


 雷达卡
雷达卡



论文标题:THE LANGUAGE OF TIME: A LANGUAGE MODEL PERSPECTIVE ON TIME SERIES FOUNDATION MODELS
论文链接:https://arxiv.org/abs/2412.17323

核心理论:“时间的语言”假说
本文提出一个关键性观点:基于patch嵌入的时间序列基础模型,可被形式化地视为大型语言模型的自然延伸。其核心在于将时间序列的基本处理单元——即短时间段的“patch”——类比为语言模型中的token(词元)。与自然语言中离散、明确的词汇不同,时序patch在潜在空间中的表示并非单一点,而是呈现出连续分布形态,构成所谓的“分布性token”。
这种从点状表示向分布式表示的转变,使得模型能够捕捉到时间动态中更为丰富和鲁棒的结构信息,从而继承了大语言模型在表达能力、泛化能力和跨任务迁移方面的优势。
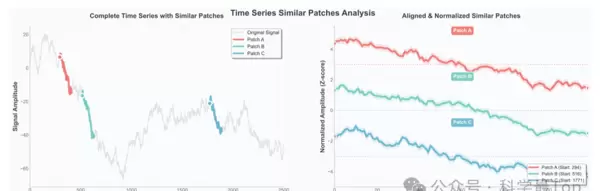
图1:相似时间序列片段及其对齐后的可视化。 左图展示了原始信号中三个高亮patch(Patch A/B/C),尽管它们在振幅上存在差异,但整体趋势形状高度一致。右图显示,在经过Z-Score归一化与时间对齐处理后,三条曲线几乎完全重合,说明这些片段共享同一潜在模式表征。
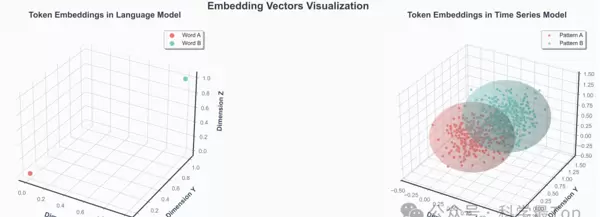
图2:语言token与时序patch嵌入的对比。 左图显示语言模型中token嵌入为稀疏、离散的单点分布;右图则揭示时间序列中patch嵌入形成具有有限厚度的概率云,相同motif(如模式A/B)的patch聚集成可区分但内部连续的区域,支持“分布性token”的概念。
实证验证:时间序列是否具备类语言结构?
研究旨在验证时间序列数据是否蕴含类似自然语言的深层统计规律。通过将连续的时间动态转化为离散符号序列,分析其是否遵循语言学中常见的统计特性,例如Zipf定律与语法组合规则。
01 词汇表构建:从连续信号到离散token
核心方法:
- Patch分割: 将原始时间序列按固定长度P和步长S切分为若干连续片段(patch),作为基本分析单元。
- 向量量化: 使用K-Means算法对来自38k个跨领域时间序列的patch进行聚类,生成包含K个质心的“时间词汇表”,每个质心代表一种基础动态模式。
- 离散映射: 每个patch被映射至最近的质心索引,实现将连续时间序列转换为离散token序列,完成数据压缩与噪声过滤。
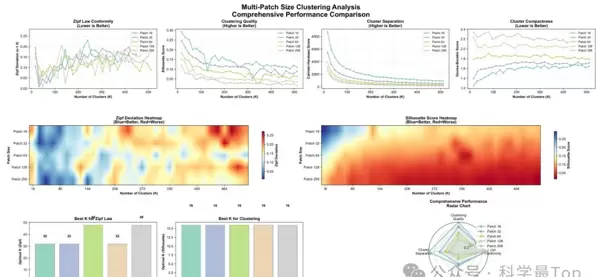
关键发现:patch大小的权衡效应
- 小patch(P=16): 聚类质量更高(轮廓系数显著),对应简单且结构清晰的“原子级”模式,语义单一但可分性强。
- 大patch(P≥64): 更好地符合Zipf分布规律,能捕捉更复杂的“时间motifs”,语义更丰富,但聚类紧凑性下降。
结论: patch长度决定了词汇表的本质属性——较小patch偏向结构性建模,较大patch更利于体现类语言的统计特征。
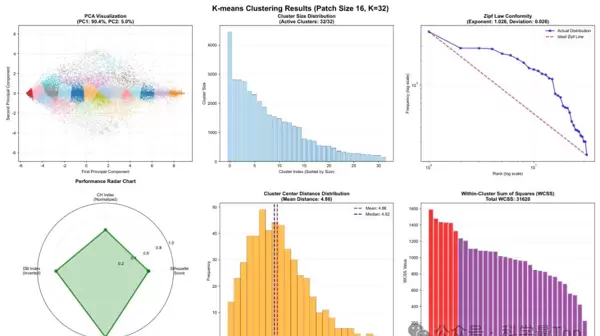
聚类与分布分析结果:
- PCA可视化: patch嵌入在低维空间中形成部分可分离但存在重叠的簇,印证了“分布性token”假设,即每种时间motif在潜在空间中表现为一个连续区域而非孤立点。
- Zipf定律验证: 所有簇的大小分布呈现典型长尾特性,在log-log坐标下与理想Zipf分布的偏差仅为0.026,表明时间序列token频率严格遵循幂律分布。
- 簇内方差(WCSS): 部分簇具有较高的组内平方和,说明同一token对应多种相似但非完全相同的时序模式,进一步支持“token代表模式族”的观点。
02 时间序列中的类语言统计特性
1. Zipf分布在时间词汇中的普遍存在
在不同词汇规模K(范围从16到256)下,token出现频率均严格服从Zipf定律——即第n高频token的频率约等于最高频token的1/n。这一现象表明,时间序列由有限数量的可复用motif组成,并通过组合方式生成复杂行为,类似于语言中词汇与语法的协同机制。
2. 词汇表结构的稳定性与适应性
随着K增大,虽然平均token频率下降,但整体结构保持不变:始终表现为“少数高频motif + 大量低频motif”的不平衡分布,且高频异常值持续存在。这说明所提取的motifs反映了数据中真实、稳定的基础动态模式,具备良好的鲁棒性和泛化能力。
03 时间序列的“语法”结构探索
核心发现:motif序列存在可识别的组合规则
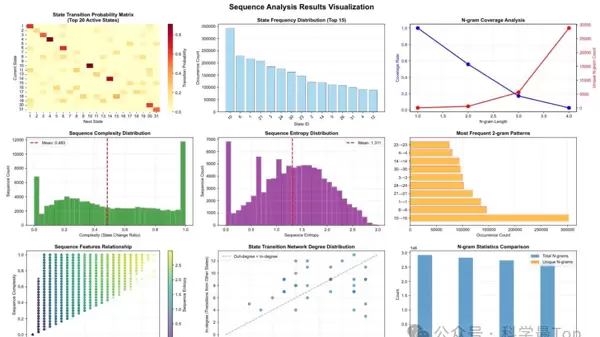
图3:motif转移矩阵与n-gram覆盖度分析。 展示了时间motif之间的转移规律与组合约束。
- 状态惯性原则: 状态转移矩阵中对角线元素显著突出,表明自转移概率占主导地位;2-gram统计显示,“相同motif重复”是最常见的模式,反映时间系统的持续性特征。
- 稀疏语法结构: n-gram的覆盖度随阶数增加呈指数衰减,仅有少数motif组合频繁出现,暗示存在类似自然语言句法的合法性约束。
- 宏观多样性的微观分块机制: 尽管整体序列表现出高度复杂性与广泛的熵分布,但其构成方式是由多个稳定的“motif块”拼接而成,类似于语言中通过短语组合形成句子的层次化结构。
本文结论
尽管时间序列天然存在跨域分布偏移问题,制约着模型迁移的理论合理性,但实证研究表明,基于patch的时间序列基础模型之所以成功,是因为其本质上是在学习一种“时间的语言”。该语言以分布性patch为token,以可复用motif为词汇,以组合规则为语法,形成了具备强大表达力与泛化能力的形式系统。
因此,时间序列基础模型的成功并非偶然,而是源于其与语言模型共享的底层结构原理。这一视角不仅解释了当前模型的有效性,也为未来构建更加安全、可靠、可解释的时序智能系统提供了理论基础。
通过构建时间序列词汇表,并对其统计特性与组合规律进行深入分析,研究证实:在经过token化处理后,时间序列数据展现出明显的类语言特征。这些特征具体表现为遵循Zipf定律、存在类似状态转移的“语法”结构,以及通过分块机制形成复杂的模式表达。
这一发现为时间序列基础模型具备跨域迁移能力提供了有力的实证依据。模型能够通过学习这种被称为“时间的语言”的内在规律,实现对动态时序模式的高度抽象与有效表示。


 京公网安备 11010802022788号
京公网安备 11010802022788号







