


 雷达卡
雷达卡



2025年最新高频Java面试题整理
本套面试题专为准备求职或计划跳槽的初、中、高级程序员打造,同时也适用于希望查漏补缺、持续提升技术能力的开发者。题目覆盖多个核心技术领域,包括但不限于:Java基础与并发编程、MySQL数据库、Redis缓存、JVM原理等。
以下是部分精选题目内容:
Java 基础 & 并发(共33题)
1. 简述 HashMap 的底层实现原理?
HashMap 是基于哈希表实现的键值对存储结构。其核心机制是通过键(key)的哈希值来确定在数组中的索引位置,采用“数组 + 链表”结构处理哈希冲突;从 Java 8 开始,在链表长度超过阈值时会转换为红黑树,即“数组 + 链表 + 红黑树”的混合结构。
HashMap 使用 key 的 hashCode() 方法计算初始哈希值,并经过扰动函数处理以增强分布均匀性,减少碰撞概率。最终通过 (n - 1) & hash 的方式定位桶位置(n 为数组长度),替代了早期版本中的 indexFor 方法。
默认初始容量为 16,负载因子为 0.75。当元素数量超过容量 × 负载因子(即 12)时,触发扩容操作,容量翻倍并重新进行元素迁移。该过程较为耗时,频繁扩容将影响性能表现。
2. ConcurrentHashMap 在 JDK 1.7 和 JDK 1.8 中有何区别?
JDK 1.7 版本的 ConcurrentHashMap 采用分段锁(Segment)机制,每个 Segment 相当于一个独立的 HashTable,彼此之间互不影响,支持最多 16 个线程并发访问(默认 Segment 数量为 16),从而提高了并发度。
而到了 JDK 1.8,完全摒弃了 Segment 设计,转而使用更细粒度的锁控制:仅对链表头节点或红黑树根节点加 synchronized 锁,插入则依赖 CAS 操作。这种改进显著降低了锁竞争,提升了高并发场景下的吞吐量。
此外,数据结构也由原来的“数组 + 链表”升级为与 HashMap 一致的“数组 + 链表 + 红黑树”。同时,size() 方法的实现也发生了变化,不再依赖全局锁统计元素个数,而是通过 baseCount 和 CounterCell 数组进行并发累加,提高准确性与效率。
3. 为什么 JDK 1.8 对 HashMap 引入红黑树?
在 JDK 1.8 之前,HashMap 使用链表解决哈希冲突。当发生大量哈希碰撞时,链表长度增长,导致查找、插入和删除的时间复杂度退化至 O(n),严重影响性能。
为此,JDK 1.8 引入红黑树优化:当某个桶中链表长度达到 8 且当前数组长度大于等于 64 时,链表自动转化为红黑树;当长度回落至 6 以下时,又会退化回链表。红黑树作为自平衡二叉搜索树,能保证插入、删除和查找操作的时间复杂度稳定在 O(log n),有效避免极端情况下的性能下降。
4. 除了引入红黑树,JDK 1.8 还对 HashMap 做了哪些关键改进?
- 哈希函数优化:增强了扰动函数的设计,使 key 的 hashCode 高低位充分参与运算,提升哈希值分布的均匀性,降低冲突概率。
- 扩容机制改进:扩容时不重新计算每个元素的哈希值,而是根据原数组长度的高位判断元素是否需要移动。若高位为 0,则保留在原位置;为 1 则迁移到新位置(原索引 + oldCap)。此方法大幅减少了计算开销,提升迁移效率。
- 插入方式变更:由原来的头插法改为尾插法。虽然头插法插入速度快,但在多线程环境下扩容可能导致链表成环,引发死循环问题。尾插法虽需遍历,但避免了这一安全隐患,更适合并发场景。
5. Java 中常见的集合类有哪些?请简要说明其特点
Java 集合框架主要分为两大体系:Collection 接口和 Map 接口。前者用于存储单一对象,后者用于存储键值对映射关系。
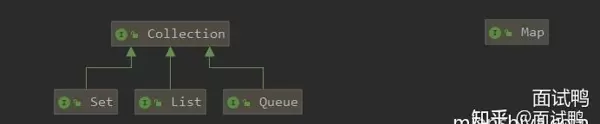
Collection 接口下主要包括 List、Set 和 Queue 三个子接口:
- List 接口:有序、可重复。
- ArrayList:基于动态数组实现,查询高效,增删较慢。
- LinkedList:基于双向链表实现,增删快,查询慢。
- Vector:线程安全的动态数组,功能类似 ArrayList,但性能较低。
- Set 接口:不允许重复元素,具体行为取决于实现类。
- HashSet:基于哈希表实现,不保证顺序。
- LinkedHashSet:维护插入顺序,底层由链表+哈希表构成。
- TreeSet:基于红黑树实现,元素自然排序或按比较器排序。
- Queue 接口:常用于实现队列逻辑。
- PriorityQueue:优先级队列,依据自然顺序或 Comparator 排序。
- LinkedList:也可作为双端队列使用,支持 FIFO 操作。
Map 接口:用于存储键值对,常见实现包括 HashMap、ConcurrentHashMap、TreeMap、LinkedHashMap 等,各自适用于不同场景。
需要注意的是,“Set 是无序集合”这一说法并不绝对准确,应结合具体实现类来看——例如 TreeSet 和 LinkedHashSet 都具有明确的排序规则。
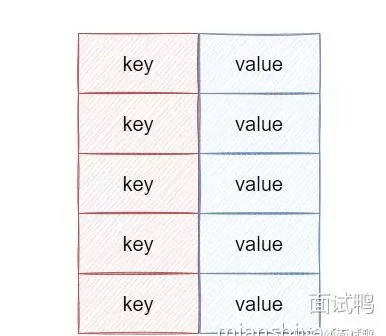
存储结构中的键值对机制,是指为某个对象(value)分配一个唯一的 key,通过该 key 可以快速定位并获取对应的 value 值。
常见的 Java 集合实现中,基于键值对的数据结构包括:
- HashMap:底层采用哈希表实现,不保证键值对的顺序,且不允许键重复。
- LinkedHashMap:结合链表与哈希表,能够维持元素插入时的顺序,同样不允许键重复。
- TreeMap:基于红黑树结构,使得键值对按照键的自然顺序或自定义排序进行组织,不允许键重复。
- Hashtable:线程安全的哈希表实现,不支持键或值为 null。
- ConcurrentHashMap:专为高并发设计的线程安全映射结构,也不允许键或值为 null。
JVM 相关(7 题)
