


 雷达卡
雷达卡



第一部分:微调的核心概念
1.1 微调的本质与意义
将预训练过程类比为“通识教育”,即让模型掌握语言结构、基本逻辑和通用知识;而微调则相当于“职业培训”——使模型具备特定任务或领域的实际操作能力。
预训练模型(Base Model):虽然拥有广泛的知识储备,但缺乏执行具体任务的能力。例如,它能理解“医学诊断”的概念,却无法像专业医生那样开出治疗方案。
微调后模型(Chat/Instruct Model):经过指令遵循训练,并掌握了某一垂直领域的术语与表达方式,能够完成定向输出。
为何需要微调?主要有以下几点原因:
- 注入专业领域知识:适用于法律、医疗、金融等包含私有数据的行业场景。
- 定制化行为风格:可设定模型人格,如“毒舌程序员”或“耐心的心理咨询师”。
- 规范输出格式:强制生成 JSON、SQL 或指定代码结构,满足系统对接需求。
第二部分:主流微调方法分类
当前微调技术主要分为两大路径:全量微调(Full Fine-tuning) 与 参数高效微调(PEFT, Parameter-Efficient Fine-Tuning)。
2.1 全量微调(Full Fine-tuning)
核心原理:对模型的所有参数进行更新优化。
显著缺点:
- 显存消耗巨大:以7B规模模型为例,通常需超过100GB显存,依赖A100/H100集群支持。
- 灾难性遗忘问题:在学习新知识的同时,可能丢失原有通用能力。
适用场景:仅推荐用于资源充足的大型机构,且拥有海量高质量通用语料,意图彻底重塑模型底层能力的情况。
2.2 参数高效微调(PEFT)
工作方式:冻结原始模型绝大部分参数,仅训练新增的一小部分可调节模块(通常不足总参数量的1%)。
核心优势:可在消费级显卡(如RTX 3090/4090)上运行,训练速度快,效果接近全量微调,极大降低硬件门槛。
第三部分:主流微调技术深度解析
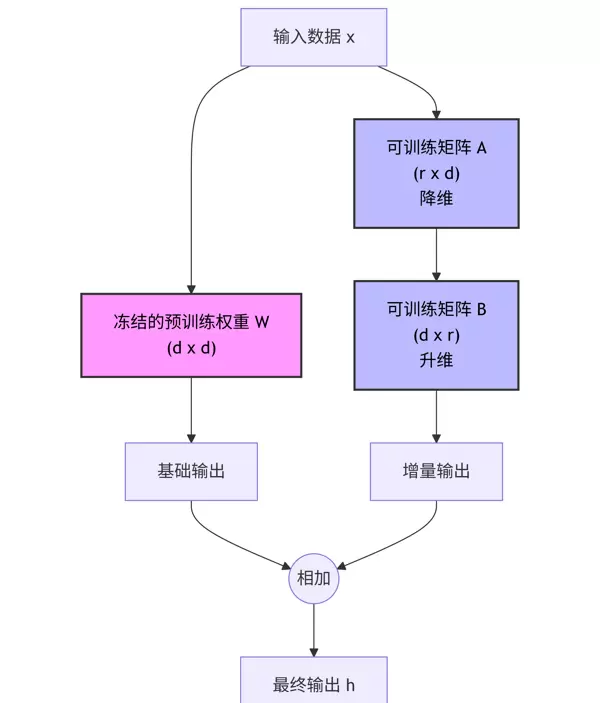
3.1 LoRA(Low-Rank Adaptation)—— 行业事实标准
技术思想:假设权重变化矩阵具有低秩特性。不直接修改原始大矩阵 W,而是引入两个小型可训练矩阵 A 和 B 进行增量调整。
原始计算: h = Wx
LoRA 改进: h = Wx + ΔWx = Wx + BAx
关键参数说明:
- Rank (r):决定矩阵分解的维度,值越小,引入参数越少,常见取值为8、16、64。
- Alpha:缩放因子,控制LoRA分支对整体输出的影响强度。
transformers3.2 QLoRA(Quantized LoRA)—— 普惠型微调方案
核心技术:结合量化技术,在LoRA基础上进一步压缩内存占用。
- 4-bit NormalFloat (NF4):将基础模型以4位精度加载,显存使用减少约50%。
- 双重量化(Double Quantization):对量化过程中产生的常数也进行压缩处理。
- 分页优化器(Paged Optimizers):当GPU显存不足时,自动将优化器状态暂存至CPU内存,避免OOM错误。
实践价值:仅需单张24GB显存显卡(如RTX 3090/4090),即可完成对30B至70B参数级别模型的微调任务。
peft3.3 P-Tuning v2 / Prefix Tuning —— 提示层面的微调策略
实现机制:不在模型权重上做改动,而是在输入序列或每一层前添加一组“可学习的虚拟Token”。通过优化这些虚拟Token的嵌入向量来适配目标任务。
局限性:在涉及复杂推理的任务中,性能普遍弱于LoRA类方法。
3.4 偏好对齐技术对比:RLHF vs DPO
当模型已完成监督微调(SFT)并掌握专业知识后,下一步是使其回应符合人类偏好与伦理准则。
RLHF(基于人类反馈的强化学习):
- 流程步骤:SFT → 训练奖励模型 → 使用PPO算法进行强化学习优化。
- 挑战:PPO训练过程极不稳定,超参数敏感,资源开销大。
DPO(直接偏好优化)—— 当前主流趋势
- 创新点:无需构建独立的奖励模型,也不依赖PPO框架。
- 原理简述:利用成对数据(优质回答 vs 劣质回答)构造损失函数,通过梯度下降直接优化偏好倾向。
- 直觉解释:提升好回答被生成的概率,同时抑制差回答的出现。
- 优势:训练更稳定、节省显存、效果优异。
trl第四部分:基于 HuggingFace 的 Python 实战演示
本节将在单卡GPU环境下,使用 Qwen2.5-7B 模型实施 QLoRA 微调,所涉工具库包括:
data.jsonl4.1 环境搭建
pip install -q transformers peft bitsandbytes trl accelerate4.2 数据准备(JSONL 格式)
假设我们已准备好一个名为
data.jsonl{"prompt": "请解释什么是机器学习", "response": "机器学习是..."}4.3 完整训练脚本(Python)
