


 雷达卡
雷达卡



金仓数据库产品体验官活动参与指南
【金仓数据库产品体验官】第六期——性能深度体验专场,作为2025年度收官活动现已开放。详情请参考官方页面:
https://bbs.kingbase.com.cn/forumDetail?articleId=a5b32d12a0024d02f6c6944671c3f309

金仓数据库(V9R2C13 Oracle兼容版)下载与部署
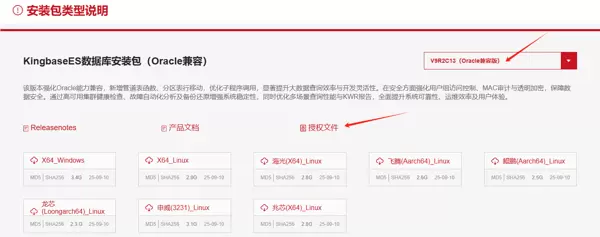
首先访问金仓社区官网,获取V9R2C13版本的Oracle兼容数据库安装包。同时,请注意一并下载对应的授权文件,具体操作方式如下图所示:

安装环境准备
建议使用配置为4核CPU、8GB内存的CentOS 7.6虚拟机进行部署。该组合较为稳定,便于后续操作。
接下来创建用于安装KES的目录结构:
[root@node1 ~]# useradd kingbase
[root@node1 ~]# passwd kingbase
Changing password for user kingbase.
New password:
BAD PASSWORD: The password contains the user name in some form
Retype new password:
passwd: all authentication tokens updated successfully.
[root@node1 ~]# mkdir -p /KingbaseES/V9 /data /archive /backup/dump
[root@node1 ~]# chown -R kingbase:kingbase /KingbaseES
[root@node1 ~]# chown -R kingbase:kingbase /data
[root@node1 ~]# chown -R kingbase:kingbase /archive
[root@node1 ~]# chown -R kingbase:kingbase /backup
[root@node1 ~]# ls -l /|grep kingbase
drwxr-xr-x. 2 kingbase kingbase 6 Dec 3 01:13 archive
drwxr-xr-x. 3 kingbase kingbase 18 Dec 3 01:13 backup
drwxr-xr-x. 2 kingbase kingbase 6 Dec 3 01:13 data
drwxr-xr-x. 3 kingbase kingbase 16 Dec 3 01:13 KingbaseES
[root@node1 soft]# ls
KingbaseES_V009R002C013B0005_Lin64_install.iso
license_4_V009R002C-企业版(oracle兼容)-180天.dat
[root@node1 soft]# chown -R kingbase:kingbase /soft/
[root@node1 soft]# chown -R 777 /soft/
[root@node1 soft]# mount KingbaseES_V009R002C013B0005_Lin64_install.iso /mnt
mount: /dev/loop0 is write-protected, mounting read-only图形化界面配置
为提升操作效率,推荐使用MobaXterm连接测试环境,并启用图形化界面显示功能。由于采用net网络模式,需将图形化输出指向主机本地,通常设置为VM_net8网卡对应IP地址,避免直接在虚拟机中操作。
默认安装界面为英文,可根据需要调整语言选项以提升使用体验。
[kingbase@node1 ~]$ export DISPLAY=192.168.40.1:0.0
[kingbase@node1 ~]$ xhost +
[kingbase@node1 mnt]$ export LANG=zh_CN.UTF-8
[kingbase@node1 mnt]$ ./setup.sh执行安装流程
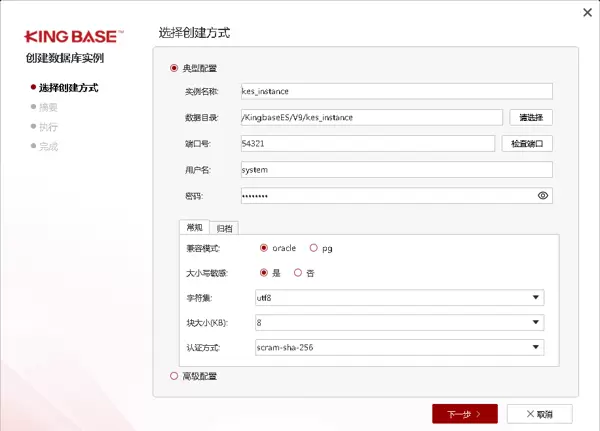
完成上述准备后,即可开始安装过程。以下为关键步骤截图示意:



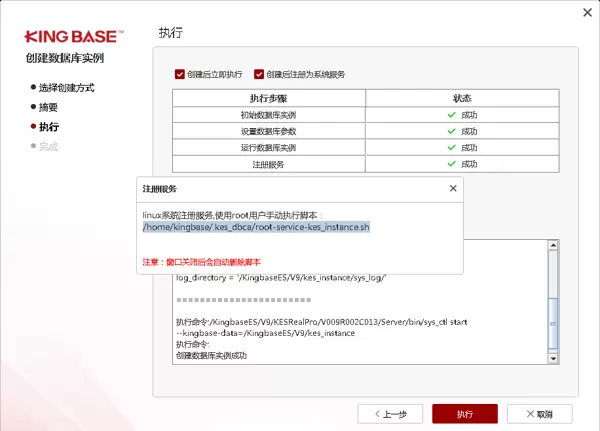
[root@node1 ~]# /home/kingbase/.kes_dbca/root-service-kes_instance.sh
waiting for server to shut down.... done
server stopped
Starting KingbaseES V9:
waiting for server to start.... done
server started
KingbaseES V9 started successfully
环境变量配置
为方便后续调用ksql、sys_rman等工具,建议配置系统环境变量,避免每次进入指定目录执行命令。
[kingbase@node1 ~]$ vi ~/.bash_profile
--再文末写入以下内容,安装目录不同环境变量也会不同
export KINGBASE_HOME=/KingbaseES/V9/Server
export KINGBASE_DATA=/KingbaseES/V9/kes_instance
export PATH=$PATH:/KingbaseES/V9/Server/bin
export KINGBASE_PORT=54321
[kingbase@node1 ~]$ source ~/.bash_profile
[kingbase@node1 ~]$ ksql test system
用户 system 的口令:
授权类型: 企业版(oracle兼容).
输入 "help" 来获取帮助信息.
test=# select get_license_validdays();
get_license_validdays
-----------------------
180
(1 行记录)确认当前版本及授权有效期无误后,表示安装成功。若过程中遇到问题,可查阅相关文档或通过评论区反馈。
数据库性能优化验证
官方提供了一键式优化脚本,主要用于自动调整shared_buffers、work_mem等核心参数,旨在减少磁盘I/O,提升查询响应速度。此脚本对初学者友好,推荐安装完成后运行一次。注意:修改后的参数需重启数据库服务方可生效。
[kingbase@node1 kb_modify_syscfg]$ ./optimize_database_conf.sh
This tool help use to make a base optimization for database
begin optimize database
1.get database data, check database is alive
kingbase_path : /KingbaseES/V9/KESRealPro/V009R002C013/Server/bin/kingbase
server_path : /KingbaseES/V9/KESRealPro/V009R002C013/Server
kingbase_home : /KingbaseES/V9/KESRealPro/V009R002C013
database data_dir: /KingbaseES/V9/kes_instance
2.back kingbase.conf file
before optimize the database, back kingbase.conf to kingbase.conf_back_2025-12-03_02_01_33
3.get system resource
system CPU cores: 4
system Mem: 8155148 KB as 7964 MB
4.optimize database memory
shared_mem: 1991 MB
5.optimize database checkpoint
6.optimize database parallel
end optimize database
7.restart database to make those configuration work
please chose if restart database, 0: no, 1: yes:在实际部署中曾出现过一个小失误:提前规划了数据存储路径,但在安装时未正确指定,导致后期配置环境变量时产生混淆。虽不影响整体运行,但提醒我们在部署阶段应更加细致。继续推进后续测试。
LISTAGG 排序优化实测
本环节通过“环境清理→数据生成→索引建立→统计信息更新→查询测试”全流程,评估LISTAGG排序优化的实际效果,并分析不同场景下的性能差异。
步骤一:清理测试环境
删除已存在的测试表,确保测试环境干净。