- Java 8 中移除了永久代(PermGen),转而引入元空间(Metaspace),主要原因是为了更好地管理类元数据,避免因 PermGen 空间固定而导致的内存溢出问题。元空间使用本地内存,可动态扩展,提升了 JVM 的稳定性和性能。
- HashMap 的默认负载因子设为 0.75,是在时间和空间成本之间的一种权衡。过高的负载因子会增加冲突概率,影响查找效率;过低则浪费空间。0.75 在实践中被证明是较为理想的平衡点。
- HashMap 的扩容机制是当元素数量超过容量与负载因子的乘积时触发扩容,容量扩大为原来的两倍,并重新计算每个元素的位置。这一过程称为 rehashing。
- HashMap 扩容时采用 2 的 n 次方倍,是为了在计算索引位置时可以通过位运算(&)替代取模运算(%),从而提升性能。前提是容量为 2 的幂次才能保证分布均匀。
- 数组和链表在 Java 中的主要区别在于:数组具有连续的内存空间,支持随机访问,但插入删除效率低;链表内存非连续,通过指针连接节点,插入删除高效,但只能顺序访问。
- Java 线程池的核心线程数在运行过程中理论上不可直接修改,但可通过 ThreadPoolExecutor 提供的 setCorePoolSize() 方法动态调整。
- 创建多线程的方式主要有:继承 Thread 类、实现 Runnable 接口、实现 Callable 接口配合 FutureTask、使用线程池提交任务等。
Java 并发与内存模型(17 题)
- final 关键字可以保证变量的可见性。一旦 final 变量初始化完成,在其他线程中就能看到其正确值,这是 JMM 对 final 的语义保障。
- 原子性指操作不可中断;可见性指一个线程对共享变量的修改能及时被其他线程感知;有序性指程序执行顺序按照代码逻辑进行,防止指令重排影响结果。
- CAS(Compare-And-Swap)是一种无锁算法,通过比较当前值与预期值是否一致来决定是否更新,常用于实现原子类如 AtomicInteger。
- ThreadLocal 的 key 使用弱引用是为了防止内存泄漏。当 ThreadLocal 实例不再被强引用时,GC 可以回收它,避免 Entry 中 key 永久存在导致内存无法释放。
- 编译执行是将源码一次性编译成机器码再执行,解释执行是逐行翻译执行。JVM 通常采用“解释 + 即时编译(JIT)”混合模式,热点代码会被 JIT 编译优化。
- 死锁产生的条件包括互斥、持有并等待、不可剥夺、循环等待。避免方式有:破坏任一条件、按序申请资源、使用超时机制、检测与恢复策略。
- Java 线程池基于工作线程模型,核心是维护一组线程来执行任务队列中的任务。ThreadPoolExecutor 是主要实现类,包含核心线程数、最大线程数、任务队列、拒绝策略等组件。
- 线程池的拒绝策略包括:AbortPolicy(抛异常)、CallerRunsPolicy(由调用者执行)、DiscardPolicy(静默丢弃)、DiscardOldestPolicy(丢弃最老任务)。
- 合理设置线程数需根据任务类型:CPU 密集型建议设置为 CPU 核心数 + 1;IO 密集型可设为 CPU 核心数 × (1 + 平均等待时间/处理时间),一般为 2~4 倍核数。
- 常用的并发工具类有 CountDownLatch、CyclicBarrier、Semaphore、Exchanger、Phaser 以及各种 BlockingQueue 实现。
- Synchronized 是 JVM 内建关键字,自动加锁解锁;ReentrantLock 是 API 层面的锁,功能更强大,支持公平锁、可中断、超时获取等特性。
- synchronized 通过对象头中的 Mark Word 实现锁机制,在 JVM 层面借助 monitor 对象完成同步控制,底层依赖操作系统互斥量(mutex)。
- 优化锁使用的策略包括:减少锁范围、降低锁粒度、使用读写分离锁、避免锁竞争、利用无锁结构(如 CAS)、使用局部变量代替共享状态等。
- 常见的垃圾收集器有 Serial、Parallel Scavenge、Parallel Old、CMS、G1、ZGC、Shenandoah 等,各自适用于不同场景。
- 主流的垃圾回收算法包括标记-清除、标记-整理、复制算法,以及分代收集思想下的组合应用。
- Java 内存模型(JMM)定义了多线程环境下变量的访问规则,确保共享变量的可见性、原子性和有序性,是 volatile、synchronized、final 等关键字的理论基础。
- volatile 关键字的作用是保证变量的可见性和禁止指令重排序,但不保证原子性,适合状态标志位等场景。
- ABA 问题是 CAS 操作中可能出现的现象:值从 A 变为 B 又变回 A,CAS 误判未变化。可通过添加版本号(如 AtomicStampedReference)解决。
- Java 中线程生命周期分为新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、等待(Waiting)、超时等待(Timed Waiting)、终止(Terminated)七个状态。
- AQS(AbstractQueuedSynchronizer)是构建锁和同步器的基础框架,通过一个 int 成员变量表示同步状态,利用 FIFO 队列管理等待线程,广泛应用于 ReentrantLock、Semaphore 等。
MySQL 相关(32 题)
- JVM 由类加载器子系统、运行时数据区(方法区、堆、栈、程序计数器、本地方法栈)、执行引擎、本地库接口等部分组成。
- JVM 垃圾回收调优的主要目标是减少 GC 停顿时间、提高吞吐量、避免 OOM,特别是在大内存、高并发场景下保持系统稳定性。
- 垃圾回收调优方法包括选择合适的收集器、调整新生代与老年代比例、合理设置堆大小、监控 GC 日志、分析对象生命周期分布等。
- 常用 JVM 参数包括 -Xms、-Xmx(堆初始与最大大小)、-Xmn(新生代大小)、-XX:MaxPermSize(旧版永久代)、-XX:MetaspaceSize(元空间)、-XX:+UseG1GC(指定收集器)等。
