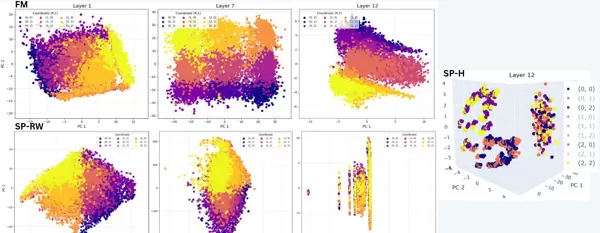
图 2:
? 左侧:觅食模型(上)与 SP-RW 模型(下)的 PCA 对比。数据基于 3x3 网格上的 1000 条独特 50 步随机游走采样,节点表征在所有出现次数上取平均,各点按真实网格坐标着色。右侧:SP-Hamiltonian 模型中的水平镜像效应。具有水平对称关系的坐标在 PCA 投影中紧密聚集,表明其对称性被编码进表征空间。
机制分析
为了识别关键计算角色并追踪信息整合路径,我们采用了因果干预手段,包括分层消融、注意力模式分析以及激活补丁技术(详见附录 D.2–D.3)[patching]。
图 3 展示了在觅食模型中对方向令牌进行消融后的效果。左侧显示在一个 4 跳循环任务中,最后一个方向令牌在第 1 层的注意力分布情况。右上图展示了不同循环长度(2–12 跳)下方向令牌被移除后的恢复模式:早期层(1–2 层)主要支持短周期内的局部修正,而第 6–8 层则能恢复整体准确率,表明这些深层已建立稳定的内部空间表征。与此形成对比的是,SP 模型在方向令牌消融后仅表现出渐进式性能下降(右下图),缺乏明显的层级恢复特征,反映出其持续依赖方向输入信号,未能实现真正的空间抽象。所有结果均基于 1000 次试验的平均值,误差线代表 ±1 标准差,阴影区域为 95% 置信区间。
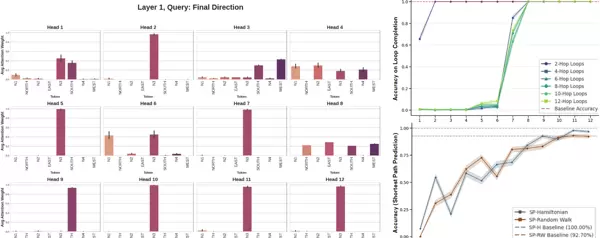
图 3:
? 左图:觅食模型在 4 跳循环任务中,最后一个方向令牌在第 1 层的注意力模式。右上图:觅食模型在不同循环长度下的方向令牌消融结果。早期层处理短周期任务,深层恢复全局精度,提示存在内在空间建模能力。右下图:SP 模型的方向令牌消融结果,显示逐步退化而非层级恢复,说明缺乏高级空间抽象,持续依赖显式方向输入。
3.3 机制分析
因果干预实验表明,不同模型之间的表征差异源自其底层算法的差异。在觅食模型中,自适应行为依赖于两个独立运作的神经回路。为探究模型内部地图何时具备因果完整性,我们进行了消融测试:将每一层输入端所有历史方向令牌的隐藏状态置零,观察性能变化。结果显示,模型采用了两种截然不同的计算方式。
在简单的2跳循环任务(即来回模式)中,第1层的性能恢复至65%,到第2层则达到完全准确率(100%),说明存在一个快速响应且专用于短路径处理的早期层电路(见图3)。注意力机制分析进一步揭示了该策略的实现方式:第1层中的多个注意力头在处理方向令牌时持续关注倒数第二个节点,直接执行“逆转最后一步”的操作。
而对于复杂的4-12跳循环任务,模型表现出明显的相变现象(见图3):在前几层进行消融时性能几乎降至零;但当消融发生在第8层或更深层时,性能骤升至100%。这表明,至第8层为止,模型已将移动信息充分整合进一个独立运行的内部状态中,不再需要依赖原始的方向序列输入——这一发现与先前结果相互印证。
4 讨论
4.1 从局部更新到全局理解
觅食模型所展现的电路结构揭示了一个关键现象:即使训练目标仅涉及局部预测,系统仍能涌现出对空间环境的全局认知。该模型在被动探索数据上训练而成,却发展出高度复杂且情境自适应的计算机制。它并非固守单一策略,而是根据上下文长度动态切换两种模式。
在上下文较短的情况下,模型启用一种基于启发式的快速反应机制,由第1层中针对倒数第二节点的注意力回路实现。这种机制在2跳任务中恰好对应于行为层面观察到的“反向行走”策略;对于稍长路径,该信号可能作为深层网络进行多步推理的基础输入。
随着上下文增长,模型逐渐转向基于内部地图的推理方式。第8层成为关键转折点——此时其空间表征已实现自足,无需再参考原始输入序列。这一过程与Spens & Burgess提出的理论一致,即通过整合序列经验,网络可进行结构化推理而摆脱对原始输入的依赖 [spens2024consolidation]。过渡阶段出现的短暂性能下降,可能正反映了模型正在放弃简单启发式、转向更复杂的地图式计算。