步骤二:验证清理结果
执行查询确认无残留表对象,预期返回为空结果集。

步骤三:创建测试表
新建用户订单明细表用于后续压测。

步骤四:批量插入测试数据
分10批次共生成500万条非空测试记录。
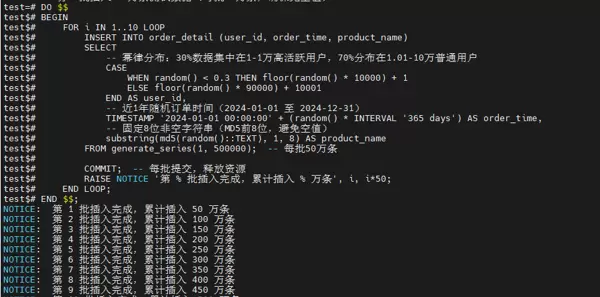
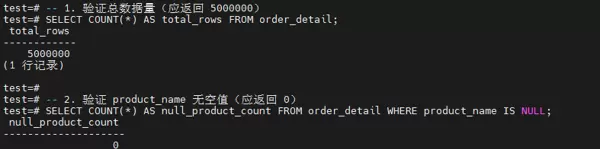
步骤五:数据完整性校验
检查总行数是否达标,并确认关键字段无空值。
步骤六:用户活跃度分布验证
查看前10位高活跃用户,其订单数量应不低于100单。
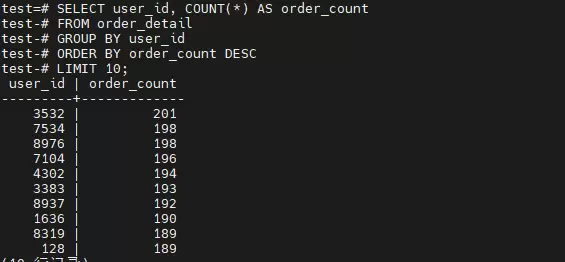
步骤七:无索引状态下的基准测试
在未建索引情况下执行LISTAGG查询,重点观察全表扫描和磁盘排序带来的性能开销。

预期结果:
- 执行计划包含 Seq Scan(全表扫描)与 Sort(外部排序)
- 查询耗时约为 2500–3000ms(基于4核8G SSD环境)
步骤八:创建「分组+排序」复合索引(基础优化)
建立复合索引后,执行计划由Seq Scan转为Index Scan,跳过了磁盘排序过程,读取效率提升。
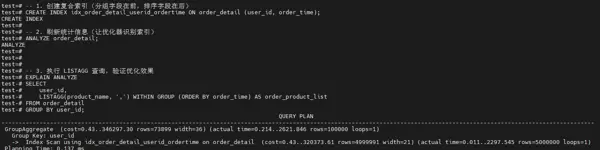
尽管数据访问路径更优,但整体查询时间下降不明显。原因在于LISTAGG需对每个user_id下的product_name进行字符串拼接聚合,该操作本身消耗大量CPU与内存资源。当数据量达500万级时,此类计算开销难以完全规避。
步骤九:构建「分组+排序+覆盖」复合索引(极致优化)
进一步创建覆盖索引idx_order_detail_cover,包含user_id、order_time和product_name字段。
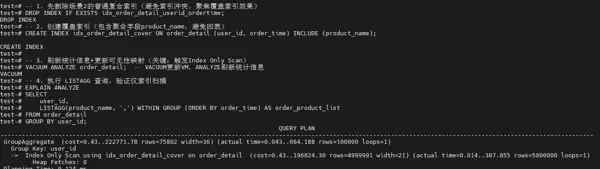
