


 雷达卡
雷达卡



人工智能之数据分析 Pandas
第八章 数据可视化
文章目录
- 前言
- 一、Pandas 可视化基础
- 二、Series 与 DataFrame 基础绘图
- 三、常用图表类型(通过 `kind` 参数指定)
- 四、详细图表示例与参数说明
- 五、通用绘图参数(适用于所有图表)
- 六、高级技巧与组合图
- 七、Pandas vs 专业可视化库
- 八、常见问题与解决方案
- 九、总结:Pandas 可视化最佳实践
- 后续
前言
本文将从以下四个方面系统、详尽且结合实战地讲解 Pandas 在数据可视化方面的完整功能:
- 基础绘图方法
- 常用图表类型
- 高级定制选项
- 与专业可视化工具的对比分析
内容覆盖全面,适合快速掌握 Pandas 的可视化能力。
一、Pandas 可视化基础
1. 核心原理
Pandas 的绘图功能本质上是基于 Matplotlib 的高层封装。它能够直接返回 Matplotlib 的图形对象,使得每个 Series 或 DataFrame 都可以调用绘图方法。
这种设计带来了简洁的语法结构,特别适用于探索性数据分析中对数据分布、趋势和变量间关系的快速查看。
.plot()matplotlib.axes.Axes2. 启用绘图支持(通常自动加载)
import pandas as pd import numpy as np import matplotlib.pyplot as plt # 推荐在 Jupyter 中使用,确保图形内嵌显示 %matplotlib inline
二、Series 与 DataFrame 基础绘图
1. Series 绘图(一维数据)
对于一维序列数据,可直接调用 .plot() 方法生成默认折线图,常用于时间序列的趋势展示。
s = pd.Series(np.random.randn(10).cumsum(), index=pd.date_range('2025-01-01', periods=10))
# 默认绘制折线图
s.plot()
plt.title('Series 折线图')
plt.show()
2. DataFrame 绘图(多列数据)
当处理包含多个字段的数据框时,每一列会自动生成一条曲线,形成多线折线图,便于比较不同变量的变化趋势。
df = pd.DataFrame(
np.random.randn(10, 4),
columns=['A', 'B', 'C', 'D'],
index=pd.date_range('2025-01-01', periods=10)
)
# 默认以各列为单位绘制折线
df.plot()
plt.title('DataFrame 多列折线图')
plt.show()
三、常用图表类型(通过 `kind` 参数指定)
| 图表类型 | `kind` 值 | 适用场景 |
|---|---|---|
| 折线图 | |
时间序列、趋势分析 |
| 柱状图 | |
分类数据之间的垂直比较 |
| 水平柱状图 | |
类别名称较长时更易读 |
| 直方图 | |
观察数值型数据的分布情况 |
| 箱线图 | |
识别数据分布特征及异常值 |
| 密度图 | |
平滑化的概率密度估计 |
| 面积图 | |
展示累计贡献或堆叠变化 |
| 散点图 | |
分析两个变量之间的相关性 |
| 六边形图 | |
大量点数据下的密度分布可视化 |
所有图表均可通过 .plot() 方法或指定 kind 参数来调用。
kindkinddf.plot(kind='xxx')df.plot.xxx()四、详细图表示例与参数说明
1. 折线图(Line Plot)— 默认图表
折线图是 Pandas 中最常用的图表之一,尤其适合展现随时间变化的趋势。
df.plot(
kind='line',
title='销售额趋势',
xlabel='日期',
ylabel='金额(万元)',
figsize=(10, 6),
grid=True,