- JVM 内存区域划分为:程序计数器、Java 虚拟机栈、本地方法栈、堆(存放对象实例)、方法区(存储类信息、常量、静态变量)等。
- 可能导致 OOM 的情况有:堆内存不足(OutOfMemoryError: Java heap space)、元空间耗尽(Metaspace)、栈溢出(StackOverflowError 或 unable to create new native thread)、直接内存溢出等。
- 分析 JVM 内存占用可使用 jstat、jmap、jconsole、VisualVM 等工具查看实时内存状况;OOM 后可通过生成的 dump 文件使用 MAT、jhat 等工具进行深入分析。
- MySQL 索引最左前缀匹配原则指在联合索引中,查询条件必须从最左边开始连续匹配,否则无法有效利用索引。
- 脏读是指读到了未提交事务的数据;不可重复读指同一事务内多次读取同一数据得到不同结果;幻读指同一查询在事务内返回不同的行集合。
- MySQL 存储引擎主要有 InnoDB、MyISAM、Memory、Archive 等。InnoDB 支持事务、行锁、外键;MyISAM 不支持事务,仅表锁,适合读多写少场景。
- 覆盖索引指查询的所有字段都包含在索引中,无需回表即可获取全部数据,显著提升查询性能。
- 索引下推(ICP)是 MySQL 5.6 引入的优化技术,允许在存储引擎层对索引条目进行条件过滤,减少回表次数。
- InnoDB 中聚簇索引的叶子节点直接存储完整的数据行,主键即聚簇索引;非聚簇索引(二级索引)叶子节点存储主键值,需回表查询完整数据。
- 回表是指通过二级索引找到主键后,再到聚簇索引中查找对应完整数据记录的过程。
- 使用索引不一定有效,比如存在索引失效场景(如函数操作、类型转换、最左前缀不满足)。可通过 EXPLAIN 分析执行计划排查索引使用情况。
- 索引并非越多越好。过多索引会增加写操作开销(插入、更新、删除需维护索引),占用更多存储空间,并可能影响优化器选择最优执行计划。
- B+ 树查询全过程:从根节点开始,逐层向下查找,直到叶子节点定位到具体数据页或主键值,最终获取所需记录。
- MySQL 选用 B+ 树作为索引结构,因其具备良好的磁盘 I/O 性能、支持范围查询、树高度较低、所有数据位于叶子层便于遍历等优势。
- 三层 B+ 树通常可存储千万级数据。假设每个节点扇出为 1000,则三层可容纳约 10^9 条记录。
- 一条 SQL 在 MySQL 中的执行流程包括:连接器验证权限、查询缓存(若开启)、解析器语法分析、预处理器校验语义、优化器生成执行计划、执行器调用存储引擎接口执行。
- MySQL 通过 redo log 实现事务持久性,undo log 实现原子性与一致性,配合锁机制和 MVCC 实现隔离性。
- 二阶段提交用于保证 redo log 与 binlog 的一致性,第一阶段 prepare,第二阶段 commit,确保崩溃恢复时事务状态一致。
- 长事务可能导致锁持有时间过长、undo log 积压、回滚段膨胀、主从延迟等问题,应尽量缩短事务范围。
- MVCC(多版本并发控制)通过保存数据的历史版本,使读操作不加锁也能获得一致性视图,提升并发性能。
- 事务隔离级别包括:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)、串行化(Serializable)。
- MySQL 默认隔离级别为可重复读(Repeatable Read),目的是防止不可重复读和幻读(通过间隙锁实现),同时兼顾并发性能。
- MySQL 锁类型包括:全局锁、表级锁、行级锁、意向锁、共享锁(S)、排他锁(X)、间隙锁、临键锁等。
- 乐观锁假设冲突较少,通过版本号或时间戳控制更新;悲观锁假设总会冲突,直接加锁。前者适用于低冲突场景,后者适用于高竞争环境。
- MySQL 死锁可通过 wait-for graph 检测机制自动发现,系统会选择牺牲代价较小的事务进行回滚,解除死锁。
- count(*) 和 count(1) 基本等价,统计所有行数(含 null);count(字段名) 只统计该字段非 null 的行数。
- SQL 调优手段包括:添加合适索引、避免全表扫描、优化查询结构、分解复杂查询、避免 select *、使用 limit 分页等。
- EXPLAIN 可查看 SQL 执行计划,关注 type(访问类型)、key(实际使用索引)、rows(扫描行数)、Extra(附加信息)等字段判断性能瓶颈。
- 深度分页问题可通过游标方式(如记录上一次最后 ID)、延迟关联、ES 替代等方式解决,避免使用 offset 过大的 limit 查询。
- 主从同步机制通过 binlog 实现,主库记录变更日志,从库拉取并重放日志,达到数据一致性。
- 主从同步延迟可通过优化网络、提升从库硬件性能、并行复制、减少大事务、监控延迟指标等方式缓解。
MySQL 相关问题
当在 MySQL 中执行 select * from 一个包含一千万行数据的表时,内存是否会显著上升,主要取决于多个因素,包括查询是否被限制、客户端如何处理结果集、服务器配置以及是否有适当的索引。若未加 limit 或 where 条件,且客户端一次性拉取全部数据,则可能造成内存激增,尤其是在应用层缓存了整个结果集的情况下。合理使用分页和流式读取可有效避免该问题。
在为 MySQL 建立索引时,需注意以下几点:选择区分度高的列作为索引;避免对频繁更新的字段建立过多索引以减少写入开销;尽量使用组合索引而非多个单列索引;注意最左前缀原则;同时考虑索引覆盖以提升查询效率。
然而,并非所有场景都适合创建索引。例如,在数据量极小的表上建索引意义不大;对于频繁插入、更新但很少查询的表,索引反而会拖慢性能;另外,低基数列(如性别)也通常不推荐单独建索引,因其选择性差,优化器可能不会使用。
消息队列相关问题(共 16 题)
RabbitMQ
实现延迟队列的一种常见方式是利用 RabbitMQ 的死信交换机(DLX)机制。通过设置消息的 TTL(生存时间),当消息过期后会被自动投递到绑定的死信队列中,从而达到延迟消费的效果。