import torch
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig,
TrainingArguments
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from trl import SFTTrainer
================= 参数设置 =================
定义模型与输出路径:
MODEL_ID = "Qwen/Qwen2.5-7B-Instruct" # 可替换为 Llama-3-8B 等其他模型
OUTPUT_DIR = "./qwen_lora_finetuned"
第一步:配置 4-bit 量化,这是 QLoRA 方法的核心环节。通过以下设置实现低资源下的高效训练:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
)
第二步:加载预训练模型及其对应的分词器。注意对某些模型如 Llama 或 Qwen,需手动设置填充符。
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token # 避免训练中出现异常
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
transformers第三步:对模型进行预处理,使其适配 k-bit 条件下的微调训练流程。
model = prepare_model_for_kbit_training(model)
第四步:设定 LoRA(Low-Rank Adaptation)配置参数,用于在冻结主干网络的前提下更新少量参数。
peft_config = LoraConfig(
r=16, # 低秩矩阵的秩,值越大拟合能力越强但可能过拟合
lora_alpha=32, # 缩放因子,通常设为 r 的两倍
lora_dropout=0.05, # Dropout 比例,防止过拟合
bias="none", # 不使用偏置项
task_type="CAUSAL_LM", # 当前任务为因果语言建模
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
] # 覆盖 Transformer 中的关键投影层
)
peft第五步:载入训练数据集,并按照指定格式进行转换。假设数据文件为 JSONL 格式,结构遵循 Alpaca 规范:
{"instruction": "解释量子纠缠", "input": "", "output": "量子纠缠是量子力学中的一种现象..."}
{"instruction": "将这句话翻译成英文", "input": "你好,世界", "output": "Hello, World"}
加载命令如下:
dataset = load_dataset("json", data_files="data.jsonl", split="train")
随后定义一个格式化函数,将样本整合为适合对话模型训练的提示结构:
def format_prompt(sample):
instruction = sample['instruction']
input_text = sample['input']
response = sample['output']
text = f"User: {instruction}\n{input_text}\nAssistant: {response}"
return {"text": text}
dataset = dataset.map(format_prompt)
trl第六步:配置训练超参数,包括批量大小、学习率、步数等,以适应有限显存环境并保证训练稳定性:
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=4, # 若显存不足可适当减小
gradient_accumulation_steps=4, # 显存受限时可通过增加此值补偿
learning_rate=2e-4, # QLoRA 常用较高学习率
logging_steps=10,
fp16=True, # 启用混合精度加速训练
max_steps=100 # 仅作演示用途,实际建议运行多个 epoch
)
该脚本整合了现代大模型轻量化微调的关键技术,适用于在消费级 GPU 上高效完成指令微调任务。
# 7. 启动训练(基于 TRL 库的 SFTTrainer)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=1024,
args=training_args,
packing=False,
)
print("开始训练...")