style=['-', '--', '-.', ':'] # 自定义线型样式
)
plt.show()
2. 柱状图(Bar Plot)
柱状图适用于分类数据的对比。以下示例展示不同产品在两个季度的销量对比。
sales = pd.DataFrame({
'产品': ['手机', '电脑', '平板', '耳机'],
'Q1': [120, 80, 50, 30],
'Q2': [130, 85, 55, 35]
}).set_index('产品')
# 绘制垂直柱状图(默认)
sales.plot(kind='bar', figsize=(8, 5), title='各产品季度销量')
plt.xticks(rotation=0) # 横轴标签不旋转,保持水平
plt.show()
五、通用绘图参数(适用于所有图表)
以下参数可用于大多数 .plot() 调用中,提升图表可读性和美观度:
- title:设置图表标题
- xlabel / ylabel:设置坐标轴标签
- figsize:控制图像尺寸
- grid:是否显示网格线
- color:自定义颜色
- style:线条样式设定
- alpha:透明度调节
六、高级技巧与组合图
1. 子图(Subplots)
使用 subplots=True 可为每列数据单独绘制子图,避免图形重叠。
2. 双 Y 轴(用于不同量纲)
当两组数据单位不同时,可通过 secondary_y 参数启用双Y轴显示。
3. 分组柱状图(需数据重塑)
若需并列显示多个类别的柱子,应先对数据进行重塑(如使用 melt 或 pivot),再进行绘图。
七、Pandas vs 专业可视化库
Pandas 提供了便捷的基础绘图功能,但在图表美观性与灵活性上不如 Seaborn、Plotly 等专业库。
推荐使用策略:
- 探索阶段:优先使用 Pandas 快速出图
- 汇报/展示阶段:切换至 Seaborn 或 Plotly 实现更精美的视觉效果
示例:相同数据下,Seaborn 代码更简洁,配色更协调,图表更具专业感。
八、常见问题与解决方案
- 中文乱码:设置字体或修改 rcParams 解决显示问题
- 图形不显示(Jupyter 外):确认已调用 plt.show() 并正确配置后端
- 时间序列 X 轴格式混乱:使用 date_format 或 rot 参数优化标签排版
- 颜色自定义:通过 color 参数传入颜色列表或字典进行个性化设置
九、总结:Pandas 可视化最佳实践
Pandas 内置的可视化模块虽然简单,但非常实用。建议:
- 熟练掌握 .plot() 的基本用法和常见 kind 类型
- 善用通用参数提升图表表达力
- 结合 Matplotlib 进行细节调整
- 在需要高质量输出时转向专业库
合理利用这些技巧,可在数据分析全流程中高效完成数据洞察与结果呈现。
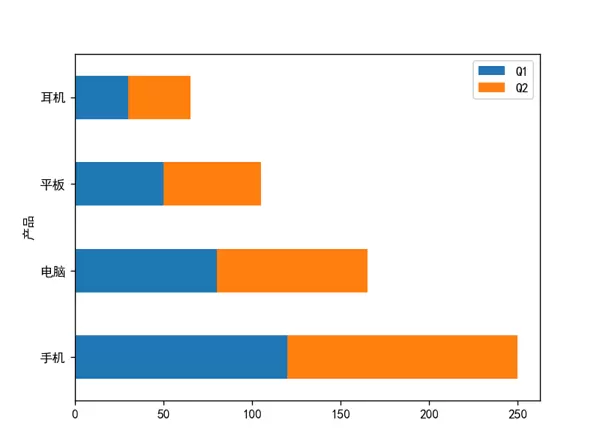
水平柱状图与堆叠展示
通过设置 plot 的 kind 参数为 'barh',可生成水平方向的柱状图。使用 stacked=True 可实现多个数据系列的堆叠显示,便于比较总体构成。
sales.plot(kind='barh', stacked=True) # 堆叠 plt.show()
直方图:观察数据分布形态
直方图用于查看单个变量的数据分布情况。可通过指定 bins 控制分组数量,alpha 调整透明度以增强可视化效果。
df['A'].plot(kind='hist', bins=20, alpha=0.7, title='A 列数据分布') plt.show()
对于多列数据,可以绘制重叠直方图进行对比分析:
df[['A', 'B']].plot.hist(alpha=0.5, bins=20) plt.show()
箱线图:识别异常值与分布特征
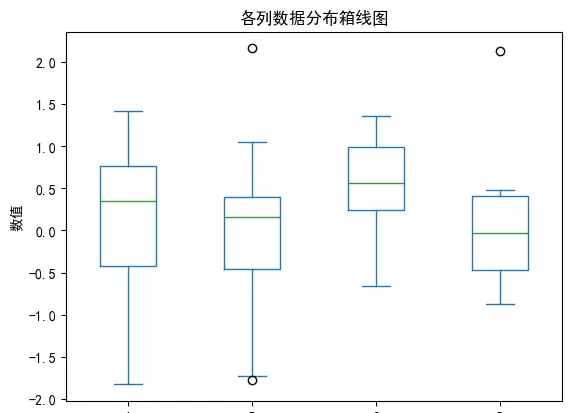
箱线图能够清晰展示各列数据的四分位数、中位数及潜在的离群点。适用于检测异常值和理解数据的离散程度。