消息进入死信交换机的条件主要有三种:消息被拒绝(basic.reject 或 basic.nack)并设置 requeue=false;消息 TTL 过期;队列达到最大长度限制而无法容纳新消息。
无法路由的消息,即没有匹配到任何绑定规则的消息,默认会被丢弃,除非设置了 mandatory 标志位。若设置了该标志,RabbitMQ 会触发 return 机制将消息返回给生产者。
Kafka
Kafka 逐渐抛弃 Zookeeper 的原因是出于架构简化与性能优化的考量。Zookeeper 虽然提供了可靠的协调服务,但在元数据管理方面存在瓶颈,难以支撑超大规模集群的实时变更需求。Kafka 自研的 KRaft 协议替代了 Zookeeper,实现了更高效的控制器选举与元数据同步。
在早期版本中,Zookeeper 主要承担了 Kafka 集群的元数据存储任务,如 broker 注册、主题分区状态维护、消费者组协调等。它确保了分布式环境下的一致性与高可用性。
Kafka 的事务消息机制允许生产者跨多个分区发送一组消息,并保证这些消息要么全部成功提交,要么全部回滚。其实现依赖于事务协调器(Transaction Coordinator)与事务日志(Topic __transaction_state),并通过两阶段提交协议完成。
RocketMQ
RocketMQ 的事务消息采用“半消息”机制实现。生产者首先发送一条不对外可见的半消息至 Broker,随后执行本地事务逻辑,最后根据执行结果向 Broker 提交或回滚消息状态。Broker 在收到确认后才会将消息设为可消费状态。
这种机制的缺点在于存在一定的延迟,且需要额外的检查机制来处理异常情况下的事务状态回查。此外,事务消息仅适用于异步场景,不适合高实时性要求的业务。其他类似的事务消息实现还包括 ActiveMQ 的 XA 事务支持和 Kafka 的幂等生产者 + 事务机制。
引入消息队列的主要目的包括:解耦系统模块、削峰填谷缓解流量压力、异步处理提高响应速度、保障最终一致性以及支持分布式事务等。
常见的消息模型有三种:点对点(P2P)模型,消息被一个消费者消费;发布/订阅模型,消息广播给多个订阅者;以及请求/回复模型,用于双向通信。
处理重复消息的关键在于实现消费端的幂等性。可通过唯一标识+状态记录、数据库约束、Redis 分布式锁等方式防止重复操作。
保证消息有序性的方法依赖于具体中间件。例如,在 Kafka 中可通过单一分区保证顺序;在 RocketMQ 中可使用顺序消息接口确保同一队列中的消息按序处理。
面对消息堆积问题,应从生产和消费两端分析原因。可通过增加消费者实例、优化消费逻辑、批量拉取、限流降级等方式进行处理。
为防止消息丢失,需在三个环节加强控制:生产者端启用 confirm 机制;Broker 端开启持久化配置;消费者端关闭自动提交 offset,改为手动提交以确保处理完成后再确认。
消息队列通常设计为拉模式(Pull),即消费者主动从 Broker 获取消息。相比推模式(Push),拉模式能更好地控制消费速率,避免消费者过载。但其缺点是可能存在空轮询带来的资源浪费。因此,部分系统结合长轮询实现准实时推送效果。
推拉模式各有优劣:推模式实时性强,适合低延迟场景,但难以应对消费者处理能力差异;拉模式则更具弹性,便于流量控制,但实现复杂度较高。
RocketMQ 不使用 Zookeeper 作为注册中心的原因在于其自身实现了轻量级的 NameServer 机制,具备更高的性能与更低的依赖复杂度。NameServer 负责路由信息的注册与发现,虽不强一致,但满足最终一致性要求,更适合大规模消息系统的运行环境。
设计模式相关问题(共 11 题)
常见的设计模式包括单例模式、工厂模式、策略模式、观察者模式、代理模式、模板方法模式、责任链模式等。它们广泛应用于框架开发、业务解耦、行为扩展等场景。
策略模式定义了一系列算法,并将每种算法封装起来,使它们可以互换。常用于根据不同条件切换计算逻辑,比如支付方式选择、折扣策略实现等。
责任链模式允许多个对象有机会处理请求,从而避免请求发送者与接收者之间的耦合。典型应用场景包括审批流程、异常处理链、过滤器链等。
模板方法模式在抽象类中定义了一个算法骨架,允许子类在不改变结构的前提下重写特定步骤。适用于流程固定但细节可变的场景,如 Servlet 的 doGet/doPost 方法、JUnit 测试框架等。
观察者模式定义了一种一对多的依赖关系,当一个对象状态发生变化时,所有依赖它的对象都会得到通知并自动更新。常用于事件驱动系统、GUI 组件监听、发布-订阅机制等。
代理模式为其他对象提供一种代理以控制对该对象的访问。常见用途包括远程代理、虚拟代理、保护代理、日志记录、权限校验等。
简单工厂模式通过一个工厂类根据传入参数决定创建哪种子类对象。它不属于 GoF 23 种经典模式之一,但因其简洁实用而广受欢迎。
工厂模式与抽象工厂模式的区别在于:前者针对的是同一类产品族的创建,后者则面向多个产品族的组合创建。抽象工厂强调一系列相关或相互依赖对象的创建,而不指定具体类。
设计模式是一套被反复验证、经过抽象总结的优秀解决方案模板,用于解决软件设计中常见问题。其作用在于提升代码复用性、可维护性和可扩展性,降低模块间的耦合度。
单例模式的实现方式主要包括:饿汉式(静态常量)、懒汉式(线程安全版)、双重检查锁定、静态内部类、枚举类等。其中,枚举法不仅能防止反射攻击,还能保证序列化安全,是最推荐的方式。
Netty 在设计中广泛应用了多种模式,如 Reactor 模式处理 I/O 事件、责任链模式构建 ChannelPipeline、工厂模式创建 ChannelHandler、单例模式管理共享资源等。
Spring 框架相关问题(共 19 题)
Spring 启动过程始于 ApplicationContext 的初始化。容器加载 Bean 定义信息,执行 BeanFactoryPostProcessor,注册 BeanPostProcessor,然后依次实例化单例 Bean 并完成依赖注入,最后发布上下文刷新事件。
Spring 框架中运用的设计模式包括:工厂模式(BeanFactory)、单例模式(默认作用域)、代理模式(AOP 实现)、模板方法模式(JdbcTemplate)、观察者模式(事件监听机制)、适配器模式(HandlerAdapter)等。
