


 雷达卡
雷达卡



在社会科学、经济学以及环境学等多个研究领域中,所采集的数据通常同时包含两个重要维度:空间维度(如省份、城市)和时间维度(如年份、季度)。当我们将面板数据模型与空间计量方法相结合时,便形成了一个更为强大且精细的分析工具——空间面板模型。该模型不仅能有效控制那些不随时间变化的个体差异,还能深入揭示变量在时空交互网络中的复杂关联机制,从而提供更具深度的研究洞察。
一、空间面板模型的理论发展与主要类型
传统的截面空间模型(例如SDM、SEM)类似于对数据进行一次“静态快照”,虽然可以捕捉到某一时刻的空间相关性,但无法反映动态演变过程。相比之下,面板数据模型通过引入固定效应(FE)或随机效应(RE),能够控制那些难以直接观测却长期稳定的个体特征(如城市的地理条件或文化背景),从而提升估计结果的准确性。
空间面板模型正是将上述两种思路融合的结果:在传统面板模型基础上,进一步纳入空间依赖结构。依据空间依赖性的不同来源,衍生出若干核心模型类型,这也是使用SPSSAU等分析平台时必须首先明确的关键选择:
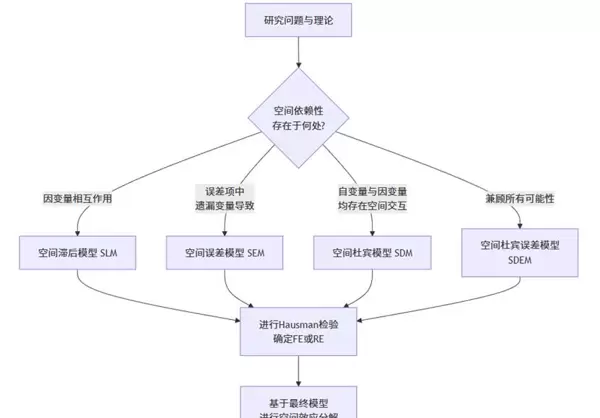
- 空间滞后模型(SLM / SAR):假设因变量存在空间溢出效应,即某地区的因变量会受到邻近地区相同变量值的影响,其关键参数为空间自回归系数 ρ。
- 空间误差模型(SEM):认为空间依赖性源于误差项,可能由未被观测但具有空间聚集性的因素引起,核心在于估计空间误差系数 λ。
- 空间杜宾模型(SDM):该模型具有更强的包容性,同时考虑了因变量的空间滞后(ρWy)和自变量的空间滞后(WXθ)。这意味着本地区因变量不仅受本地因素影响,也受到周边地区因变量和自变量的共同作用。由于SDM可退化为SLM或SEM,在实证分析中常作为稳健的起点模型。
- 空间杜宾误差模型(SDEM):综合了自变量空间滞后项(WXθ)与误差项的空间自相关结构(λWu),属于另一种扩展型复合模型。
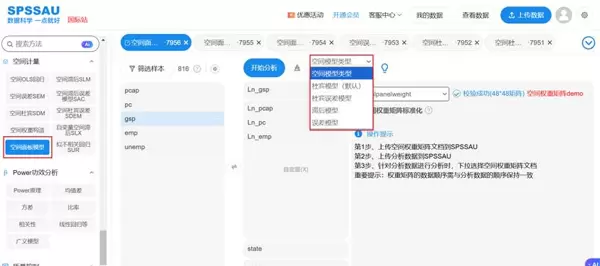
在SPSSAU平台上,用户可在建模前直接从以上几类模型中做出选择,操作流程如下图所示:
二、基于SPSSAU的空间面板分析流程:从模型判定到效应解析
SPSSAU为空间面板数据分析构建了一套逻辑清晰、步骤严谨的输出体系,帮助研究者系统完成从模型设定到结果解读的全过程。
1. 模型基本信息表:研究设计的“时空标识”
该表格是整个分析报告的基础,用于明确研究的时间跨度、空间范围及模型配置信息。

上表详细列出了所采用的空间面板模型类别(如空间杜宾模型)、空间权重矩阵的具体定义、样本规模(截面数×时期数),以及最关键的——个体效应处理方式(固定效应FE或随机效应RE)。这一部分确保了研究过程的透明性和可复现性。
2. Hausman检验:固定效应与随机效应的选择依据
Hausman检验是决定面板模型形式的核心步骤之一。