这种双模式架构实现了从自我中心更新向异中心空间表征的演化,类似于哺乳动物神经系统中将自我运动信号整合为绝对位置编码的过程 [barry2014neural]。更重要的是,该机制为典型的“Clever Hans”式失败提供了反例 [bachmann2024ntp]:尽管模型学会了局部捷径,但它也掌握了判断何时应放弃该捷径的元能力。最终形成的“认知地图”不仅超越了坐标追踪功能,还展现出结构组合性特征 [xu2024largelanguagemodelscompositional, dziri2023faithfatelimitstransformers],暗示了一种 emergent 的分层推理能力,标志着向更具灵活性和通用性的AI系统迈进的重要一步。
4.2 训练范式塑造算法
本研究的对比分析凸显了训练框架如何作为Transformer中空间智能发展的算法支架。采用高熵、探索性数据训练的觅食模型,逐步形成了可泛化的类地图表征,并经历了明确的功能分化阶段——包括方向更新、信息整合与功能优化,最终构建出一个自洽的世界模型。
相反,以目标为导向的SP模型则习得了一种连续且路径依赖的计算方式。这类模型虽能有效利用训练数据中的统计规律,但始终依赖显式的方向输入来维持准确性。例如,SP-H模型在表征中表现出水平镜像对称性,正是目标驱动训练在结构化数据上催生出的一种聪明但脆弱的捷径:它利用训练集的规律性提升表现,却难以推广至新场景。
SP-RW模型通过在随机游走轨迹上微调实现了性能提升,体现了探索性数据的价值。虽然机制分析显示其核心计算仍保持路径依赖特性,但其表征空间得到了优化,使得原有算法能够以更灵活的方式编码信息。因此,在不改变根本算法的前提下,泛化能力得以增强。
4.3 局限性与未来方向
当前研究主要聚焦于理想化环境下的路径完成任务,未来可扩展至更复杂的三维或动态场景,以检验这些机制在多样化条件下的稳定性。此外,现有分析集中于静态模型快照,缺乏对训练过程中表征演变轨迹的追踪。引入动态探针技术或中间态干预方法,有望揭示算法形成的演化路径。
另一个值得探索的方向是跨领域迁移:是否在语言或视觉任务中也能观察到类似的双模式切换?特别是当任务要求从局部线索推断全局结构时,是否存在通用的认知地图形成机制?这些问题将有助于判断此类空间推理能力的普遍性及其在更广泛人工智能系统中的潜力。
我们的研究结果需要在若干关键限制条件下加以理解。采用简化的 4×4 网格环境与 GPT-2 small 模型架构,引发了关于该方法能否推广至更复杂场景和更大规模模型的疑问。从机制层面来看,当前分析仍存在不完整性:尽管我们识别出第 1 层中存在初始的空间更新机制,并在后续层中观察到最终的坐标表征,但中间层如何转换和处理空间信息的具体电路结构仍基本处于“黑箱”状态。未来的研究可引入自动电路发现技术 [ACDC],以系统性地绘制这些中间过程中的信息流动路径。
此外,本次因果分析主要聚焦于觅食模型的行为表现,导致 SP 模型所表现出的脆弱性仅能从行为层面被观测,而缺乏对其内在机制的深入解释。因此,后续工作应优先开展对比性的机制分析,旨在揭示 SP 模型在执行最短路径任务时出现算法失败的根本原因。
附录 A 训练配置详情
| 参数 | 觅食模型 | SP-Hamiltonian | SP-RW |
|---|---|---|---|
| 批大小 | 16 | 256 | 128 |
| 学习率 | 1e-4 | 1e-4 | 1e-5 |
| 周期数 | 2 | 12 | 12+20 |
| 优化器 | AdamW | AdamW | AdamW |
| 权重衰减 | 0.1 | 0.1 | 0.1 |
| 上下文长度 | 120 | 16 | 10–50 |
| 训练样本数 | 1M | 1M | 1M |
A.1 数据生成说明
觅食模型数据集:
? 我们构建了包含 1,000,000 条训练序列和 10,000 条测试序列的数据集,每条序列模拟在 4×4 网格上的 120 步随机游走。选择 120 步是基于访问全部 16 个节点所需的期望覆盖时间。为防止模型记忆特定节点标识符,每个序列均重新生成唯一的节点名称。序列格式示例如下:
ab EAST cd SOUTH ef NORTH gh...