此时执行计划显示为 Index Only Scan,且 Heap Fetches: 0,表明无需回表查询主数据页,仅通过索引即可完成全部数据读取。
实现该理想状态的关键在于执行了 VACUUM ANALYZE 命令,它更新了表的统计信息与可见性映射,使优化器能准确判断索引页中所有元组均可见,从而启用纯索引扫描。
对于涉及分组、排序和聚合的复杂查询,合理设计覆盖索引可显著降低I/O和计算成本,带来显著性能飞跃。
OR条件向UNION ALL转换优化测试
该部分将探索SQL中OR谓词重写为UNION ALL形式的优化潜力,通过拆分查询逻辑减少冗余扫描,提升执行效率。相关内容将在后续章节展开详细验证。
在多表联合查询的性能优化实践中,构建北京与上海两个区域订单表的真实数据模型,有助于深入分析不同SQL写法和索引策略对执行效率的影响。当前许多系统在处理跨表数据分析时,普遍存在查询响应慢、资源消耗高等问题。
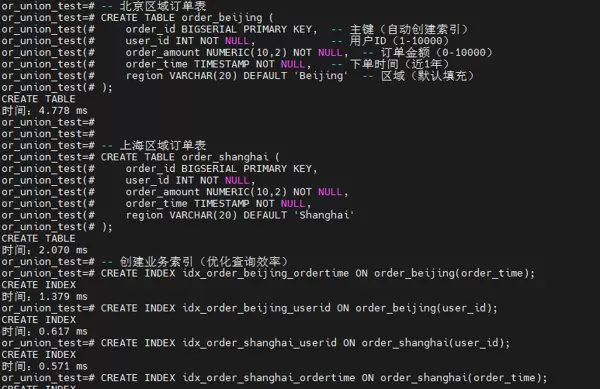
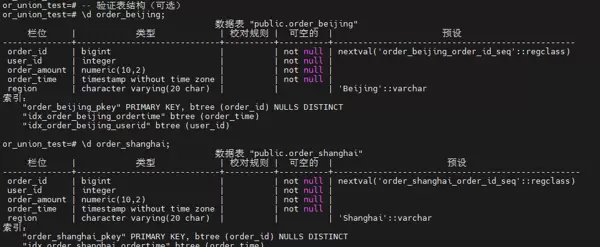
步骤 2:确认表结构定义
首先验证数据库中 order_beijing 与 order_shanghai 表的结构是否符合预期设计,确保字段类型、主键及初始索引配置正确无误。
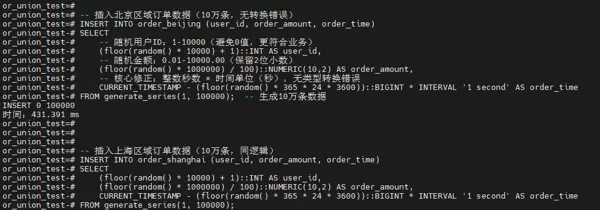
步骤 3:批量插入测试数据
向两张表中分别导入大规模真实场景模拟数据,形成总量达20万条的测试数据集,用于后续查询性能对比分析。
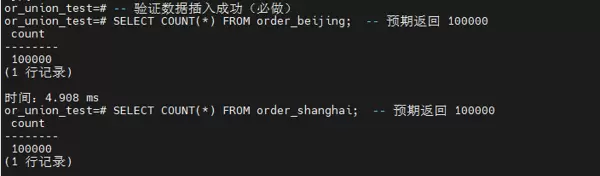
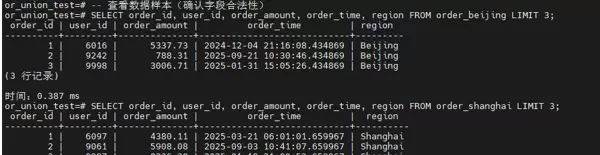
步骤 4:更新统计信息(优化器依赖关键)
执行 ANALYZE 操作以刷新表的统计信息,保障查询优化器能够基于最新的数据分布做出最优执行计划决策,这是高效查询的基础前提。