df.plot(kind='box', title='各列数据分布箱线图')
plt.ylabel('数值')
plt.show()
散点图:探索两变量间的关系
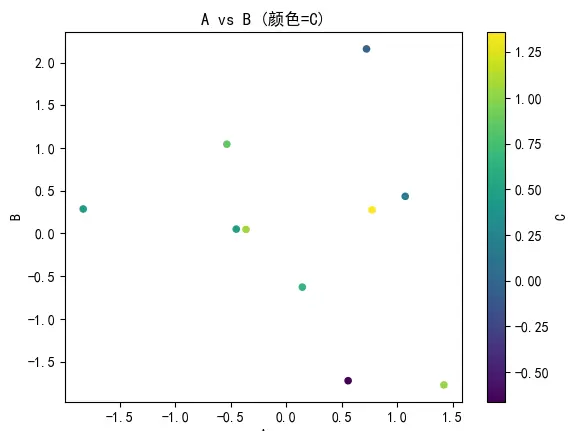
利用散点图可以直观地分析两个变量之间的相关性。通过引入第三变量作为颜色映射,进一步丰富信息维度。
df.plot( kind='scatter', x='A', y='B', c='C', # 颜色映射第三列 colormap='viridis', title='A vs B (颜色=C)' ) plt.show()
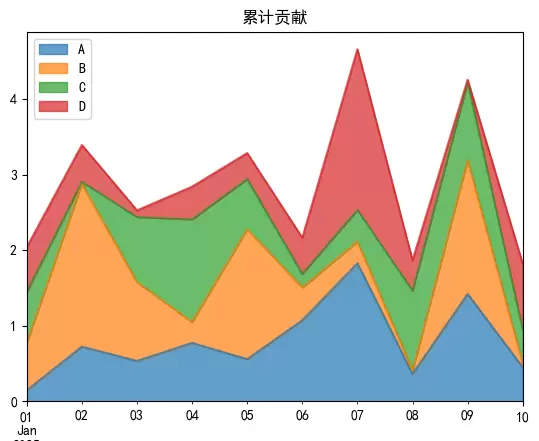
面积图:展现累计贡献趋势
面积图适合表示随时间或其他维度变化的累积量。启用 stacked 模式并调整透明度,有助于提升图表可读性。
df = df.abs() df.plot(kind='area', stacked=True, alpha=0.7, title='累计贡献') plt.show()
密度图(KDE):平滑化分布估计
核密度估计图(KDE)是对数据概率密度函数的非参数估计,相比直方图更平滑,能更好地反映连续分布的趋势。
df['A'].plot(kind='kde', title='A 列核密度估计') plt.show()

通用绘图参数汇总(适用于多种图表类型)
| 参数 | 说明 | 示例 |
|---|---|---|
| 图形大小(宽, 高) | 控制图像尺寸 | |
| 图表标题 | 添加主标题 | |
| 坐标轴标签 | 设置 x 和 y 轴名称 | |
| 显示网格 | 开启坐标网格线 | |
| 显示图例 | 是否显示图例(默认开启) | |
| 颜色 | 自定义线条或区域颜色 | |
| 透明度(0~1) | 调节填充或标记的透明度 | |
| x 轴标签旋转角度 | 防止标签重叠 | |
figsizetitlexlabelylabelgridlegendcoloralpharot高级绘图技巧与复合图表应用
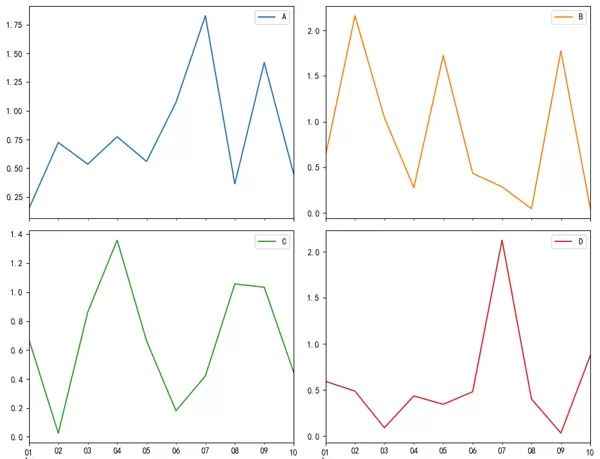
1. 子图布局(Subplots)
将多个图表排列在同一个画布中,每列数据单独成图,使用 subplots=True 并配合 layout 设置行列结构。
df.plot(subplots=True, layout=(2, 2), figsize=(10, 8)) plt.tight_layout() plt.show()
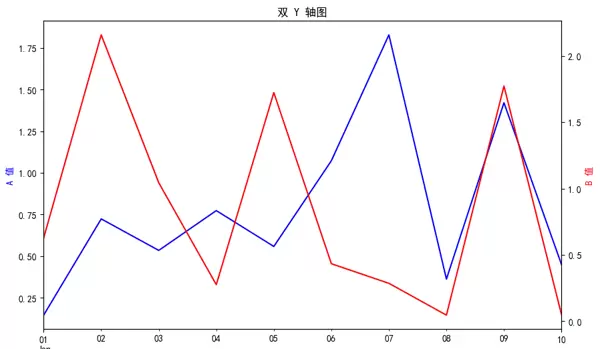
2. 双 Y 轴图表(适用于不同量纲变量)
当两个变量单位不同时,可通过共享 x 轴的双 y 轴方式在同一图中展示其趋势关系。
ax = df['A'].plot(figsize=(10, 6), color='blue', label='A')
ax2 = ax.twinx() # 共享 x 轴
df['B'].plot(ax=ax2, color='red', label='B')
ax.set_ylabel('A 值', color='blue')
ax2.set_ylabel('B 值', color='red')
plt.title('双 Y 轴图')
plt.show()
注意:Pandas 原生并不直接支持双Y轴功能。旧版本可能允许某些操作,但建议采用 Matplotlib 的方式实现。
secondary_y.plot()3. 分组柱状图(需数据格式转换)
为了绘制分组柱状图,通常需要将宽格式数据转换为长格式,以便按类别分组显示。
# 将宽表转为长表(便于分组) sales_long = sales.reset_index().melt(id_vars='产品', var_name='季度', value_name='销量') print(sales_long)
结合 Seaborn 可更便捷地完成此类图表:
plt.figure(figsize=(10, 6))
sns.barplot(x='产品', y='销量', hue='季度', data=sales_long)
plt.title('各产品季度销量')
plt.show()
Pandas 与主流可视化库对比分析
| 功能 | Pandas | Seaborn | Plotly |
|---|---|---|---|
| 易用性 | ★★★★★(极简) | ★★★★☆ | ★★★☆☆ |
| 统计图表支持 | 基础 | ★★★★★(含箱线图、小提琴图等) | ★★★☆☆ |
| 美观度 | 一般(可定制) | ★★★★★(默认美观) | ★★★★★(交互式) |
| 交互性 | ☆ | ☆ | ★★★★★ |
| 大数据性能 | 一般 | 一般 | 较好(基于WebGL) |
| 适用场景 | 快速EDA | 发表级静态图 | 仪表盘、Web应用 |
推荐使用策略
- 探索阶段:优先使用 Pandas 快速生成图表,辅助初步数据分析。
- 报告/论文输出:选用 Seaborn 制作高质量、视觉效果出色的静态图像。
- 交互展示需求:采用 Plotly 或 Dash 构建动态、可交互的可视化界面。
示例:Seaborn 实现更简洁美观的散点图
import seaborn as sns # 散点图 + 回归线 sns.scatterplot(data=df, x='A', y='B', hue='C')
sns.regplot(data=df, x='A', y='B', scatter=False)
plt.show()
# 按类别绘制箱线图
sns.boxplot(data=sales_long, x='产品', y='销量', hue='季度')
plt.show()
八、常见问题及对应解决方法
1. 中文显示异常(乱码)
设置中文字体以支持正常显示:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 适用于 Windows 系统
plt.rcParams['axes.unicode_minus'] = False # 确保负号正确显示
2. 图形无法显示(尤其在非 Jupyter 环境下)
需显式调用绘图展示函数:
plt.show()
3. 时间序列的 X 轴格式混乱
通过格式化与旋转标签提升可读性:
df.plot()
plt.gca().xaxis.set_major_formatter(plt.matplotlib.dates.DateFormatter('%Y-%m'))
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
df.plot()
4. 自定义颜色方案
在绘图时指定所需颜色列表:
df.plot(color=['#FF5733', '#33FF57', '#3357FF'])
df.plot.bar()
九、总结:Pandas 可视化的最佳实践建议
根据不同的分析场景选择合适的可视化方式:
- 快速查看数据趋势 —— 使用折线图进行直观观察。
df.plot.hist() - 比较不同类别的数据 —— 推荐使用柱状图或分组箱线图。
df.plot.kde() - 检查变量的数据分布情况 —— 可选用直方图或密度图。
df.plot.scatter(x, y) - 探索变量之间的关系 —— 散点图或回归拟合图更为合适。
df.plot.box() - 识别异常值 —— 箱线图是有效的工具。
- 需要高质量图表用于发表或展示 —— 建议切换至 Seaborn 实现更美观的效果。
- 希望实现交互式图表 —— 推荐使用 Plotly 替代原生绘图。
核心提示:
Pandas 的可视化功能如同数据分析中的“瑞士军刀”,适合快速探索和初步洞察。虽然不适合直接作为最终成果交付,但能显著提升分析效率与迭代速度。

 京公网安备 11010802022788号
京公网安备 11010802022788号