trainer.train()
# 8. 保存适配器(Adapter)
trainer.model.save_pretrained(OUTPUT_DIR)
print(f"LoRA 权重已保存至 {OUTPUT_DIR}")
4.4 模型推理与权重合并
完成训练后,得到的是一个体积较小的 Adapter(即 LoRA 权重),通常只有几百 MB,并非完整的模型文件。在进行推理时,需通过动态加载方式将 LoRA 权重注入到原始基座模型中:
from peft import PeftModel
# 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(MODEL_ID, device_map="auto", torch_dtype=torch.float16)
# 注入 LoRA 适配器
model = PeftModel.from_pretrained(base_model, OUTPUT_DIR)
# (可选)合并 LoRA 并导出完整模型
merged_model = model.merge_and_unload()
merged_model.save_pretrained("./merged_final_model")
第五部分:推荐实战工具链
除了手动编写代码外,目前已有多个低代码或无代码的图形化工具,能够显著提升微调效率和实验迭代速度。
1. LLaMA-Factory(强烈推荐 ????)
核心特点:
作为全球最受欢迎的微调框架之一,提供直观的 WebUI 界面,支持全流程操作。
功能亮点:
- 支持 Pretrain、SFT、RM、PPO、DPO 等多种训练范式。
- 兼容几乎所有主流模型架构,如 Llama3、Qwen、ChatGLM、DeepSeek 等。
使用方法:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[metrics]
llamafactory-cli webui # 启动图形界面
用户可通过界面点击完成模型微调、实时监控 Loss 变化、以及最终模型导出等操作,无需深入代码细节。
2. Unsloth
核心优势:
专注于极致性能优化,显著提升训练速度并降低资源消耗。
关键表现:
- 训练速度比标准 HuggingFace 实现快 2–5 倍。
- 显存占用减少超过 50%。
适用场景:
特别适合需要快速迭代 Llama-3、Mistral 或 Gemma 系列模型的项目。
3. Axolotl
主要特性:
采用 YAML 配置驱动,配置灵活,深受开源社区青睐。
优势说明:
非常适合用于管理复杂的多组实验任务,便于版本控制与复现。
总结:大模型微调最佳实践路径
- 数据优先原则: 数据质量远胜于数量。例如,500 条经过人工精心整理的高质量 SFT 样本,往往优于 10,000 条由合成生成的低质数据。
- 指令多样性要求: 数据应涵盖多种任务类型,包括但不限于问答、摘要生成、文本改写、逻辑推理等,避免单一模式。
方法选择建议:
- 资源受限或快速验证: 推荐使用 QLoRA(4-bit 量化),节省显存且部署便捷。
- 追求最优效果: 可选用 LoRA(16-bit)或全参数微调(Full Fine-tuning)。
- 优化回复风格与拒答行为: 在 SFT 之后接入 DPO 训练阶段,可有效改善模型输出语气和安全性。
超参数设置参考:
learning_rateLoRA 场景下一般推荐使用
2e-42e-5rank (r)对于通用任务,rank 值设为 8 或 16 即可满足需求;若涉及数学推理或代码生成等复杂任务,可尝试 64 或 128。
target_modules建议尽可能覆盖
all-linear通过上述流程,无论是在本地环境还是云端服务器上,你都可以成功训练出适用于特定垂直领域的定制化大语言模型。



 京公网安备 11010802022788号
京公网安备 11010802022788号