Spring 支持七种事务传播行为,常用的有 REQUIRED、REQUIRES_NEW、SUPPORTS、NOT_SUPPORTED、MANDATORY、NEVER 和 NESTED。它们决定了当前事务上下文中方法调用时如何参与或创建事务。
Spring Boot 的启动流程始于带有 @SpringBootApplication 注解的主类,通过 SpringApplication.run() 方法启动。期间会进行环境准备、应用上下文创建、自动配置加载、内嵌 Web 容器初始化等一系列操作。
自动配置的核心机制基于条件注解(@ConditionalOnClass、@ConditionalOnMissingBean 等),结合 spring.factories 文件中声明的配置类,在满足特定条件时自动装配组件。
Starter 是 Spring Boot 提供的一种便捷依赖管理方式,封装了某一功能所需的全部依赖与默认配置,开发者只需引入对应 starter 即可快速集成,无需手动配置。
Spring Boot 通过 main 方法启动 Web 项目,本质是通过 SpringApplication.run() 创建应用上下文,并根据 classpath 判断是否存在 Web 依赖(如 Tomcat、Spring MVC),若有则启动内嵌容器并部署应用。
Spring Boot 的核心特性包括:自动配置、起步依赖、内嵌容器、外部化配置、健康检查与监控、无代码生成和 XML 配置。
Spring Boot 是基于 Spring 框架的快速开发脚手架,旨在简化 Spring 应用的初始搭建及开发过程,实现“约定优于配置”的理念。
Spring IOC(控制反转)是指将对象的创建和依赖关系的管理交给容器处理,而不是由程序代码直接控制。这样可以降低耦合度,提升灵活性。
Spring AOP 默认使用两种动态代理技术:JDK 动态代理(基于接口)和 CGLIB 动态代理(基于继承)。前者要求目标类实现接口,后者可在无接口时生成子类实现代理。
AOP(面向切面编程)是一种编程范式,用于将横切关注点(如日志、事务、安全)从业务逻辑中分离出来,通过织入机制统一处理,增强代码模块化。
Spring 由多个重要模块组成,包括 Core Container(Core、Beans、Context、SpEL)、Data Access/Integration(JDBC、ORM、Transactions)、Web(MVC、WebSocket)、AOP、Instrumentation、Messaging 等。
循环依赖指两个或多个 Bean 相互依赖,形成闭环引用。Spring 能够解决部分类型的循环依赖,主要是单例 Bean 的 setter 注入方式。
Spring 通过三级缓存机制解决循环依赖问题:一级缓存存放完全初始化的 Bean;二级缓存存放早期暴露的 Bean(尚未完成属性填充);三级缓存存放 Bean 工厂对象,用于生成代理或原始对象。
之所以需要三级缓存而非二级,是为了支持 AOP 场景下代理对象的正确创建。如果只有两级缓存,在涉及代理时可能出现获取的是原始对象而非代理对象的问题。
Spring Bean 的生命周期包括:实例化、属性赋值、初始化前(postProcessBeforeInitialization)、初始化(init-method / InitializingBean)、初始化后(postProcessAfterInitialization)、使用阶段、销毁前(preDestroy)和销毁(destroy-method / DisposableBean)。
Spring MVC 的工作原理如下:前端控制器 DispatcherServlet 接收请求,委托 HandlerMapping 查找处理器,通过 HandlerAdapter 执行处理器方法,ModelAndView 返回视图解析器 ViewResolver 解析视图,最终渲染响应内容。
Spring 中的 DI(依赖注入)指的是容器在创建 Bean 时,自动为其注入所依赖的对象,无需手动查找或创建。注入方式包括构造函数注入、setter 注入和字段注入。
Redis 相关问题(共 31 题)
Redis 集群采用分片机制实现数据分布,将键空间划分为 16384 个槽位,每个节点负责一部分槽。客户端根据 key 计算 CRC16 值并映射到相应节点进行读写操作。
Redis 集群在极端网络分区情况下可能出现脑裂问题,即多个主节点认为自己是合法主节点而导致数据不一致。可通过配置 min-replicas-to-write 和 min-replicas-max-lag 参数降低风险。
Redis 中实现分布式锁常用命令包括 SETNX、EXPIRE、DEL,推荐使用 SET 命令的 NX EX 选项保证原子性。还可借助 Redisson 等客户端工具简化操作。
实现过程中可能遇到的问题包括:锁未设置超时导致死锁、非原子性操作引发竞争、主从切换时锁丢失、误删他人锁等。应通过 Lua 脚本保证原子性、添加唯一标识等方式规避。
Redisson 分布式锁的原理基于 Redis 的 pub/sub 机制与 Lua 脚本。它实现了可重入锁、公平锁、联锁等多种类型,并支持自动续期(watchdog 机制),有效防止因业务执行时间过长导致锁失效。
利用 Redis 的有序集合(ZSet)可高效实现排行榜功能。成员作为用户 ID,分数作为排名依据,通过 ZADD 添加数据,ZREVRANK 查询排名,ZRANGE 获取 TopN 结果。
为保证缓存与数据库的数据一致性,常用策略包括:先更新数据库再删除缓存(Cache Aside)、双写一致性(Write Through)、写穿+缓存失效(Write Behind)等。实际中还需结合延迟双删、消息队列补偿等手段增强可靠性。
Redis 快速的原因在于:纯内存操作、非阻塞 I/O 多路复用(epoll/kqueue)、单线程避免上下文切换、高效的数据结构设计以及底层优化的字符串实现。