步骤 5:采用原始 OR 写法作为基准测试组
查询需求为:获取“北京2024年订单”或“上海用户ID=100”的订单,且订单金额大于5000的数据。
执行计划显示,order_beijing 和 order_shanghai 均发生 Seq Scan(全表扫描),外层由 Filter 节点进行条件过滤,在合并后的大量数据上进行筛选操作,整体开销较高。
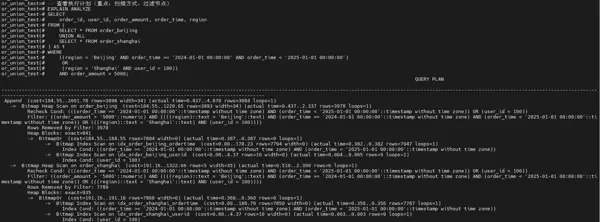
步骤 6:使用 UNION ALL 并将条件完全下推(优化方案一)
通过拆分逻辑,分别在子查询中精准施加过滤条件:
- 北京表利用 idx_order_beijing_ordertime 索引进行时间范围筛选;
- 上海表使用 idx_order_shanghai_userid 索引定位特定用户;
- 金额条件直接嵌入各子查询内部,实现早期过滤。
该方式仅需扫描数百条记录,显著减少I/O与计算负担。
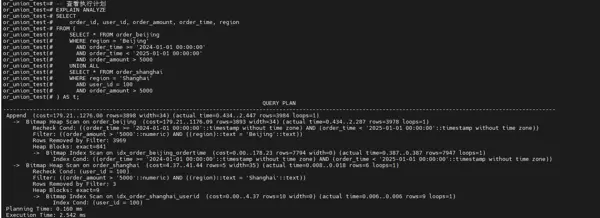
步骤 7:UNION ALL 配合外层条件(验证条件下推能力)
将金额过滤条件置于 UNION ALL 的外部SELECT中,观察执行计划变化。
结果表明,执行计划与“条件全下推”完全一致:优化器自动将 order_amount > 5000 条件下推至各自子查询中,北京表和上海表依然使用高效索引路径,实际扫描数据量未增加。
OR 改写为 UNION ALL 实现性能倍增
原始 OR 查询耗时约 5.002ms,而 UNION ALL 方案仅需约 2.54ms,性能提升接近一倍。
根本原因在于:
- OR 写法触发 BitmapOr 多索引合并机制,导致上海表需访问 935 个数据块,过滤多达 7789 条无效行;
- UNION ALL 将复杂条件分离,使每张表仅应用最匹配的单一索引(如北京按时间、上海按用户ID),避免了多索引组合带来的额外开销;
- 数据扫描范围从全表级别压缩至极小范围(上海表仅读取9个块),极大降低CPU与IO压力。
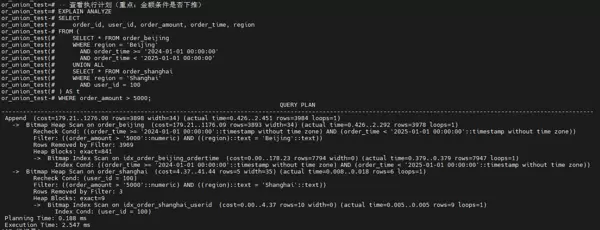
金仓优化器支持 UNION ALL 外层条件下推
“UNION ALL + 外层条件” 的执行计划与“条件全下推”几乎完全相同:
- 北京表中,金额条件被成功下推并与 region 判断共同作用于 Heap Scan 阶段;
- 上海表则在用户 ID=100 的 9 条结果中进一步过滤出满足金额条件的记录(仅排除3条);
- 最终执行时间分别为 2.547ms 与 2.542ms,差异可忽略,充分证明优化器具备强大的条件下推能力。
执行计划核心差异解析
原始 OR 写法局限性:
由于 OR 连接的是跨表的不同维度条件(北京的时间 + 上海的用户ID),优化器无法将其分解,只能尝试对两张表同时启用多个索引并通过 BitmapOr 合并结果,造成扫描范围扩大、中间数据膨胀、过滤成本上升。
UNION ALL 优势体现:
通过逻辑拆分,每个子查询独立处理自身相关的过滤条件,索引选择更加精确。上海表的数据块访问量从 935 锐减至 9,需过滤的无效行从 7789 降至 3,成为性能飞跃的关键所在。
总结:关键优化策略与落地价值
在金仓数据库环境中,将 OR 改写为 UNION ALL 是应对复杂多表查询的有效手段,通常可带来两倍以上的性能提升。同时,其优化器原生支持 UNION ALL 外层条件下推,无需手动重写即可兼顾代码简洁性与运行效率。
该方案广泛适用于以下场景:
- 多区域订单合并查询;
- 分库分表后的聚合分析;
- 异构条件下的联合检索。
此外,对于 LISTAGG 类型的聚合查询,设计包含“分组字段 + 排序字段 + 聚合字段”的覆盖索引,是实现极致性能的关键。配合定期执行 VACUUM ANALYZE,可确保仅索引扫描(Index Only Scan)生效,无需修改SQL即可达成高性能目标。
性能优化的本质:场景化精准施策
金仓数据库的性能调优并非依赖单一技巧,而是建立在完整闭环基础上的系统工程:
- 解析执行计划,识别瓶颈环节;
- 结合业务逻辑定位可优化点;
- 选择适配的改写策略或索引方案;
- 验证优化效果并持续监控;
- 根据数据增长与硬件环境动态调整。
这一过程强调对业务场景、数据规模与系统资源的综合考量,最终达成查询高效、写入稳定、资源可控的整体目标。
结语:一年深耕,收获颇丰
时光飞逝,回顾过去一年与金仓数据库的深度实践,技术认知不断深化,实战经验持续积累。
通过参与其系统化的培训体系,我深刻体会到“以考促学”的独特价值——认证考试不仅是能力检验,更是一次对数据库原理与实操技能的全面梳理。尤为珍贵的是,能够免费获取高质量学习资料,掌握契合职场发展的实用技术。这些沉淀下来的能力,已切实转化为解决实际问题的强大支撑,实现了从理论理解到工程落地的跨越。
年末将至,诚邀您共同参与金仓产品体验官活动。通过此次活动,您不仅可以深入探索金仓数据库的核心功能,还能与众多技术同行交流实战经验,切实提升专业能力。
在实际操作中深化理解,让技术知识真正落地应用,助力个人技能的持续积累与成长,为来年的职业进阶打下坚实基础。

 京公网安备 11010802022788号
京公网安备 11010802022788号