该检验的原假设(H0)为:随机效应(RE)模型是适用的。若检验得到的p值小于预设显著性水平(如0.05),则拒绝原假设,表明固定效应(FE)模型更优。其内在逻辑在于:FE模型通过组内变换消除个体效应与解释变量之间的潜在相关性,保证估计的一致性;而RE模型假设个体效应与解释变量无关,虽效率更高,但在存在相关性时可能导致偏误。SPSSAU会自动执行此检验并给出推荐结论(如“建议使用FE模型”),极大简化了用户的决策流程。
3. 模型估计结果表
根据Hausman检验的判断,SPSSAU将分别展示FE与RE设定下的参数估计结果。
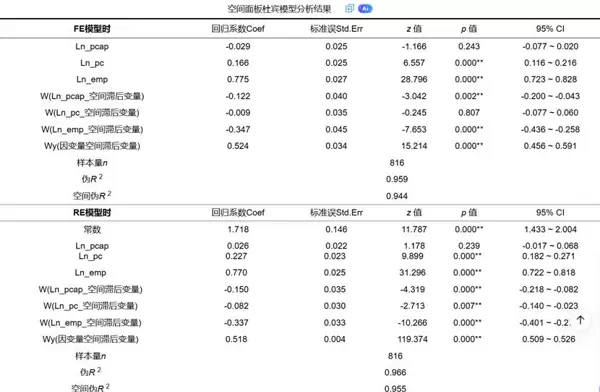
该表呈现了各关键参数的估计值,包括:
- 自变量回归系数(β):表示本地自变量对本地因变量的直接影响,通常被视为短期效应。在FE模型中,常数项被个体效应吸收,以控制不可观测的异质性。
- 自变量空间滞后项系数(WX, θ):体现邻近地区自变量对本地区因变量的影响程度,是SDM/SDEM模型的重要特征。
- 因变量空间滞后项系数(Wy, ρ):反映因变量自身的空间溢出强度。
- 空间误差系数(Lambda, λ):在SEM/SDEM中衡量误差项的空间聚集性。
该表格主要用于初步判断各变量的统计显著性,识别哪些影响路径具有实际意义。
4. 空间效应分解表
对于SDM类模型,直接解读原始回归系数容易产生误导,因其存在反馈循环(即A地影响B地,B地又反作用于A地)。因此,必须进行空间效应分解以获得准确解释。
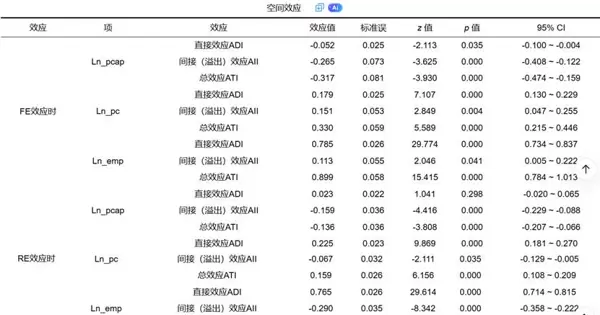
SPSSAU会将每个自变量的总体影响拆解为以下三类:
- 直接效应:指某一区域自变量变动对该区域自身因变量的平均影响,已包含所有间接反馈回路的作用。
- 间接效应(溢出效应):衡量某一区域自变量变化对其他所有区域因变量所产生的平均影响,是空间外溢分析的核心指标,揭示政策或现象的跨区传导能力。
- 总效应:等于直接效应与间接效应之和,代表该变量在整个空间系统中的完整影响力。
该分解表是SDM模型最终结论的主要依据,尤其适用于评估区域间互动、政策扩散或环境外部性等问题。
5. 模型诊断与比较
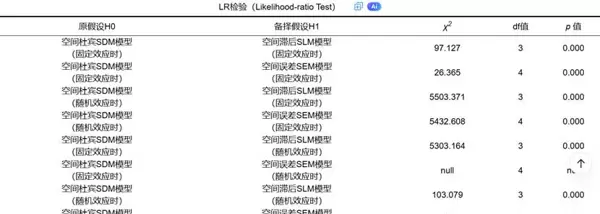
LR检验(似然比检验): 该方法主要用于嵌套模型之间的比较。例如,可用于判断空间杜宾模型(SDM)是否可简化为空间滞后模型(SLM),其原假设为 H: θ = 0;或简化为空间误差模型(SEM),对应原假设为 H: θ + ρβ = 0。若检验结果的 p 值显著,则应拒绝原假设,表明更复杂的 SDM 模型具有必要性。
信息准则(AIC、SC): 适用于非嵌套模型间的对比分析。当在多个模型(如 SDM 与 SDEM)之间进行选择时,通常以 AIC 或 SC 值较小者为优。SPSSAU 平台同时提供固定效应(FE)和随机效应(RE)下的这些指标,帮助用户基于数据特征实现科学的模型优选。

Breusch-Pagan 与 Jarque-Bera 检验: 前者用于检测异方差问题,后者则检验残差是否服从正态分布,二者共同作为空间模型设定稳健性的辅助诊断工具。

三、选择 SPSSAU 进行空间面板分析的理由
集成化的模型选择机制: SPSSAU 将主流的空间面板模型——包括 SDM、SEM、SLM 和 SDEM ——整合于统一操作界面,并内置 Hausman 检验、LR 检验及信息准则等功能,构建了一套完整的“模型筛选—比较—诊断”流程,有效支持用户做出合理决策。
高效处理复杂运算: 空间面板模型的参数估计(如采用极大似然法)涉及高维矩阵计算,过程繁琐且技术门槛高。SPSSAU 在后台自动完成所有复杂运算,并直接输出空间效应分解结果,显著降低了应用难度。
逻辑清晰的结果呈现: 平台的输出结构严格遵循学术规范,从基础设定、效应类型判断,到参数估计与空间效应拆解,层层递进,便于研究者整理分析结果,也利于撰写符合发表要求的论文内容。
注重实际应用的解读支持: 系统提供的“智能分析”功能可自动识别并提示关键检验结论(例如 Hausman 检验倾向于 FE 还是 RE),帮助用户快速把握核心要点,从而将更多精力集中于理论解释与政策启示的探讨上。
四、总结
空间面板模型通过同时考虑个体异质性与空间依赖关系,成为分析时空数据的重要工具。掌握从模型选取、效应形式判定,到最终空间效应分解的整体逻辑链条,是确保方法正确运用的核心所在。
SPSSAU 凭借其严谨的方法论框架与强大的计算能力,将原本复杂的空间分析流程转化为清晰、可视且易于操作的过程。它使研究者得以摆脱繁复的技术细节,专注于科学问题本身的探索,进而更高效地从时空数据中提炼出有价值的规律与洞察。

 京公网安备 11010802022788号
京公网安备 11010802022788号