使用 Redis 构建布隆过滤器可通过扩展模块 redis-bloom 实现,也可自行基于 Bitmap 操作模拟。主要用于判断元素是否存在,具有空间效率高、查询速度快的优点,但存在一定误判率。
Redis 最初设计为单线程主要是为了简化并发控制、避免锁竞争、提升执行效率。自 6.0 版本起引入了多线程,主要用于处理网络 I/O(读取和解析命令),而命令执行仍由主线程完成,兼顾性能与兼容性。
项目中常用的 Redis 客户端包括 Jedis、Lettuce 和 Redisson。其中 Lettuce 支持异步与响应式编程,Redisson 提供丰富的高级功能,如分布式锁、延迟队列等。
Redis 支持五种基本数据类型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)、ZSet(有序集合),以及 Stream、Bitmap、HyperLogLog 等扩展类型。
跳表(Skip List)是 Redis 实现 ZSet 的底层结构之一。它通过多层链表加速查找,平均时间复杂度为 O(log n),相比平衡树更易于实现且性能稳定。
当 Redis 出现性能瓶颈时,应从 CPU、内存、网络等方面排查。可通过 slowlog 分析慢查询、info 命令查看统计信息、优化 key 结构、拆分大 key、启用 Pipeline 或 Cluster 架构等方式优化。
Redis 的 hash 是一种键值对嵌套结构,适合存储对象属性。内部编码可能是 ziplist 或 hashtable,根据元素数量和大小自动转换。
Redis 与 Memcached 的主要区别在于:Redis 支持持久化、多种数据类型、主从复制、集群模式、Lua 脚本等,而 Memcached 仅为纯内存 KV 存储,侧重高性能与简单性。
Redis 支持简单的事务机制,通过 MULTI、EXEC、DISCARD 和 WATCH 命令实现。事务内的命令会被序列化执行,但不支持回滚,仅保证隔离性。
数据过期后的删除策略包括:惰性删除(访问时检测)、定期删除(周期性抽样清理),两者结合以平衡 CPU 与内存消耗。
Redis 提供八种内存淘汰策略,如 volatile-lru、allkeys-lru、volatile-ttl、noeviction 等,用于在内存不足时决定删除哪些键。
Lua 脚本功能允许将多条命令封装在一个脚本中原子执行,避免网络往返开销,常用于实现复杂的原子操作,如限流、分布式锁等。
Pipeline 功能允许客户端一次性发送多个命令,服务端逐条执行并返回结果,极大减少了网络延迟影响,适用于批量操作场景。
Redis 常见应用场景包括:缓存、会话存储、排行榜、计数器、消息队列、分布式锁、布隆过滤器、实时推荐等。
Big Key 问题指某个 key 对应的 value 过大(如 huge hash、large list),可能导致阻塞主线程、网络拥塞、GC 时间变长等问题。解决方案包括拆分大 key、压缩数据、使用游标遍历等。
热点 key 问题是某些 key 被极高频率访问,超出单节点承载能力。可通过本地缓存、多级缓存、key 拆分、随机前缀等方式缓解。
Redis 的持久化机制有两种:RDB(快照)和 AOF(追加日志)。RDB 定期生成二进制快照文件,恢复速度快;AOF 记录每次写操作,数据安全性更高。
缓存击穿指热点 key 失效瞬间引发大量请求直达数据库;缓存穿透指查询不存在的数据导致缓存无效;缓存雪崩指大量 key 同时失效造成数据库压力骤增。可通过互斥锁、空值缓存、随机过期时间等策略预防。
线上发现 Redis 机器负载过高时,应立即分析内存使用、连接数、慢查询、CPU 占用等情况。优化手段包括:扩容、分片、调整配置、清除无效 key、启用压缩、升级硬件等。
在生成 RDB 文件期间,Redis 主进程会 fork 出子进程进行磁盘写入,父进程继续处理请求。但由于 copy-on-write 机制,期间若发生大量写操作,可能引起内存飙升。
Redis 的哨兵机制用于实现高可用,监控主从节点状态,在主节点宕机时自动完成故障转移,选举新的主节点并通知客户端更新路由信息。
主从复制通过命令传播与全量同步实现。初次连接时进行 RDB 快照传输,后续增量数据通过网络流持续同步,保证从节点数据与主节点一致。
若发现 Redis 内存溢出,应首先使用 info memory 和 memory usage 命令定位大 key 或内存增长点,然后采取淘汰策略、清理无用数据、优化 key 设计、增加 swap 或升级内存容量等措施。
计算机网络相关问题(共 19 题)
TCP 三次握手过程如下:客户端发送 SYN=1, seq=x;服务器回应 SYN=1, ACK=1, seq=y, ack=x+1;客户端再发 ACK=1, ack=y+1,连接建立。目的是同步双方初始序列号并确认通信能力。
TCP 四次挥手过程为:主动方发送 FIN=1;被动方回应 ACK=1;待数据发送完毕后,被动方发送 FIN=1;主动方回应 ACK=1,进入 TIME_WAIT 状态等待 2MSL 后关闭。
TIME_WAIT 状态存在的意义在于:确保最后一个 ACK 能被对方接收,防止旧连接的延迟报文干扰新连接。等待时间为 2 倍最大段生命周期(MSL)。
TCP 超时重传机制用于解决数据包在网络中丢失的问题。发送方在未收到 ACK 时会重新发送数据,超时时间根据 RTT 动态调整。
滑动窗口机制用于实现流量控制与拥塞控制。接收方通过通告窗口大小告知发送方可发送的数据量,发送方据此调整发送速率,避免缓冲区溢出。
TCP/IP 四层模型包括:应用层(HTTP、FTP)、传输层(TCP、UDP)、网络层(IP、ICMP)、网络接口层(以太网、Wi-Fi)。
OSI 七层模型从下至上分别为:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。它是理论参考模型,指导网络协议设计。
从输入网址到页面显示的过程包括:DNS 解析获取 IP 地址、建立 TCP 连接、发送 HTTP 请求、服务器处理并返回响应、浏览器解析 HTML/CSS/JS、渲染页面内容。
物理地址(MAC 地址)是数据链路层使用的硬件地址,用于局域网内设备识别;逻辑地址(IP 地址)是网络层使用的地址,用于跨网络寻址。