SP-Hamiltonian(SP-H)数据集:
? 该数据集用于最短路径任务,其上下文由哈密顿路径构成——即恰好访问所有 16 个节点一次的路径。这种设计提供了完整且无冗余的空间信息,同时避免了字符串匹配类的捷径解法。模型需根据此全面上下文预测起始点与目标点之间的最优路径。我们保留了一组特定的哈密顿“形状”作为独立测试集。
SP-Random Walk(SP-RW)数据集:
? 为进行微调,我们生成了具有可变长度随机游走上下文(10 至 50 步)的最短路径任务。重要的是,我们确保任何有效最短路径所需的所有节点均已出现在上下文中,从而使任务可解。这一设置用于评估模型从部分、非结构化的空间线索中提取并利用相关信息的能力。
A.2 训练实现细节
所有模型均采用 GPT-2 small 架构(共 1.24 亿参数),并使用标准超参数配置。我们尝试了多种学习率、学习率预热策略及优化方案,但除对收敛速度有轻微影响外,未发现显著性能差异。
损失掩码的应用:
? 两个 SP 模型均采用了损失掩码机制,将训练重点集中在路径输出部分,而非上下文重建。这一步骤至关重要,因为在任务中上下文占比极高——在一个 4×4 网格中,平均最短路径仅涉及约 4 个节点,而上下文可能包含超过 16 个节点的信息。
附录 B 性能评估细节
B.1 专项评估任务与技术设定
循环完成任务(2–6 跳):
? 此任务用于测试模型的抽象几何推理能力,要求其补全不同尺寸的方形或矩形图案(形成一个“环”)。通过提供部分图案,检验模型是否能够理解几何约束并推断出完整的结构。N×N 方形补全是其中一种特殊情况,用以衡量模型能否将几何推理能力泛化到更大、更复杂的图形规模上。
对边导航任务:
? 在 5×5 网格上,要求 SP 模型计算相对两侧节点间的最短路径。此类路径通常需要连续 4 次朝同一方向移动,而这在原始 4×4 训练网格中不可能发生,因而可用于检验模型的空间泛化能力。值得注意的是,这些路径的曼哈顿距离不超过 5,仍处于模型已掌握的规划范围内,从而实现了将空间扩展性与推理复杂度的分离测试。
高曼哈顿距离任务(MD > 6):
? 要求 SP 模型预测在 5×5 网格上曼哈顿距离为 7 或 8 的起止点之间的最短路径。由于 4×4 网格中最大可达曼哈顿距离仅为 6,此项任务直接检验模型是否能将其空间推理能力拓展至超出训练期间所见的最大复杂度水平。
B.2 反向移动偏向分析
为了量化觅食模型在局部模式依赖与全局空间理解之间的权衡,我们设计了一项“逆转偏向”指标,用于测量模型倾向于反向回退上一步动作的程度。设某次游走以方向 d 结束,d_rev 表示其反方向(如 NORTH 对应 SOUTH),D_valid 为当前节点所有合法移动方向的集合,则逆转偏向 B 定义如下:
B = z(d_rev) - (1 / (|D_valid| - 1)) × Σ_{d' ∈ D_valid \ {d_rev}} z(d')
其中 z(d) 表示模型对方向 d 的 logit 输出值。该公式反映的是模型在所有可行移动中对反向操作的偏好强度。我们在 500 条随机游走上,针对从 2 到 120 不同长度的上下文,分别计算了该指标,并通过单步预测方式隔离出模型对即时空间状态的理解能力。
B.3 复杂决策情境下的挑战