TCP 连接是一种虚拟的端到端通信通道,由四元组(源 IP、源端口、目的 IP、目的端口)唯一标识,维持双方的状态同步与可靠传输。
HTTP 1.0 使用短连接,每次请求需重新建立 TCP 连接;HTTP 2.0 支持长连接、多路复用、头部压缩、服务器推送等功能,大幅提升性能。
HTTP 2.0 基于 TCP,仍存在队头阻塞问题;HTTP 3.0 改用 QUIC 协议,基于 UDP 实现,解决了队头阻塞,并加快连接建立速度。
HTTP 是明文传输协议,安全性差;HTTPS 在 HTTP 与 TCP 之间加入 SSL/TLS 加密层,实现数据加密、身份认证和完整性校验。
HTTP 是应用层协议,主要用于浏览器与服务器通信;RPC 是远程过程调用,强调接口级别的服务调用,常用于微服务间通信,性能更高,协议更灵活。
TCP 是面向连接、可靠的字节流协议,提供错误检测、重传、排序等机制;UDP 是无连接、不可靠的数据报协议,传输速度快,适用于实时性要求高的场景。
TCP 粘包和拆包是由于 TCP 是字节流协议,无固定消息边界所致。发送方连续发送的小包可能合并成一个接收(粘包),大包可能被拆分成多次接收(拆包)。解决方案包括定长消息、特殊分隔符、消息头+长度字段等。
Cookie 是客户端存储的小段文本,随请求发送;Session 是服务器端保存的用户状态信息,通常依赖 Cookie 传递 Session ID;Token 是无状态的身份凭证(如 JWT),可自包含用户信息,常用于前后端分离架构。
线上 CPU 使用率飙高时,可通过 top、htop 查看进程占用,使用 jstack(Java)、perf、strace 等工具分析线程栈或系统调用,定位热点代码或死循环问题,必要时结合火焰图深入剖析。
TCP 解决了哪些问题?
TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。它主要用于解决数据在不可靠网络中传输时可能出现的数据丢失、重复、乱序等问题,通过确认机制、重传机制、流量控制和拥塞控制等手段,确保数据能够完整、有序地送达目标主机。
常见的框架相关问题(17 题)
Netty 的零拷贝机制是如何实现的?
Netty 的零拷贝机制主要体现在多个层面:一是通过 CompositeByteBuf 合并缓冲区,避免内存拷贝;二是使用 FileRegion 实现文件传输中的零拷贝,直接调用操作系统的 sendfile 函数;三是利用堆外内存减少 JVM 内部 GC 压力,并避免用户空间与内核空间之间的多次数据复制。
Netty 如何处理粘包与拆包问题?
由于 TCP 是基于字节流的协议,无法自动区分消息边界,因此会出现粘包或拆包现象。Netty 提供了多种解码器来解决该问题,如 FixedLengthFrameDecoder、LineBasedFrameDecoder、DelimiterBasedFrameDecoder 和 LengthFieldBasedFrameDecoder,通过定义消息长度或分隔符来正确拆分数据包。
如何规避 JDK NIO 中的空轮询 Bug?
JDK NIO 在某些情况下会触发 Selector 无限制地返回空轮询,导致 CPU 占用过高。Netty 通过引入计数机制检测连续空轮询次数,一旦超过阈值则重建 Selector,从而规避此问题,有效降低资源消耗。
Reactor 线程模型包含哪些组成部分?
Reactor 模型是一种事件驱动的设计模式,主要包括三个核心组件:Reactor 负责监听和分发事件,Acceptor 处理新连接的建立,Handler 执行具体的 I/O 操作。根据线程分工的不同,可分为单线程、多线程以及主从 Reactor 模型,Netty 默认采用的是主从 Reactor 多线程模型。
常见的 I/O 模型有哪些?
常见的 I/O 模型包括阻塞 I/O、非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。其中,I/O 多路复用被广泛应用于高并发场景,如 Select、Poll 和 Epoll 就是其实现方式。
Select、Poll 与 Epoll 的区别是什么?
Select 使用固定大小的数组存储描述符,存在最大连接数限制且每次需遍历全部集合;Poll 使用链表结构,解决了数量限制但性能提升有限;Epoll 采用事件驱动机制,支持水平触发和边沿触发,仅通知就绪的文件描述符,适用于大规模并发连接。
Netty 的典型应用场景有哪些?
Netty 常用于构建高性能的网络服务器,如即时通讯系统、游戏后台、物联网网关、RPC 框架底层通信模块、API 网关等,因其高并发、低延迟、可扩展性强而受到青睐。
为何选择 Netty 而非原生 NIO?
虽然 JDK 自带 NIO,但其 API 复杂、易出错,且存在空轮询 Bug。Netty 在此基础上进行了高度封装,提供了更简洁的编程接口、更好的稳定性、丰富的编解码支持和完善的错误处理机制,显著降低了开发难度。
为什么 Netty 性能如此出色?
Netty 高性能的原因包括:基于 Reactor 多线程模型充分利用多核资源;采用零拷贝技术减少内存复制;使用 ByteBuf 提供高效的缓冲区管理;支持堆外内存降低 GC 压力;具备灵活的 ChannelPipeline 机制实现责任链模式,便于扩展。
MyBatis 插件的工作原理是什么?如何自定义插件?
MyBatis 插件基于拦截器设计模式,通过实现 Interceptor 接口并配合 @Signature 注解指定拦截的目标方法(如 Executor、StatementHandler 等),可在 SQL 执行前后插入逻辑。编写插件时需注册到 Configuration 中,或通过 XML 或注解方式加载。
MyBatis 的缓存机制是怎样的?
MyBatis 提供一级缓存和二级缓存。一级缓存默认开启,作用于 SqlSession 级别,同一个会话中查询结果会被缓存;二级缓存作用于 Mapper Namespace 级别,多个会话间共享,需手动启用并要求返回对象可序列化。
#{} 和 ${} 在 MyBatis 中有何区别?
#{} 是预编译处理,将参数作为占位符传递给 PreparedStatement,防止 SQL 注入,安全性更高;${} 是字符串替换,直接拼接进 SQL 语句,适用于动态表名或排序字段,但存在注入风险,需谨慎使用。
MyBatis 与 Hibernate 的主要差异是什么?
MyBatis 是半自动化的 ORM 框架,需要手动编写 SQL,灵活性高,适合复杂查询和性能优化;Hibernate 是全自动 ORM,提供 HQL 和对象映射,开发效率高,但对 SQL 控制较弱,学习成本较高。
什么是 MyBatis-Plus?它的优势是什么?
MyBatis-Plus 是 MyBatis 的增强工具,简化 CRUD 操作,内置通用 Mapper 和 Service,支持 Lambda 表达式、分页插件、性能分析等功能,在不改变原有特性的基础上提升了开发效率。
Dubbo 与 Spring Cloud Gateway 的区别是什么?
Dubbo 是一款高性能的 Java RPC 框架,侧重于服务间的远程调用,常用于内部微服务通信;Spring Cloud Gateway 是 API 网关,主要用于请求路由、过滤、限流等外部访问控制,属于微服务体系中的入口层组件。
什么是 API 网关?它的功能有哪些?
API 网关是微服务架构中的统一入口,负责请求路由、认证鉴权、限流熔断、日志监控、协议转换等功能,屏蔽后端服务细节,提升系统安全性和可维护性。
Seata 是什么?
Seata 是一款开源的分布式事务解决方案,提供 AT(自动补偿)、TCC、SAGA 和 XA 四种模式,致力于在微服务环境下实现高效、透明的事务一致性。
分布式相关面试题(13 题)
何时需要使用分布式事务?有哪些常见方案?
当业务操作涉及多个数据库或服务节点,且要求整体原子性时,必须使用分布式事务。常见解决方案包括两阶段提交(2PC)、三阶段提交(3PC)、TCC 模式、基于消息队列的最终一致性、Seata 提供的 AT 模式等。
如何设计一个秒杀系统?
设计秒杀系统需考虑高并发下的性能与一致性问题。关键措施包括:前端限流与验证码校验、Redis 预减库存、MQ 异步下单、数据库分库分表、热点数据缓存、防止超卖与刷单机制,同时结合降级与熔断保障系统稳定。
如何设计一个分布式 ID 生成器?
分布式 ID 生成器需满足全局唯一、趋势递增、高性能、高可用等特性。常用方案有:Snowflake 算法(时间戳+机器ID+序列号)、UUID(无需中心节点但无序)、数据库自增主键(需加锁影响性能)、Redis INCR(依赖中间件)等,可根据实际场景组合使用。
短链系统的设计思路是什么?
短链系统的核心是将长 URL 映射为短字符串。常见做法是使用哈希算法(如 MD5)取摘要后编码(Base62),或采用发号器生成自增 ID 再转为短字符。需考虑冲突处理、缓存加速访问、持久化存储映射关系,并支持跳转统计与过期机制。
分布式锁的实现方式有哪些?
常见的分布式锁实现包括基于 Redis 的 SETNX + EXPIRE 方案、Redlock 算法、ZooKeeper 的临时顺序节点、数据库唯一索引等。选择时需权衡性能、可靠性与复杂度,推荐使用 Redisson 或 Curator 等成熟框架。
点赞系统的架构该如何设计?
点赞系统需应对高频读写。通常使用 Redis 存储用户点赞状态(如 Set 或 Bitmap 结构),定期异步同步至数据库;支持取消点赞、统计总数、查看是否已点等功能;对于热点内容可采用分片策略防止单点压力过大。
如何设计一个简单的 RPC 框架?
一个基础的 RPC 框架应包含服务注册与发现、序列化协议、网络通信(如 Netty)、负载均衡、容错机制等模块。客户端通过动态代理发起调用,服务端接收请求并反射执行目标方法,结果返回给调用方,整个过程对用户透明。
什么是限流?常见的限流算法有哪些?
限流用于保护系统免受突发流量冲击,防止资源耗尽。常见算法包括:计数器(固定窗口)、滑动窗口、漏桶算法(恒定速率处理)、令牌桶算法(允许一定突发流量)。其中令牌桶应用最广,如 Guava RateLimiter 即基于此实现。
常用的负载均衡算法有哪些?
常见的负载均衡算法有:轮询、加权轮询、随机、加权随机、最少连接数、源地址哈希、响应时间优先等。可在客户端(如 Ribbon)或服务端(如 Nginx)实现,依据实际需求选择合适策略。
分布式与微服务的区别是什么?
分布式强调系统拆分后部署在不同节点上,侧重物理分布与资源共享;微服务是一种架构风格,将单一应用划分为多个小型服务,每个服务独立部署、运行和演进,强调松耦合与自治性,通常基于分布式技术实现。
什么是服务熔断?
服务熔断是一种容错机制,当某个服务出现故障或响应超时时,停止对该服务的调用一段时间,快速失败并返回默认响应,防止故障扩散,待恢复后再尝试调用,类似于电路保险丝的作用。
什么是服务降级?
服务降级是在系统压力过大或部分功能异常时,暂时关闭非核心功能,保障主流程可用,例如关闭推荐、评论等功能,确保下单、支付等关键路径正常运行,属于牺牲局部保全整体的策略。
什么是服务雪崩?
服务雪崩是指一个服务的故障引发连锁反应,导致整个系统不可用。通常由大量请求阻塞线程池、数据库连接耗尽等原因引起。可通过熔断、降级、限流、隔离等手段预防。
总结
由于篇幅限制,本文仅挑选了一些高频且重要的面试题目进行展示。这些题目并非固定不变,仅供学习参考。重点在于积累扎实的技术储备,做到有备无患。面试前进行充分准备和模拟练习非常必要,既能提升表达能力,也能节省自己与面试官的时间。

 京公网安备 11010802022788号
京公网安备 11010802022788号