觅食模型在导航任务中展现出一种基本的决策不对称现象:当仅需预测下一步移动方向时,模型准确率达到 100%;然而,当任务同时要求预测方向和目标节点时,性能下降至 98.3%。尽管差距较小,但这一偏差持续存在,表明同时预测多个相关标记构成了比单一预测更为深层的认知挑战,揭示了模型在多变量联合预测方面仍存在一定局限。
决策过程中的不对称性根植于其内在机制。根据 [bachmann2024ntp] 的研究,NTP 模型更倾向于捕捉局部模式,而对需要前瞻性规划的“困难”决策则往往忽略。在方向预测任务中,模型通常面临多个可行选择,必须具备路径规划能力;而在给定节点进行目标方向预测时,由于网格结构的限制,仅存在唯一正确答案——这属于结果确定的“简单”决策。
逆转偏向指标进一步佐证了这一差异。在较短的上下文条件下,模型表现出显著的逆转偏好,反映出其依赖诸如“避免回头”之类的局部启发式策略。但随着上下文长度增加,该偏向逐渐减弱至接近零,说明模型从局部匹配转向了全局空间推理。这种转变与第 8 层坐标表征的稳定化同步发生,表明只有在完整的认知地图形成之后,模型才能有效处理复杂的路径决策问题。
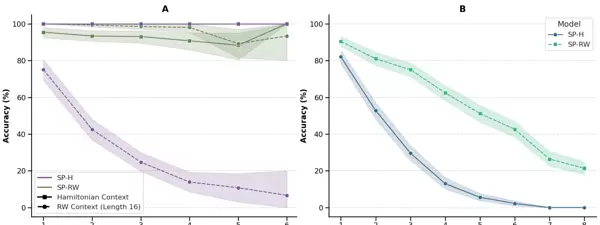
图 4:
4×4 和 5×5 网格上基于曼哈顿距离(Manhattan Distance, MD)的任务性能表现(SP 模型)。(A) 在 4×4 网格中,比较 SP-H(紫色)和 SP-RW(绿色)在不同上下文类型下的准确率。(B) 在 5×5 网格中,展示 SP-Hamiltonian(蓝色)与 SP-RW(绿色)的泛化能力。其中,SP-RW 的性能随 MD 增加从 MD=1 时的 95% 缓慢下降至 MD=8 时的 22%;而 SP-Hamiltonian 仅在极短路径下保持较高准确性(MD=1 时为 83%),随后迅速退化,在 MD=7 时降至 0%。
附录 C:主成分分析
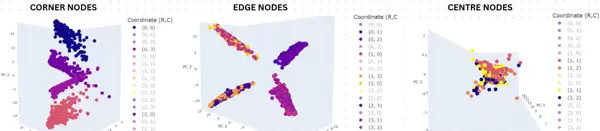
图 5:
觅食模型第 12 层节点令牌隐藏状态的三维 PCA 可视化。数据来源于一个唯一 4×4 网格上的 1000 条长度为 120 的随机游走序列。节点按导航可用性聚类:角点(2 个可移动方向,N=4)、边点(3 个可移动方向,N=8)和中心点(4 个可移动方向,N=4)。结果显示,功能性的行为导向聚类取代了纯粹的空间坐标组织,即节点依据可能的动作而非地理位置聚集,体现出一种面向行动的表征方式。
我们对来自多个序列中特定层和令牌位置的隐藏状态进行了主成分分析(PCA)。对于在序列中重复出现的令牌(如长随机游走中的节点令牌),我们在每个序列内部对其表征取平均值。所得主成分用于可视化并对比不同网络层及不同模型之间空间信息的组织方式。
附录 D:机制分析
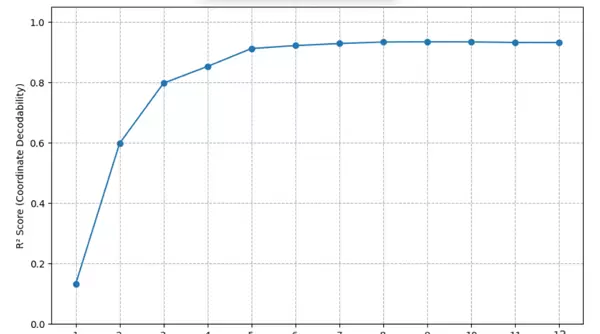
图 6:
Transformer 各层中坐标解码的线性探测性能(觅食模型)。R 分数基于每层 500 个样本计算,用以评估线性探针从隐藏状态中预测 (x,y) 网格坐标的准确性。性能从第 1 层的 R=0.15 逐步提升,并在第 8 层达到稳定值 R≈0.93,表明模型逐步构建出清晰的坐标系统。该稳定阶段与 PCA 观察结果一致,提示空间表征在中间层已趋于成熟。
D.1 笛卡尔坐标系的形成
本研究的首要机制探索聚焦于模型如何编码空间位置。通过线性探测方法,我们发现模型在深层逐步发展出一个稳健且可线性解码的坐标体系。具体而言,针对每一层 l,训练一个线性探针,从其隐藏状态 h_l ∈ ^d 预测真实的 (x, y) 坐标:
? = W h_l + b, 其中 W ∈ ^{2×d}, b ∈ ^2
探针性能以 R 衡量,呈现出明确的发展趋势:R 在早期层缓慢上升,约在第 7 层趋于平稳,并于第 8 层达到峰值(R = 0.93),说明空间表征在此阶段已完成构建并趋于稳定。
值得注意的是,该坐标系具有笛卡尔特性。通过提取探针权重矩阵中的基向量 v_x 和 v_y,计算其夹角余弦:
cos(θ) = (v_x · v_y) / (||v_x|| ||v_y||) ≈ -0.0415
接近零的值表明两个坐标轴几乎正交,意味着模型能够独立表示 x 与 y 维度,从而反映底层网格的几何结构。
D.2 方向令牌的消融实验
为探究方向令牌信息在网络中的传递机制,我们实施了分层消融分析,旨在识别模型“认知地图”何时实现自洽。对于每一层 l,我们将输入端所有历史方向令牌对应的隐藏状态置零,同时保留最后一个方向令牌以及全部节点令牌不变。
方法细节:
给定序列 x = [x_1, …, x_T],设 D 为历史方向令牌的位置索引集合(不包含最终的方向令牌)。在每一层 l 中修改输入隐藏状态 h_l 如下:
h_i^l = { 0 若 i ∈ D;否则保持 h_i^l 不变 }
在觅食模型中,我们在循环返回任务上测试此干预效果(例如:‘aa NORTH bb WEST cc SOUTH dd EAST → aa’),要求模型回到起始位置。对于 SP 模型,则是在上下文序列中移除历史方向信息,并测量最终最短路径预测的准确率变化。
D.3 单步更新电路的定位
在觅食模型中,研究发现单步空间更新的计算主要集中在第 1 层的注意力模块。通过有针对性的消融实验可知,仅当对第 1 层的注意力输出进行干预时,补丁操作才表现出显著效果,说明该层在空间信息处理中具有关键作用。
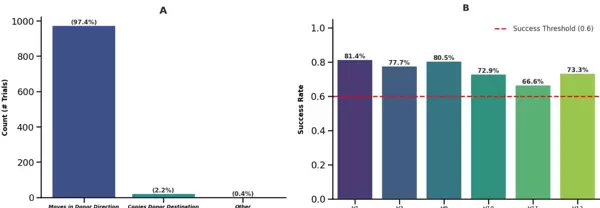
为了进一步解析第 1 层注意力输出所包含的信息内容,我们开展了一项大规模的跨上下文激活补丁实验,共进行了 1000 次独立试验。每次试验均构建一对提示结构:
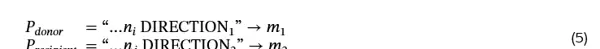

其中,n_i 和 n_j 表示不同的节点,DIRECTION1 与 DIRECTION2 代表两个不同的移动方向(且互不相同),m_1 和 m_2 分别为各自路径下的有效下一节点。实验过程中,从供体提示 P_donor 中 DIRECTION 令牌位置处提取第 1 层的隐藏状态向量 h_donor,并将其作为激活补丁植入受体提示 P_recipient 的对应位置。
图 (A) 展示了 1000 次跨上下文补丁试验的结果分布情况。结果显示,97.4% 的试验成功实现了方向信息的迁移,表明方向性信号可通过该补丁方式有效传递;2.2% 的案例复现了供体上下文中的节点行为;仅有 0.4% 的试验产生了非预期输出,进一步支持了第 1 层在方向编码中的主导地位。
此外,在图 (B) 中展示了当其余注意力头被置零时,单独保留某一个头部运行时的表现。在 12 个第 1 层注意力头中,有 6 个头部在独立测试下(每个头部进行 N=100 次试验)达到了超过 60% 的成功转移率。这一结果揭示出方向信息的处理机制更倾向于分布式表征,而非依赖于某个特定的专业化注意力头。

 京公网安备 11010802022788号
京公网安备 11010802022788号







